
Transformer走下神坛?南加州大学教授:想解决常识问题,神经网络不是答案
七月在线实验室
共 3658字,需浏览 8分钟
·
2021-09-03 12:40

【导读】NLP研究人员都知道语言模型只能学到语法上下文信息,对于常识性问题则束手无措。南加州大学的一名助理教授最近做客《对话》,阐述了他眼中的常识以及解决方法。他悲观地预测,也许5年、50年才能解决,到底需要多久,没人知道。

常识的定义

参考资料:
https://www.nextgov.com/ideas/2021/08/ai-expert-explains-why-its-hard-give-computers-something-you-take-granted-common-sense/184583/
本文素材来源于网络,如有侵权,联系删除!
— 推荐阅读 — NLP ( 自然语言处理 )

CV(计算机视觉)
推荐
最新大厂面试题
AI开源项目论文
— 今日学习推荐 —
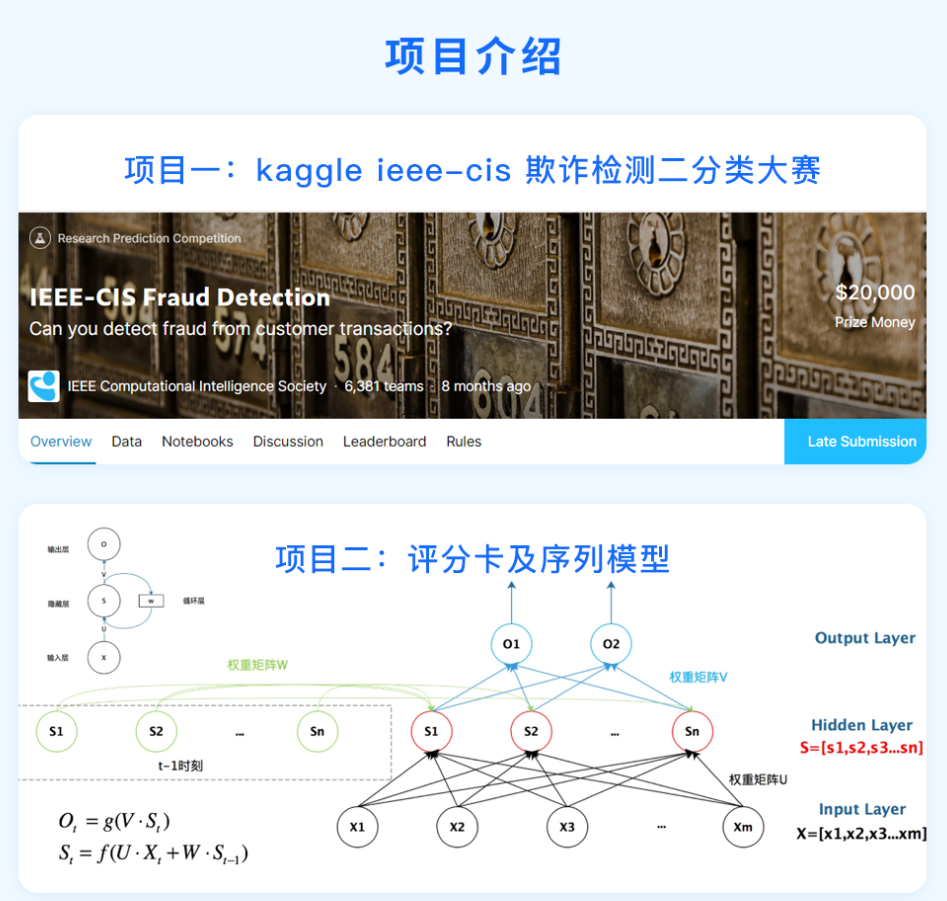
今天给大家一个超棒的课程福利——【金融欺诈比赛与序列模型】特训课程!限时1分秒杀!
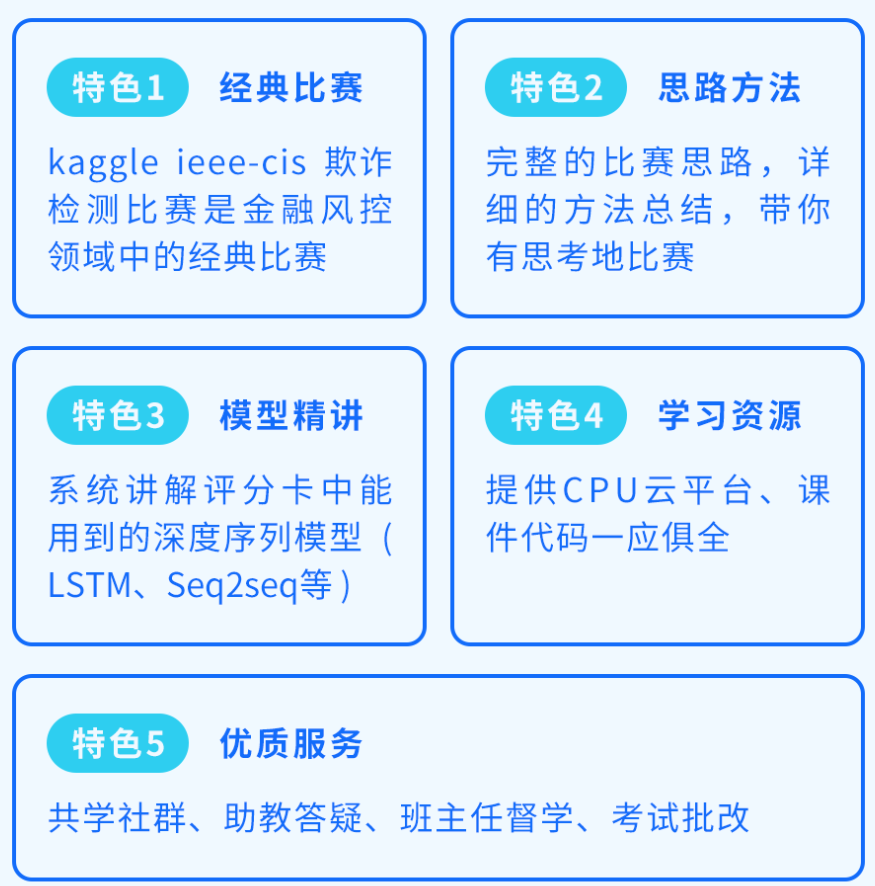
本课从kaggle欺诈比赛和序列模型两个角度带你深入了解金融风控领域知识! kaggle欺诈比赛中:会从比赛背景知识介绍、效率优化,到数据分析、特征工程,再到模型分析、超参数调优,给你一个参赛必备整体思路; 序列模型中:会从RNN、LSTM、GRU,到Seq2seq、Attention,再到Transformer及案例,带你充分了解金融风控领域中需要掌握的序列模型。
课程配备优秀讲师和助教团队跟踪辅导、答疑,班主任督促学习,群内学员一起学习,对抗惰性。同时课程还配备专业职业规划老师,为你的求职规划,涨薪跳槽保驾护航。
戳↓↓“阅读原文”立即1分秒杀【金融欺诈比赛与序列模型】课程!


评论