
旷视提出纯基于 Transformer 的人体姿态估计模型(附pytorch导出onnx说明)
共 3471字,需浏览 7分钟
·
2022-01-01 23:24

极市导读
本文将两种Token特征一起放入Transformer,于是模型可以同时学习到图像纹理信息和关键点连接的约束信息。在实验部分作者也通过对注意力进行可视化的方式,验证了关键点约束信息的学习情况。通过没有CNN的纯Transformer消融实验也验证了这种约束信息的学习来自于Transformer结构,不过CNN与Transformer的组合结构更能结合二者优势,取得了最优的结果。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文将两种Token特征一起放入Transformer,于是模型可以同时学习到图像纹理信息和关键点连接的约束信息。在实验部分作者也通过对注意力进行可视化的方式,验证了关键点约束信息的学习情况。通过没有CNN的纯Transformer消融实验也验证了这种约束信息的学习来自于Transformer结构,不过CNN与Transformer的组合结构更能结合二者优势,取得了最优的结果。
旷视ICCV2021的工作,做法很简洁,效果看起来也还不错。论文地址:https://arxiv.org/pdf/2104.03516.pdf;代码地址:https://github.com/leeyegy/TokenPose。
1. 简介
人体姿态估计任务主要依赖两方面的信息,视觉信息和解剖学约束信息,这一点在之前的一些工作如AID等中也有共识(图像纹理信息和约束信息),而对于CNN来说,其优势在于对于图像纹理信息的特征提取能力极强,能学习到高质量的视觉表征,但在约束信息的学习上则有所不足(比如关节之间的连接关系)。本文利用了Transformer中多头注意力机制的特点,能学到位置关系上的约束,以及不同关键点之间的关联性,并且极大地减少了模型的参数量和计算量。
本文标题中的Token来源于NLP中,每个词或字符用一个特征向量来表示,这个向量就称为一个Token或一条Embedding。在本工作中设置了两种Token类型,一种是visual token,是将特征图按patch拆分后拉成的一维特征向量;另一种是keypoint token,专门学习每一个关键点的特征表示。将两种Token特征一起放入Transformer,于是模型可以同时学习到图像纹理信息和关键点连接的约束信息。在实验部分作者也通过对注意力进行可视化的方式,验证了关键点约束信息的学习情况。通过没有CNN的纯Transformer消融实验也验证了这种约束信息的学习来自于Transformer结构,不过CNN与Transformer的组合结构更能结合二者优势,取得了最优的结果。
2. 方法
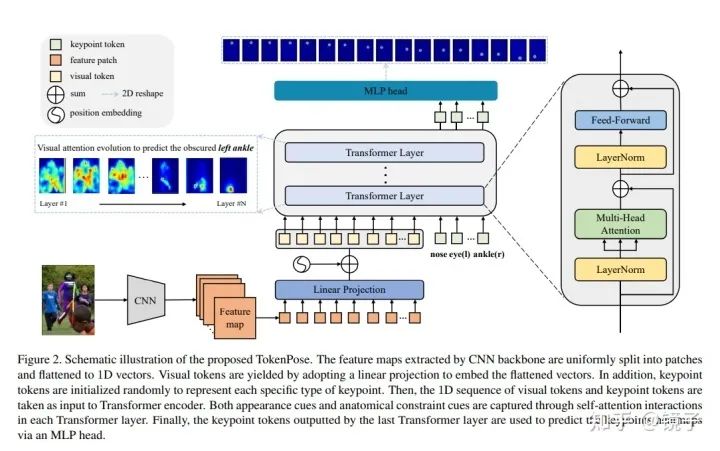
流程上,本文的方法属于二阶段top-down人体姿态估计算法。
本文先通过一个基于CNN的骨干网络来提取特征图,将特征图拆分为patch后拉平为一维向量,经过一个线性函数(全连接层)投影到d维空间,这些向量称为visual tokens,负责图片纹理信息的学习。考虑到姿态估计任务对于位置信息是高度敏感的,因此还要给token加上2d位置编码。
然后,通过随机初始化一些可学习的d维向量来作为keypoint tokens,每个token对应一个keypoint。这个做法是比较有意思的,因为过去的工作一般keypoint都会由图片特征图学习得到,而本工作选择了随机初始化。随着训练完成,这些tokens也会确定。
self.keypoint_token = nn.Parameter(torch.zeros(1, self.num_keypoints, dim))
这种做法实际上也不是本文原创的,在Vit的工作中,进行有监督分类训练的时候就是用的这样的方法,通过一个传入一个cls token来跟图片patch token一起进入transformer,最终输出的cls token进行分类预测。而这种方法又来自于BERT的文章,可谓是一脉相承。本文将单个的cls token扩展为n个keypoint token是非常符合直觉的一件事,在其他姿态估计工作中,也有将每个keypoint作为单独的一个类进行学习的做法。
最后,本文将两种token一起送入transformer进行学习,并将输出的keypoint tokens通过一个MLP映射到HxW维,以此来预测heatmap。
实验
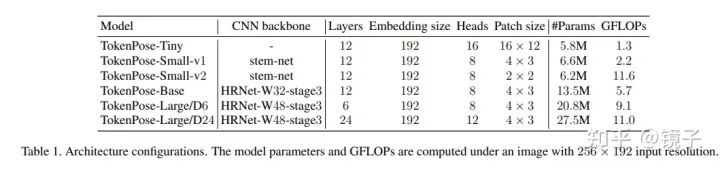
本工作通过实验对比了纯Transformer和CNN+Transformer两种结构:
实验结果:
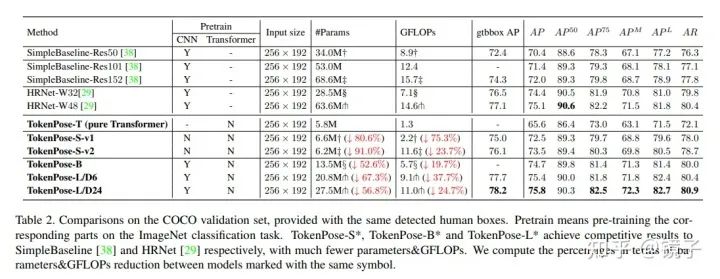
从结果来看主要是减少了大量的参数和计算量,取得的结果上的提升不算特别惊人。
本文对不同transformer层对应的每个关键点注意力进行了可视化,可以清晰地看到一个逐渐确定到对应关节的过程:
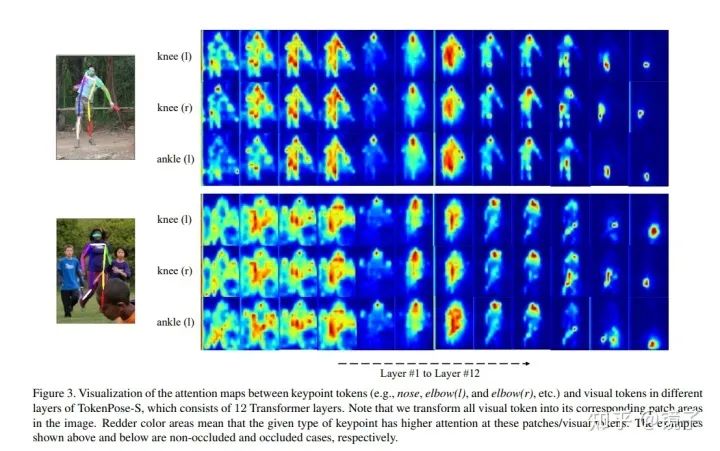
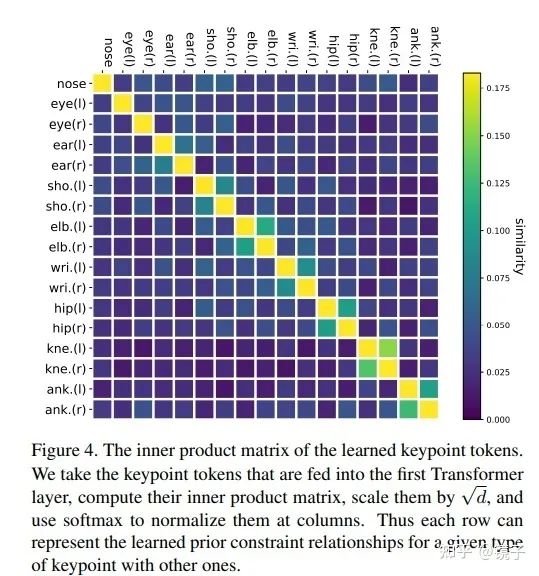
对学习完成的keypoint tokens计算内积相似度也可以发现,相邻关节点和左右对称位置的关节的token相似度是最高的,这也符合我们的直觉:
导出ONNX
官方的代码直接导出onnx的话会报错:
op_set版本不支持的,设置opset_version=12及以上 段错误,我遇到的主要是官方实现中einsum库的rearrange导致的,可以通过以下代码来修复:
# Attention模块forward中
# q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv)
q, k, v = map(lambda t: t.reshape(-1,n,h,int(t.numel()//n//h//b)).permute(0,2,1,3), qkv)
# out = rearrange(out, 'b h n d -> b n (h d)')
out = out.permute(0,2,1,3).reshape(-1,n,int(out.numel()//b//n))
# TokenPose_S_base模块forward中
p = self.patch_size[0] # 这里假设patch是正方形,非正方形的自己做对应修改
# transformer
# x = rearrange(x, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p[0], p2=p[1])
b, c, h, w = x.shape
x = x.permute(0, 2, 3, 1).reshape(b, h, int(w/p), c*p).permute(0, 2, 1, 3).reshape(b, int(h/p),int(w/p), c*p*p).permute(0, 2, 1, 3).reshape(b, int(h/p)*int(w/p), p*p*c)
经过以上转换,在我的环境上可以正常导出onnx并转为mnn部署运行。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
