
你的c++团队还在禁用异常处理吗?
点击左上方蓝字关注我们

什么是异常处理?
异常处理当然指的是对异常的处理,异常是指程序在执行期间产生的问题,没有按正确设想的流程走下去,比如除以零的操作,异常处理提供了一种转移程序控制权的方式,这里涉及到三个关键字:
throw:当问题出现时,程序会通过throw来抛出一个异常
catch:在可能有throw想要处理问题的地方,通过catch关键字来捕获异常
try:try块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个catch块
直接看示例代码:
void func() {throw exception; // 抛出异常}int main() {try { // try里放置可能抛出异常的代码,块中的代码被称为保护代码func();} catch (exception1& e) { // 捕获异常,异常类型为exception1// code} catch (exception2& e) { // 捕获异常,异常类型为exception2// code} catch (...) {// code}return 0;}
c++标准都有什么异常?
C++ 提供了一系列标准的异常,定义在<exception> 中,我们可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来的,如下所示:
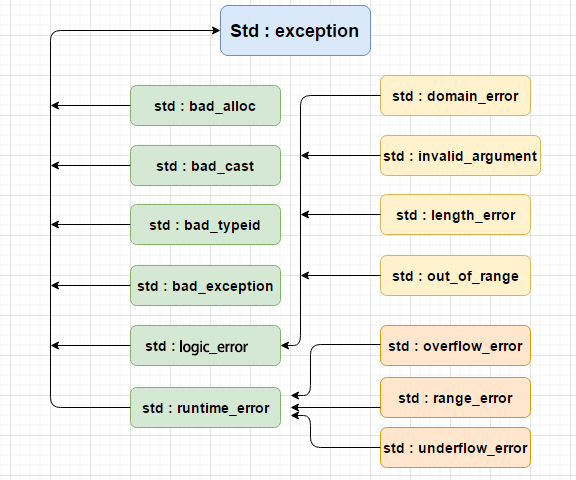
图片来自菜鸟教程
具体异常应该不需要特别介绍了吧,看英文名字就可以知道大概意思。
自定义异常
可以通过继承和重载exception类来自定义异常,见代码:
class MyException : public std::runtime_error {public:MyException() : std::runtime_error("MyException") { }};void f(){// ...throw MyException();}int main() {try {f();} catch (MyException& e) {// ...} catch (...) {}return 0;}
我们应该使用异常吗?
在c++中关于是否使用异常一直都有争议,典型的就是知乎上陈硕大神说的不应该使用异常,还有就是google和美国国防部等都明确定义编码规范来禁止在c++中使用异常,这里我找了很多中英文资料,在文末参考链接列举了一些。
关于是否使用异常的讨论帖子在这,https://www.zhihu.com/question/22889420
陈硕大神说的什么我就不贴出来了,他水平之高无需置疑,但他说的一些东西还是很有争议的,关于异常处理,引用吴咏炜老师的一句话:“陈硕当然是个技术大牛。不过,在编程语言这件事上,我更愿意信任 Bjarne Stroustrup、Herb Sutter、Scott Meyers 和 Andrei Alexandrescu。这些大神们都认为异常是比返回错误码更好的错误处理方式。”
而google明确禁用异常其实是有历史包袱的,他们也认同异常处理是比错误码更好的处理方式,但他们别无选择,因为以前的编译器对异常处理的不好,他们项目里面已经有了大量的非异常安全的代码,如果全改成异常处理的代码是有很大的工作量的,具体可以看上面的链接和我文末引用的一些链接。
美国国防部禁用异常是出于实时性能考虑,工具链不能保证程序抛出异常时的实时性能,但国防部禁用了很多c++特性,例如内存分配,我们真的追求飞机一样的高性能吗?
通过上面的介绍大家应该能猜到我的结论了吧,当然这不是我的结论,而是大佬们的结论:推荐使用异常处理。
异常处理有一些潜在的缺点:
会有限的影响程序的性能,但正常工作流中不抛出异常的时候速度和普通函数一样快,甚至更快
会导致程序体积变大10%-20%,但我们真的那么在乎程序的体积吗(除了移动端)
异常处理相对于使用错误码的好处:
如果不使用trycatch那就需要使用返回错误码的方式,那就必然增加ifelse语句,每次函数返回后都会增加判断的开销,如果可以消除trycatch,代码可能会更健壮,举例如下:
void f1(){try {// ...f2();// ...} catch (some_exception& e) {// ...code that handles the error...}}void f2() { ...; f3(); ...; }void f3() { ...; f4(); ...; }void f4() { ...; f5(); ...; }void f5() { ...; f6(); ...; }void f6() { ...; f7(); ...; }void f7() { ...; f8(); ...; }void f8() { ...; f9(); ...; }void f9() { ...; f10(); ...; }void f10(){// ...if ( /*...some error condition...*/ )throw some_exception();// ...}
而使用错误码方式:
int f1(){// ...int rc = f2();if (rc == 0) {// ...} else {// ...code that handles the error...}}int f2(){// ...int rc = f3();if (rc != 0)return rc;// ...return 0;}int f3(){// ...int rc = f4();if (rc != 0)return rc;// ...return 0;}int f4(){// ...int rc = f5();if (rc != 0)return rc;// ...return 0;}int f5(){// ...int rc = f6();if (rc != 0)return rc;// ...return 0;}int f6(){// ...int rc = f7();if (rc != 0)return rc;// ...return 0;}int f7(){// ...int rc = f8();if (rc != 0)return rc;// ...return 0;}int f8(){// ...int rc = f9();if (rc != 0)return rc;// ...return 0;}int f9(){// ...int rc = f10();if (rc != 0)return rc;// ...return 0;}int f10(){// ...if (...some error condition...)return some_nonzero_error_code;// ...return 0;}
错误码方式对于问题的反向传递很麻烦,导致代码肿胀,假如中间有一个环节忘记处理或处理有误就会导致bug的产生,异常处理对于错误的处理更简洁,可以更方便的把错误信息反馈给调用者,同时不需要调用者使用额外的ifelse分支来处理成功或者不成功的情况。
一般来说使用错误码方式标明函数是否成功执行,一个值标明函数成功执行,另外一个或者多个值标明函数执行失败,不同的错误码标明不同的错误类型,调用者需要对不同的错误类型使用多个ifelse分支来处理。如果有更多ifelse,那么必然写出更多测试用例,必然花费更多精力,导致项目晚上线。
拿数值运算代码举例:
class Number {public:friend Number operator+ (const Number& x, const Number& y);friend Number operator- (const Number& x, const Number& y);friend Number operator* (const Number& x, const Number& y);friend Number operator/ (const Number& x, const Number& y);// ...};
最简单的可以这样调用:
void f(Number x, Number y) {// ...Number sum = x + y;Number diff = x - y;Number prod = x * y;Number quot = x / y;// ...}
但是如果需要处理错误,例如除0或者数值溢出等,函数得到的就是错误的结果,调用者需要做处理。
先看使用错误码的方式:
class Number {public:enum ReturnCode {Success,Overflow,Underflow,DivideByZero};Number add(const Number& y, ReturnCode& rc) const;Number sub(const Number& y, ReturnCode& rc) const;Number mul(const Number& y, ReturnCode& rc) const;Number div(const Number& y, ReturnCode& rc) const;// ...};int f(Number x, Number y){// ...Number::ReturnCode rc;Number sum = x.add(y, rc);if (rc == Number::Overflow) {// ...code that handles overflow...return -1;} else if (rc == Number::Underflow) {// ...code that handles underflow...return -1;} else if (rc == Number::DivideByZero) {// ...code that handles divide-by-zero...return -1;}Number diff = x.sub(y, rc);if (rc == Number::Overflow) {// ...code that handles overflow...return -1;} else if (rc == Number::Underflow) {// ...code that handles underflow...return -1;} else if (rc == Number::DivideByZero) {// ...code that handles divide-by-zero...return -1;}Number prod = x.mul(y, rc);if (rc == Number::Overflow) {// ...code that handles overflow...return -1;} else if (rc == Number::Underflow) {// ...code that handles underflow...return -1;} else if (rc == Number::DivideByZero) {// ...code that handles divide-by-zero...return -1;}Number quot = x.div(y, rc);if (rc == Number::Overflow) {// ...code that handles overflow...return -1;} else if (rc == Number::Underflow) {// ...code that handles underflow...return -1;} else if (rc == Number::DivideByZero) {// ...code that handles divide-by-zero...return -1;}// ...}
再看使用异常处理的方式:
void f(Number x, Number y){try {// ...Number sum = x + y;Number diff = x - y;Number prod = x * y;Number quot = x / y;// ...}catch (Number::Overflow& exception) {// ...code that handles overflow...}catch (Number::Underflow& exception) {// ...code that handles underflow...}catch (Number::DivideByZero& exception) {// ...code that handles divide-by-zero...}}
如果有更多的运算,或者有更多的错误码,异常处理的优势会更明显。
使用异常可以使得代码逻辑更清晰,将代码按正确的逻辑列出来,逻辑更紧密代码更容易读懂,而错误处理可以单独放到最后做处理。
异常可以选择自己处理或者传递给上层处理
异常处理的关键点
不应该使用异常处理做什么?
throw仅用于抛出一个错误,标识函数没有按设想的方式去执行
只有在知道可以处理错误时,才使用catch来捕获错误,例如转换类型或者内存分配失败
不要使用throw来抛出编码错误,应该使用assert或者其它方法告诉编译器或者崩溃进程收集debug信息
如果有必须要崩溃的事件,或者无法恢复的问题,不应该使用throw抛出,因为抛出来外部也无法处理,就应该让程序崩溃
try、catch不应该简单的用于函数返回值,函数的返回值应该使用return操作,不应该使用catch,这会给编程人员带来误解,同时也不应该用异常来跳出循环
构造函数可以抛出异常吗?可以而且建议使用异常,因为构造函数没有返回值,所以只能抛出异常,也有另一种办法就是添加一个成员变量标识对象是否构造成功,这种方法那就会额外添加一个返回该返回值的函数,如果定义一个对象数组那就需要对数组每个对象都判断是否构造成功,这种代码不太好。
构造函数抛出异常会产生内存泄漏吗?不会,构造函数抛出异常产生内存泄漏那是编译器的bug,已经在21世纪修复,不要听信谣言。
void f() {X x; // If X::X() throws, the memory for x itself will not leakY* p = new Y(); // If Y::Y() throws, the memory for *p itself will not leak}永远不要在析构函数中把异常抛出,还是拿对象数组举例,数组里有多个对象,如果其中一个对象析构过程中抛出异常,会导致剩余的对象都无法被析构,析构函数应该捕获异常并把他们吞下或者终止程序,而不是抛出。
构造函数内申请完资源后抛出异常怎么办?使用智能指针,关于char*也可以使用std::string代替。
using namespace std;class SPResourceClass {private:shared_ptr<int> m_p;shared_ptr<float> m_q;public:SPResourceClass() : m_p(new int), m_q(new float) { }// Implicitly defined dtor is OK for these members,// shared_ptr will clean up and avoid leaks regardless.};永远通过值传递方式用throw抛出异常,通过引用传递用catch来捕获异常。
可以抛出基本类型也可以抛出对象,啥都可以
catch(...)可以捕获所有异常
catch过程中不会触发隐式类型转换
异常被抛出,但是直到main函数也没有被catch,就会std::terminate()
c++不像java,不会强制检查异常,throw了外层即使没有catch也会编译通过
异常被抛出时,在catch之前,try和throw之间的所有局部对象都会被析构
如果一个成员函数不会产生任何异常,可以使用noexcept关键字修饰
通过throw可以重新抛出异常
异常处理看似简单好用,但它需要项目成员严格遵守开发规范,定好什么时候使用异常,什么时候不使用,而不是既使用异常又使用错误码方式。
int main(){try {try {throw 20;}catch (int n) {cout << "Handle Partially ";throw; //Re-throwing an exception}}catch (int n) {cout << "Handle remaining ";}return 0;}
小测验
你真的理解异常处理了吗,我们可以做几道测验题:
看这几段代码会输出什么:
测试代码1:
using namespace std;int main(){int x = -1;// Some codecout << "Before try \n";try {cout << "Inside try \n";if (x < 0){throw x;cout << "After throw (Never executed) \n";}}catch (int x ) {cout << "Exception Caught \n";}cout << "After catch (Will be executed) \n";return 0;}
输出:
Before tryInside tryException CaughtAfter catch (Will be executed)
throw后面的代码不会被执行
测试代码2:
using namespace std;int main(){try {throw 10;}catch (char *excp) {cout << "Caught " << excp;}catch (...) {cout << "Default Exception\n";}return 0;}
输出:
Default Exceptionthrow出来的10首先没有匹配char*,而catch(...)可以捕获所有异常。
测试代码3:
using namespace std;int main(){try {throw 'a';}catch (int x) {cout << "Caught " << x;}catch (...) {cout << "Default Exception\n";}return 0;}
输出:
Default Exception'a'是字符,不能隐式转换为int型,所以还是匹配到了...中。
测试代码4:
using namespace std;int main(){try {throw 'a';}catch (int x) {cout << "Caught ";}return 0;}
程序崩溃,因为抛出的异常直到main函数也没有被捕获,std::terminate()就会被调用来终止程序。
测试代码5:
using namespace std;int main(){try {try {throw 20;}catch (int n) {cout << "Handle Partially ";throw; //Re-throwing an exception}}catch (int n) {cout << "Handle remaining ";}return 0;}
输出:
Handle Partially Handle remainingcatch中的throw会重新抛出异常。
测试代码6:
using namespace std;class Test {public:Test() { cout << "Constructor of Test " << endl; }~Test() { cout << "Destructor of Test " << endl; }};int main() {try {Test t1;throw 10;} catch(int i) {cout << "Caught " << i << endl;}}
输出:
Constructor of TestDestructor of TestCaught 10
在抛出异常被捕获之前,try和throw中的局部变量会被析构。
小总结
异常处理对于错误的处理更简洁,可以更方便的把错误信息反馈给调用者,同时不需要调用者使用额外的ifelse分支来处理成功或者不成功的情况。如果不是特别特别注重实时性能或者特别在乎程序的体积我们完全可以使用异常处理替代我们平时使用的c语言中的那种错误码处理方式。
关于c++的异常处理就介绍到这里,你都了解了吗?大家有问题可以
参考资料
https://www.zhihu.com/question/22889420
https://isocpp.org/wiki/faq/
https://docs.microsoft.com/en-us/cpp/cpp/errors-and-exception-handling-modern-cpp?view=vs-2019
https://blog.csdn.net/zhangyifei216/article/details/50410314
https://www.runoob.com/cplusplus/cpp-exceptions-handling.html
https://www.geeksforgeeks.org/exception-handling-c/
END
整理不易,点赞三连↓