
Python 爬虫进阶必备 | 某工业超市加密 header 参数分析
今日网站
aHR0cHM6Ly93ZWIuemtoMzYwLmNvbS9saXN0L2MtMjYwMTg2Lmh0bWw/c2hvd1R5cGU9cGljJmNscD0x
这个网站是在某交流群看到的,随手保存下来作为今天的素材
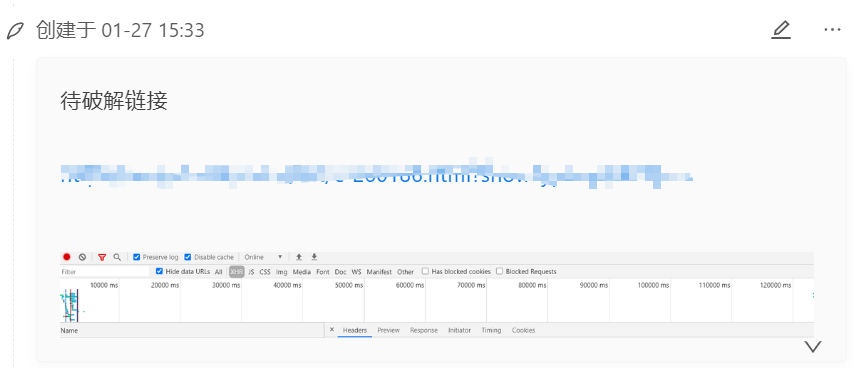
抓包分析与加密定位
先看看抓包的结果,可以看到请求的header中包含两个未知的参数,分别是zkhs和zkhst

进一步检索参数zkhst和zkhs,可以发现这两个参数的值没有做过混淆
并且都有对应的搜索结果


根据搜索结果的提示inde,进一步在文件中检索zkhst和zkhs
可以在文件中找到下面这几个关键位置
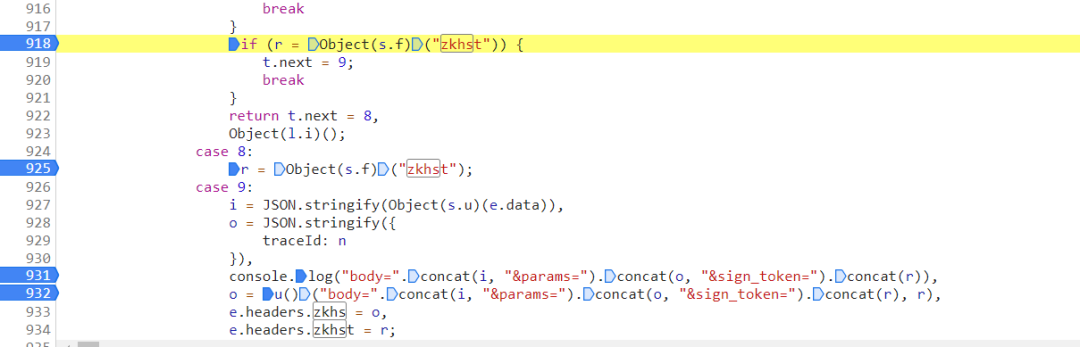
加密分析
在逻辑里比较明显的是
e.headers.zkhs = o,e.headers.zkhst = r
这行代码预示我们要分析的是o和r这两个变量
这两个变量的赋值分别可以在上面的 js 逻辑中找到
o = u()("body=".concat(i, "¶ms=").concat(o, "&sign_token=").concat(r), r)
r = Object(s.f)("zkhst")
接下来只要单点调试即可,先来看o的生成
o的逻辑是将所有的参数拼接,传入u()中计算
这里的参数是一个逗号表达式,最后得到的传入参数是r
r = ("body=".concat(i, "¶ms=").concat(o, "&sign_token=").concat(r)
这里较为明显的未知参数是body以及sign_token
可以通过断点分析得到下面的结果,这个结果就是计算后的r
body={"brandId":"","catalogueId":"260186","cityCode":350100,"clp":true,"extraFilter":{"inStock":false,"showIndustryFeatured":false},"from":0,"fz":false,"keyword":"","productFilter":{"brandIds":[""],"properties":{}},"rangeFilter":null,"searchType":{"notNeedCorrect":false},"size":20,"sort":0}¶ms={"traceId":"213681131613962067063"}&sign_token=799c9842f09c490196047064e10dead8
网站的开发很贴心了,还在逻辑里加了console.log

body和parmas都是查询参数,body中包含了城市信息之类的内容,这个需要根据要爬取的内容修改
除此之外还有sign_token未知,这个就是另一个要分析的参数zkhst
zkhst 获取
经过调试得到下面这个结果,在定位的js中有一个switch控制流
在918行,会进行一次判断,如果r = Object(s.f)("zkhst")没有获取到值,会进入到Object(l.i)();这个逻辑。如果有值会break进入926行的逻辑。
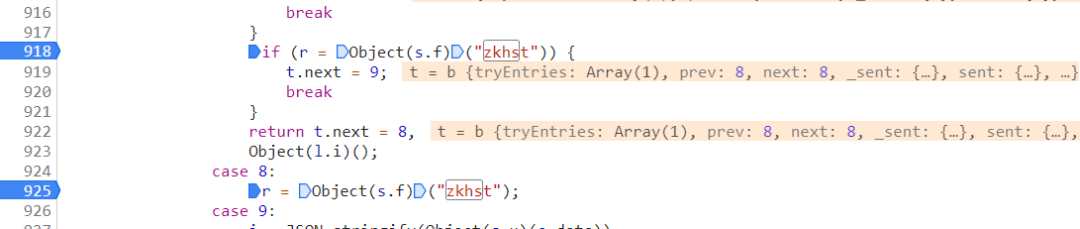
所以需要先把Object(s.f)("zkhst")的值变为undefinde,进入s.f中,可以看到下面这段逻辑
h = function(t) {
t = document.cookie.match(new RegExp("(^| )".concat(t, "=([^;]*)(;|$)")));
return null != t ? decodeURIComponent(t[2]) : null
}
可以得到zkhst是从cookie中得出的,直接清除cookie中的zkhst就能进入生成的逻辑
所以清除浏览器缓存/cookie
顺利进入(l.i)(),可以看到下面这串逻辑
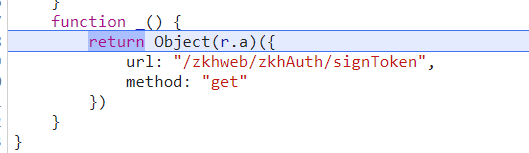
并且在network中也的到印证
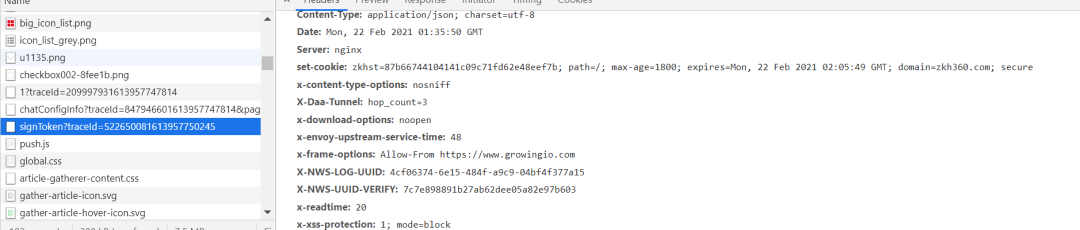
这个zkhst是由页面请求返回得到的。
至此两个加密参数均已得到,就可以获取页面的数据了。
好了,今天的文章就到这里了,我们下次再会~
有知有行
[ 完 ]
对了,看完记得一键四连,这个对我真的很重要。