
大模型训练:为什么用A100不用4090?


问题来了,如果 4090 这么香的话,为啥大家还要争着买 H100,搞得 H100 都断货了?甚至 H100 都要对华禁售,搞出个 H800 的阉割版?
大模型训练为什么不能用 4090
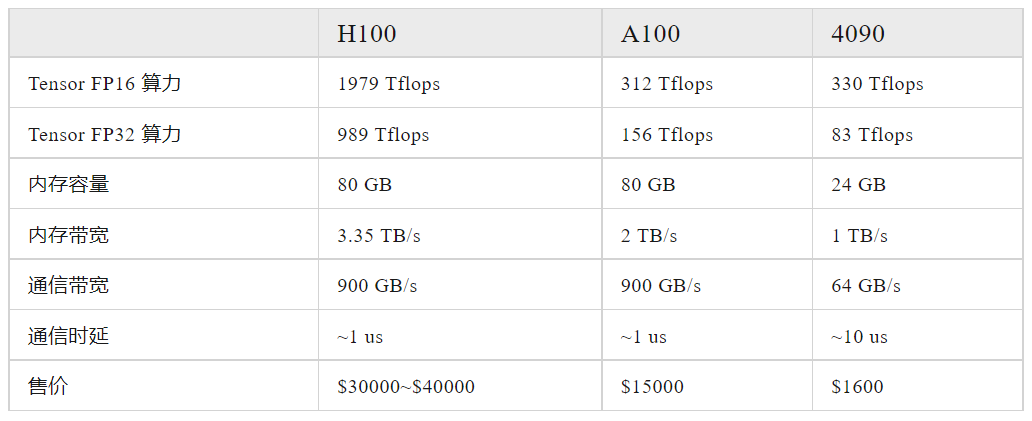
GPU 训练性能和成本对比
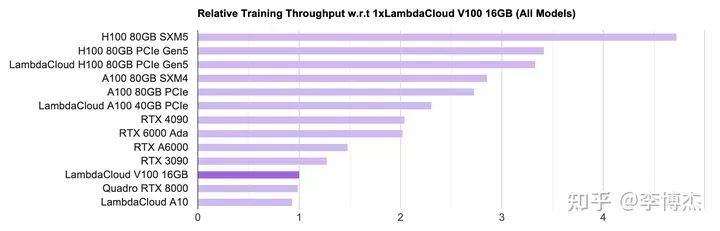
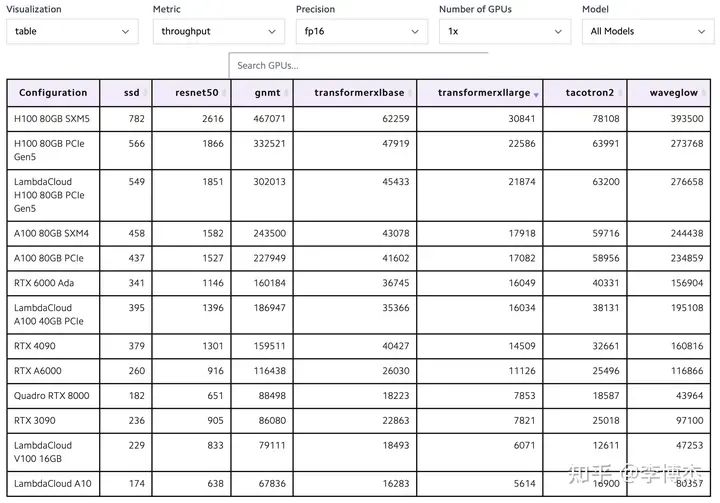
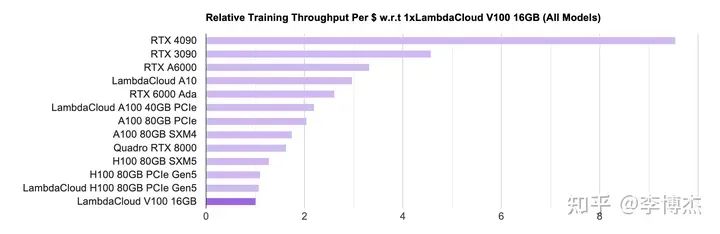
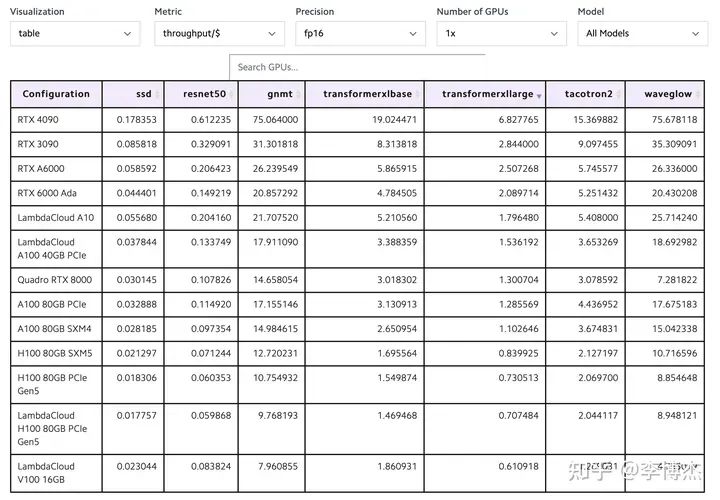
大模型训练的算力需求
训练 LLaMA-2 70B 需要多少张卡

Data parallelism(数据并行)

Pipeline parallelism(流水线并行)
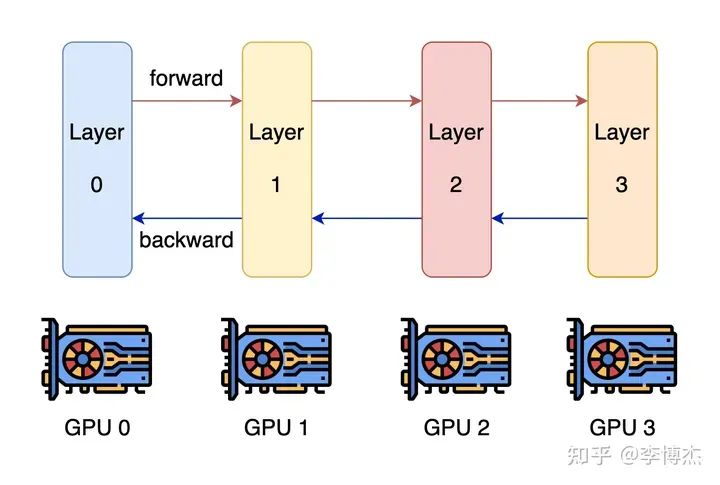

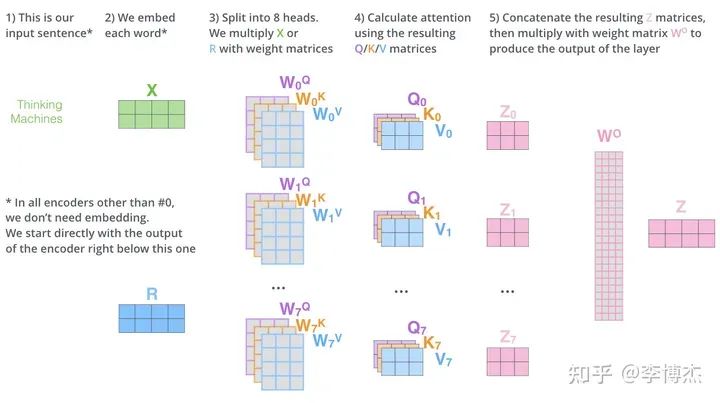
Tensor parallelism(张量并行)


训练部分小结
大模型推理为什么 4090 很香
KV Cache
推理是计算密集还是存储密集
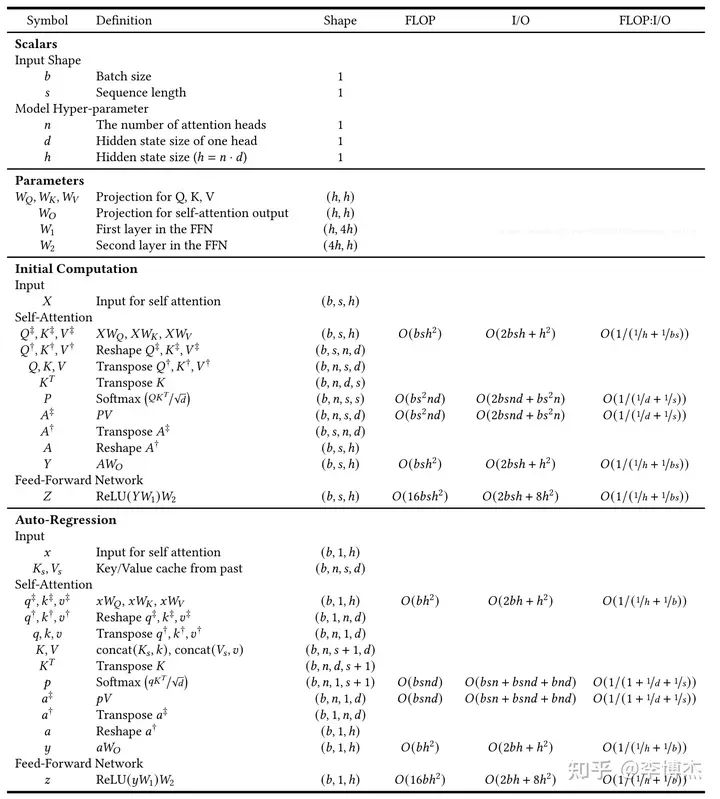
70B 推理需要多少张卡?
推理用流水线并行可以吗?
推理用张量并行怎么样?
用 4090 做推理的成本怎么样?
-
首先,GPU 的算力利用率到不了 100%; -
其次,如同所有 SaaS 服务一样,用户的请求数量有波峰有波谷,用户是按量付费的,平台提供方可是不管有没有人用都在烧钱的; -
此外,每个 batch 中不同 prompt 的长度和响应 token 数量都不同,消耗的算力是 batch 中最大的那个,但收的钱是用户实际用的 token 数; -
再次,GPT-3.5 是 175B 的模型,比 70B 的 LLaMA 很可能推理成本更高; -
最后,OpenAI 开发 GPT-3.5 是烧了不知道多少钱的,人家至少要赚回训练成本和研发人员的工资吧。
用最便宜的设备搞出最高的推理性能
License 问题怎么办?
就像本文开头提到的微软给每台服务器部署 FPGA 一样,大规模量产的芯片价格就像沙子一样。到时候,能限制大模型推理算力的就只有能源了,就像区块链挖矿和通用 CPU 的云计算一样,都在找最便宜的电力供应。我在之前的一个采访中就表示,长期来看,能源和材料可能是制约大模型发展的关键。让我们期待廉价的大模型走进千家万户,真正改变人们的生活。
https://zhuanlan.zhihu.com/p/655402388
1、电信运营商液冷技术白皮书(2023)
2、浸没式液冷数据中心运维白皮书
3、运营商力推液冷,中兴液冷技术领先(2023)
1、浸没式液冷数据中心热回收白皮书(2023) 2、数据中心绿色设计白皮书(2023)
1、集装箱冷板式液冷数据中心技术规范
2、浸没式液冷发展迅速,“巨芯冷却液”实现国产突破
3、两相浸没式液冷—系统制造的理想实践
4、AIGC加速芯片级液冷散热市场爆发
1、中国液冷数据中心发展白皮书
2、全浸没式液冷数据中心解决方案
3、浸没液冷数据中心规范
4、喷淋式直接液冷数据中心设计规范
5、单相浸没式直接液冷数据中心设计规范
1、某液冷服务器性能测试台的液冷系统设计
2、浸没液冷服务器可靠性白皮书
3、天蝎5.0浸没式液冷整机柜技术规范
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
