
设计一个插件架构,我是如何思考的
点击上方 前端瓶子君,关注公众号
回复算法,加入前端编程面试算法每日一题群

来源:ES2049
https://juejin.cn/post/6962102171923906596
引子
大家可能不知道,鄙人之前人送外号“过度设计”。作为一个自信的研发人员,我总是希望我开发的系统可以解决之后所有的问题,用一套抽象可以覆盖之后所有的扩展场景。当然最终往往能够证明我的愚昧与思虑不足。先知曾说过“当一个东西什么都可以做时,他往往什么都做不了”。过度的抽象,过度的开放性,往往让接触他的人无所适从。讲到这里你可能以为我要开始讲过度设计这个主题了,但其实不然,我只是想以这个话题作为引子,和大家讨论一下关于设计一个插件架构我是如何思考的。

为什么需要插件
我们的软件系统往往是要面向持续性的迭代的,在开发之初很难把所有需要支持的功能都想清楚,有时候还需要借助社区的力量去持续生产新的功能点,或者优化已有的功能。这就需要我们的软件系统具备一定的可扩展性。插件模式就是我们常常选用的方法。
事实上,现存的大量软件系统或工具都是使用插件方式来实现可扩展性的。比如大家最熟悉的小可爱——VSCode,其插件拥有量已经超越了他的前辈 Atom,发布到市场中的数量目前是 24894 个。这些插件帮助我们定制编辑器的外观或行为,增加额外功能,支持更多语法类型,大大提升了开发效率,同时也不断拓展着自身的用户群体。又或者是我们熟知的浏览器 Chrome,其核心竞争力之一也是丰富的插件市场,使其不论是对开发者还是普通使用者都已成为了不可获取的一个工具。另外还有 Webpack、Nginx 等等各种工具,这边就不一一赘述了。
根据目前各个系统的插件设计,总结下来,我们创造插件主要是帮助我们解决以下两种类型的问题:
为系统提供全新的能力 对系统现有能力进行定制
同时,在解决上面这类问题的时候做到:
插件代码与系统代码在工程上解耦,可以独立开发,并对开发者隔离框架内部逻辑的复杂度 可动态化引入与配置
并且进一步地可以实现:
通过对多个单一职责的插件进行组合,可以实现多种复杂逻辑,实现逻辑在复杂场景中的复用
这里提到的不管是提供新能力,还是进行能力定制,都既可以针对系统开发者本身,也可以针对三方开发者。
结合上面的特征,我们尝试简单描述一下插件是什么吧。插件一般是可独立完成某个或一系列功能的模块。一个插件是否引入一定不会影响系统原本的正常运行(除非他和另一个插件存在依赖关系)。插件在运行时被引入系统,由系统控制调度。一个系统可以存在复数个插件,这些插件可通过系统预定的方式进行组合。
怎么实现插件模式
插件模式本质是一种设计思想,并没有一个一成不变或者是万金油的实现。但我们经过长期的代码实践,其实已经可以总结出一套方法论来指导插件体系的实现,并且其中的一些实现细节是存在社区认可度比较高的“最佳实践”的。本文在攥写过程中也参考研读了社区比较有名的一些项目的插件模式设计,包括但不仅限于 Koa、Webpack、Babel 等。
1. 解决问题前首先要定义问题
实现一套插件模式的第一步,永远都是先定义出你需要插件化来帮助你解决的问题是什么。这往往是具体问题具体分析的,并总是需要你对当前系统的能力做一定程度的抽象。比如 Babel,他的核心功能是将一种语言的代码转化为另一种语言的代码,他面临的问题就是,他无法在设计时就穷举语法类型,也不了解应该如何去转换一种新的语法,因此需要提供相应的扩展方式。为此,他将自己的整体流程抽象成了 parse、transform、generate 三个步骤,并主要面向 parse 和 transform 提供了插件方式做扩展性支持。在 parse 这层,他核心要解决的问题是怎么去做分词,怎么去做词义语法的理解。在 transform 这层要做的则是,针对特定的语法树结构,应该如何转换成已知的语法树结构。
很明显,babel 他很清楚地定义了 parse 和 transform 两层的插件要完成的事情。当然也有人可能会说,为什么我一定要定义清楚问题呢,插件体系本来就是为未来的不确定性服务的。这样的说法对,也不对。计算机程序永远是面向确定性的,我们需要有明确的输入格式,明确的输出格式,明确的可以依赖的能力。解决问题一定是在已知的一个框架内的。这就引出了定义问题的一门艺术——如何赋予不确定以确定性,在不确定中寻找确定。说人话,就是“抽象”,这也是为什么最开始我会以过度设计作为引子。
我在进行问题定义的时候,最常使用的是样本分析法,这种方法并非捷径,但总归是有点效的。样本分析法,就是先着眼于整理已知待解决的问题,将这些问题作为样本尝试分类和提取共性,从而形成一套抽象模式。然后再通过一些不确定但可能未来待解决的问题来测试,是否存在无法套用的情况。光说无用,下面我们还是以 babel 来举个栗子,当然 babel 的抽象设计其实本质就是有理论支撑的,在有现有理论已经为你做好抽象时,还是尽量用现成的就好啦。
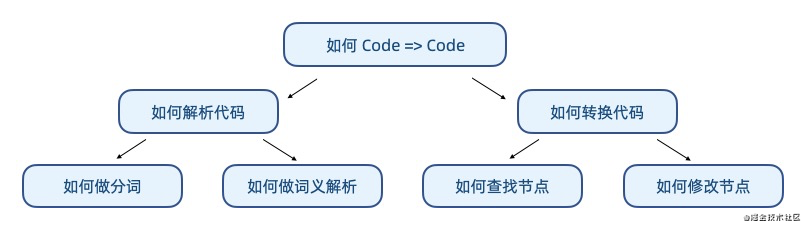
Babel 主要解决的问题是把新语法的代码在不改变逻辑的情况下如何转换成旧语法的代码,简单来说就是 code => code 的一个问题。但是需要转什么,怎么转,这些是会随着语法规范不断更新变化的,因此需要使用插件模式来提升其未来可拓展性。我们当下要解决的问题也许是如何转换 es6 新语法的内容,以及 JSX 这种框架定制的 DSL。我们当然可以简单地串联一系列的正则处理,但是你会发现每一个插件都会有大量重复的识别分析类逻辑,不但加大了运行开销,同时也很难避免互相影响导致的问题。Babel 选择了把解析与转换两个动作拆开来,分别使用插件来实现。解析的插件要解决的问题是如何解析代码,把 Code 转化为 AST。这个问题对于不同的语言又可以拆解为相同的两个事情,如何分词,以及如何做词义解析。当然词义解析还能是如何构筑上下文、如何产出 AST 节点等等,就不再细分了。最终形成的就是下图这样的模式,插件专注解决这几个细分问题。转换这边的,则可分为如何查找固定 AST 节点,以及如何转换,最终形成了 Visitor 模式,这里就不再详细说了。那么我们再思考一下,如果未来 ES7、8、9(相对于设计场景的未来)等新语法出炉时,是不是依然可以使用这样的模式去解决问题呢?看起来是可行的。
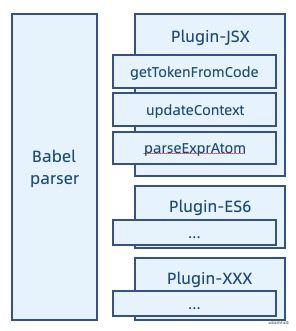
这就是前面所说的在不确定中寻找确定性,尽可能减少系统本身所面临的不确定,通过拆解问题去限定问题。
那么定义清楚问题,我们大概就完成了 1/3 的工作了,下面就是要正式开始思考如何设计了。
2. 插件架构设计绕不开的几大要素
插件模式的设计,可以简单也可以复杂,我们不能指望一套插件模式适合所有的场景,如果真的可以的话,我也不用写这篇文章了,给大家甩一个 npm 地址就完事了。这也是为什么在设计之前我们一定要先定义清楚问题。具体选择什么方式实现,一定是根据具体解决的问题权衡得出的。不过呢,这事终归还是有迹可循,有法可依的。
当正式开始设计我们的插件架构时,我们所要思考的问题往往离不开以下几点。整个设计过程其实就是为每一点选择合适的方案,最后形成一套插件体系。这几点分别是:
如何注入、配置、初始化插件 插件如何影响系统 插件输入输出的含义与可以使用的能力 复数个插件之间的关系是怎么样的
下面就针对每个点详细解释一下
如何注入、配置、初始化插件
注入、配置、初始化其实是几个分开的事情。但都同属于 Before 的事情,所以就放在一起讲了。
先来讲一讲注入,其实本质上就是如何让系统感知到插件的存在。注入的方式一般可以分为 声明式 和 编程式。声明式就是通过配置信息,告诉系统应该去哪里去取什么插件,系统运行时会按照约定与配置去加载对应的插件。类似 Babel,可以通过在配置文件中填写插件名称,运行时就会去 modules 目录下去查找对应的插件并加载。编程式的就是系统提供某种注册 API,开发者通过将插件传入 API 中来完成注册。两种对比的话,声明式主要适合自己单独启动不用接入另一个软件系统的场景,这种情况一般使用编程式进行定制的话成本会比较高,但是相对的,对于插件命名和发布渠道都会有一些限制。编程式则适合于需要在开发中被引入一个外部系统的情况。当然也可以两种方式都进行支持。
然后是插件配置,配置的主要目的是实现插件的可定制,因为一个插件在不同使用场景下,可能对于其行为需要做一些微调,这时候如果每个场景都去做一个单独的插件那就有点小题大作了。配置信息一般在注入时一起传入,很少会支持注入后再进行重新配置。配置如何生效其实也和插件初始化的有点关联,初始化这事可以分为方式和时机两个细节来讲,我们先讲讲方式。常见的方式我大概列举两种。一种是工厂模式,一个插件暴露出来的是一个工厂函数,由调用者或者插件架构来将提供配置信息传入,生成插件实例。另一种是运行时传入,插件架构在调度插件时会通过约定的上下文把配置信息给到插件。工厂模式咱们继续拿 babel 来举例吧。
function declare<
O extends Record<string, any>,
R extends babel.PluginObj = babel.PluginObj
>(
builder: (api: BabelAPI, options: O, dirname: string) => R,
): (api: object, options: O | null | undefined, dirname: string) => R;
复制代码
上面代码中的 builder 呢就是我们说到的工厂函数了,他最终将产出一个 Plugin 实例。builder 通过 options 获取到配置信息,并且这里设计上还支持通过 api 设置一些运行环境信息,不过这并不是必须的,所以不细说了。简化一下就是:
type TPluginFactory<OPTIONS, PLUGIN> = (options: OPTIONS) => PLUGIN;
复制代码
所以初始化呢,自然也可以是通过调用工厂函数初始化、初始化完成后再注入、不需要初始化三种。一般我们不选择初始化完成后再注入,因为解耦的诉求,我们尽量在插件中只做声明。是否使用工厂模式则看插件是否需要初始化这一步骤。大部分情况下,如果你决定不好,还是推荐优先选择工厂模式,可以应对后面更多复杂场景。初始化的时机也可以分为注入即初始化、统一初始化、运行时才初始化。很多情况下 注入即初始化、统一初始化 可以结合使用,具体的区分我尝试通过一张表格来对应说明:
| 注入即初始化 | 统一初始化 | 运行时才初始化 | |
|---|---|---|---|
| 是否是纯逻辑型 | 都可以使用 | 是 | |
| 是否需要预挂载或修改系统 | 是 | 不是 | |
| 插件初始化是否有相互依赖关系 | 不是 | 是 | 不是 |
| 插件初始化是否有性能开销 | 都可以使用 | 不是 |
另外还有个问题也在这里提一下,在一些系统中,我们可能依赖许多插件组合来完成一件复杂的事情,为了屏蔽单独引入并配置插件的复杂性,我们还会提供一种 Preset 的概念,去打包多个插件及其配置。使用者只需要引入 Preset 即可,不用关心里面有哪些插件。例如 Babel 在支持 react 语法时,其实要引入 syntax-jsx transform-react-jsx transform-react-display-name transform-react-pure-annotationsd 等多个插件,最终给到的是 preset-react 这样一个包。
插件如何影响系统
插件对系统的影响我们可以总结为三方面:行为、交互、展示。单独一个插件可能只涉及其中一点。根据具体场景,有些方面也不必去影响,比如一个逻辑引擎类型的系统,就大概率不需要展示这块的东西啦。
VSCode 插件大致覆盖了这三个,所以我们可以拿一个简单的插件来看下。这里我们选择了 Clock in status bar 这个插件,这个插件的功能很简单,就是在状态栏加一个时钟,或者你可以在编辑内容内快速插入当前时间。

 整个项目里最主要的是下面这些内容:
整个项目里最主要的是下面这些内容:
在 package.json 中,通过扩展的 contributes 字段为插件注册了一个命令,和一个配置菜单。
"main": "./extension", // 入口文件地址
"contributes": {
"commands": [{
"command": "clock.insertDateTime",
"title": "Clock: Insert date and time"
}],
"configuration": {
"type": "object",
"title": "Clock configuration",
"properties": {
"clock.dateFormat": {
"type": "string",
"default": "hh:MM TT",
"description": "Clock: Date format according to https://github.com/felixge/node-dateformat"
}
}
}
},
复制代码
在入口文件 extension.js 中则通过系统暴露的 API 创建了状态栏的 UI,并注册了命令的具体行为。
'use strict';
// The module 'vscode' contains the VS Code extensibility API
// Import the module and reference it with the alias vscode in your code below
const
clockService = require('./clockservice'),
ClockStatusBarItem = require('./clockstatusbaritem'),
vscode = require('vscode');
// this method is called when your extension is activated
// your extension is activated the very first time the command is executed
function activate(context) {
// Use the console to output diagnostic information (console.log) and errors (console.error)
// This line of code will only be executed once when your extension is activated
// The command has been defined in the package.json file
// Now provide the implementation of the command with registerCommand
// The commandId parameter must match the command field in package.json
context.subscriptions.push(new ClockStatusBarItem());
context.subscriptions.push(vscode.commands.registerTextEditorCommand('clock.insertDateTime', (textEditor, edit) => {
textEditor.selections.forEach(selection => {
const
start = selection.start,
end = selection.end;
if (start.line === end.line && start.character === end.character) {
edit.insert(start, clockService());
} else {
edit.replace(selection, clockService());
}
});
}));
}
exports.activate = activate;
// this method is called when your extension is deactivated
function deactivate() {
}
exports.deactivate = deactivate;
复制代码
上述这个例子有点大块儿,有点稍显粗糙。那么总结下来我们看一下,在最开始我们提到的三个方面分别是如何体现的。
UI:我们通过系统 API 创建了一个状态栏组件。我们通过配置信息构建了一个 配置页。 交互:我们通过注册命令,增加了一项指令交互。 逻辑:我们新增了一项插入当前时间的能力逻辑。
所以我们在设计一个插件架构时呢,也主要就从这三方面是否会被影响考虑即可。那么插件又怎么去影响系统呢,这个过程的前提是插件与系统间建立一份契约,约定好对接的方式。这份契约可以包含文件结构、配置格式、API 签名。还是结合 VSCode 的例子来看看:
文件结构:沿用了 NPM 的传统,约定了目录下 package.json 承载元信息。 配置格式:约定了 main 的配置路径作为代码入口,私有字段 contributes 声明命令与配置。 API 签名:约定了扩展必须提供 activate 和 deactivate 两个接口。并提供了 vscode 下各项 API 来完成注册。
UI 和 交互的定制逻辑,本质上依赖系统本身的实现方式。这里重点讲一下一般通过哪些模式,去调用插件中的逻辑。
直接调用
这个模式很直白,就是在系统的自身逻辑中,根据需要去调用注册的插件中约定的 API,有时候插件本身就只是一个 API。比如上面例子中的 activate 和 deactivate 两个接口。这种模式很常见,但调用处可能会关注比较多的插件处理相关逻辑。
钩子机制(事件机制)
系统定义一系列事件,插件将自己的逻辑挂载在事件监听上,系统通过触发事件进行调度。上面例子中的 clock.insertDateTime 命令也可以算是这类,是一个命令触发事件。在这个机制上,webpack 是一个比较明显的例子,我们来看一个简单的 webpack 插件:
// 一个 JavaScript 命名函数。
function MyExampleWebpackPlugin() {
};
// 在插件函数的 prototype 上定义一个 `apply` 方法。
MyExampleWebpackPlugin.prototype.apply = function(compiler) {
// 指定一个挂载到 webpack 自身的事件钩子。
compiler.plugin('webpacksEventHook', function(compilation /* 处理 webpack 内部实例的特定数据。*/, callback) {
console.log("This is an example plugin!!!");
// 功能完成后调用 webpack 提供的回调。
callback();
});
};
复制代码
这里的插件就将“在 console 打印 This is an example plugin!!!”这一行为注册到了 webpacksEventHook 这个钩子上,每当这个钩子被触发时,会调用一次这个逻辑。这种模式比较常见,webpack 也专门做了一份封装服务 github.com/webpack/tap… 通过定义了多种不同调度逻辑的钩子,你可以在任何系统中植入这款模式,并能满足你不同的调度需求(调度模式我们在下一部分中详细讲述)。
const {
SyncHook,
SyncBailHook,
SyncWaterfallHook,
SyncLoopHook,
AsyncParallelHook,
AsyncParallelBailHook,
AsyncSeriesHook,
AsyncSeriesBailHook,
AsyncSeriesWaterfallHook
} = require("tapable");
复制代码
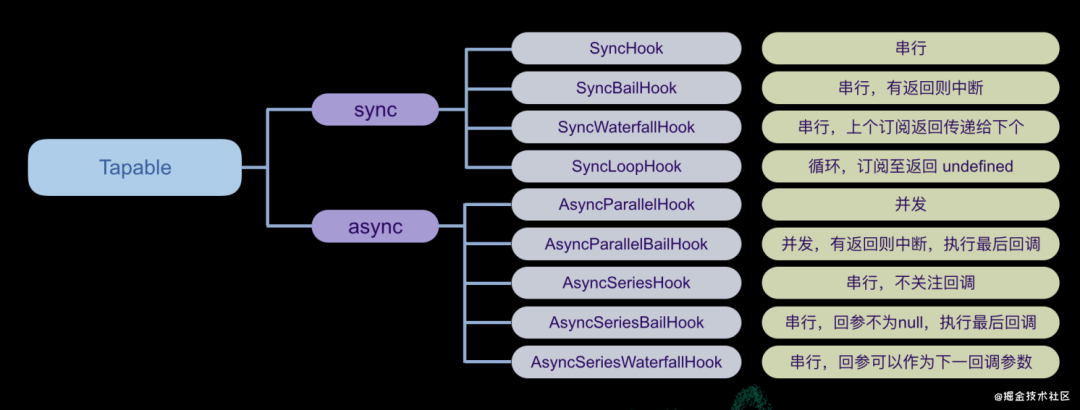
钩子机制适合注入点多,松耦合需求高的插件场景,能够减少整个系统中插件调度的复杂度。成本就是额外引了一套钩子机制了,不算高的成本,但也不是必要的。
使用者调度机制
这种模式本质就是将插件提供的能力,统一作为系统的额外能力对外透出,最后又系统的开发使用者决定什么时候调用。例如 JQuery 的插件会注册 fn 中的额外行为,或者是 Egg 的插件可以向上下文中注册额外的接口能力等。这种模式我个人认为比较适合又需要定制更多对外能力,又需要对能力的出口做收口的场景。如果你希望用户通过统一的模式调用你的能力,那大可尝试一下。你可以尝试使用新的 Proxy 特性来实现这种模式。
不管是系统对插件的调用还是插件调用系统的能力,我们都是需要一个确定的输入输出信息的,这也是我们上面 API 签名所覆盖到的信息。我们会在下一部分专门讲一讲。
插件输入输出的含义与可以使用的能力
插件与系统间最重要的契约就是 API 签名,这涉及了可以使用哪些 API,以及这些 API 的输入输出是什么。
可以使用的能力
是指插件的逻辑可以使用的公共工具,或者可以通过一些方式获取或影响系统本身的状态。能力的注入我们常使用的方式是参数、上下文对象或者工厂函数闭包。
提供的能力类型主要有下面四种:
纯工具:不影响系统状态 获取当前系统状态 修改当前系统状态 API 形式注入功能:例如注册 UI,注册事件等
对于需要提供哪些能力,一般的建议是根据插件需要完成的工作,提供最小够用范围内的能力,尽量减少插件破坏系统的可能性。在部分场景下,如果不能通过 API 有效控制影响范围,可以考虑为插件创造沙箱环境,比如插件内可能会调用 global 的接口等。
输入输出
当我们的插件是处在我们系统一个特定的处理逻辑流程中的(常见于直接调用机制或钩子机制),我们的插件重点关注的就是输入与输出。此时的输入与输出一定是由逻辑流程本身所处的逻辑来决定的。输入输出的结构需要与插件的职责强关联,尽量保证可序列化能力(为了防止过度膨胀以及本身的易读性),并根据调度模式有额外的限制条件(下面会讲)。如果你的插件输入输出过于复杂,可能要反思一下抽象是否过于粗粒度了。
另外还需要对插件逻辑保证异常捕捉,防止对系统本身的破坏。
还是 Babel Parser 那个例子。
{
parseExprAtom(refExpressionErrors: ?ExpressionErrors): N.Expression;
getTokenFromCode(code: number): void; // 内部再调用 finishToken 来影响逻辑
updateContext(prevType: TokenType): void; // 内部通过修改 this.state 来改变上下文信息
}
复制代码
意料之中的输入,坚信不疑的输出
复数个插件之间的关系是怎么样的
Each plugin should only do a small amount of work, so you can connect them like building blocks. You may need to combine a bunch of them to get the desired result.
这里我们讨论的是,在同一个扩展点上注入的插件,应该以什么形式做组合。常见的形式如下:
覆盖式
只执行最新注册的逻辑,跳过原始逻辑
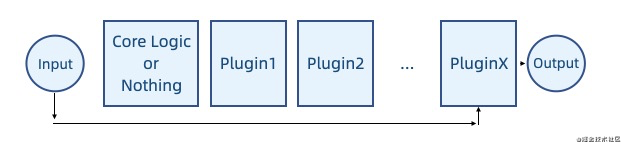
管道式
输入输出相互衔接,一般输入输出是同一个数据类型。
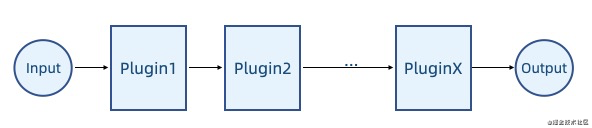
洋葱圈式
在管道式的基础上,如果系统核心逻辑处于中间,插件同时关注进与出的逻辑,则可以使用洋葱圈模型。
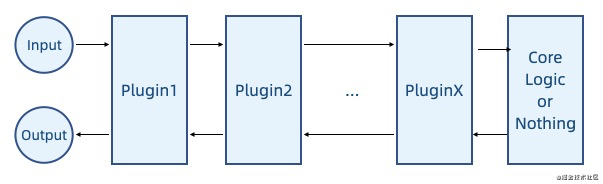
这里也可以参考 koa 中的中间件调度模式 github.com/koajs/compo…
const middleware = async (...params, next) => {
// before
await next();
// after
};
复制代码
集散式
集散式就是每一个插件都会执行,如果有输出则最终将结果进行合并。这里的前提是存在方案,可以对执行结果进行 merge。
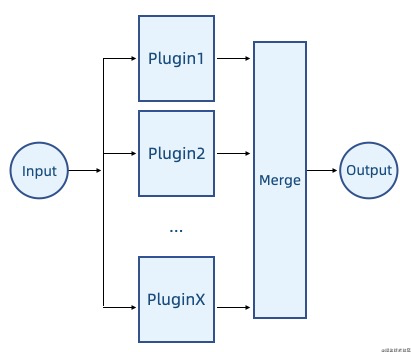
另外调度还可以分为 同步 和 异步 两个方式,主要看插件逻辑是否包含异步行为。同步的实现会简单一点,不过如果你不能确定,那也可以考虑先把异步的一起考虑进来。类似 www.npmjs.com/package/neo… 这样的工具可以很好地帮助你。如果你使用了 tapble,那里面已经有相应的定义。
另外还需要注意的细节是:
顺序是先注册先执行,还是反过来,需要给到明确的解释或一致的认知。 同一个插件重复注册了该怎么处理。
总结
当你跟着这篇文章的思路,把这些问题都思考清楚之后,想必你的脑海中一定已经有了一个插件架构的雏形了。剩下的可能是结合具体问题,再通过一些设计模式去优化开发者的体验了。个人认为设计一个插件架构,是一定逃不开针对这些问题的思考的,而且只有去真正关注这些问题,才能避开炫技、过度设计等面向未来开发时时常会犯的错误。当然可能还差一些东西,一些推荐的实现方式也可能会过时,这些就欢迎大家帮忙指正啦。
作者:ES2049 / armslave00
文章可随意转载,但请保留此原文链接。
非常欢迎有激情的你加入 ES2049 Studio,简历请发送至 caijun.hcj@alibaba-inc.com 。
最后