
(干货)如何通过分解和增量更改将单体迁移到微服务?
作者 | Sam Newman、Leandro Guimarães
译者 | 平川
本文基于 Sam 在伦敦 QCon 大会上的演讲记录,由 Leandro Guimarães 整理,并由 Sam 审阅。
在伦敦 QCon 大会上,我谈到了单体分解模式以及我们如何达成微服务。我喜欢把它们比作令人讨厌的水母,因为它们是一种乱糟糟的实体,会刺痛甚至可能杀死我们。这在通常的企业微服务迁移中很常见。
许多组织正在经历某种数字化转型。随便看下当前的任何数字化转型,我们都会发现微服务的身影。我们知道,数字化转型是一件大事,因为现在任何机场候机室都有大型 IT 咨询公司的广告推销数字化转型,包括德勤、DXC、埃森哲等公司。微服务非常流行。
不过,在谈及微服务时,我关注的是结果,而不是我们用来实现它们的技术。我们选择微服务架构的原因有很多,但我反复提到的一个原因是其独立部署的属性。有一个功能,一个我们想要改变系统行为的更改。我们想要尽快实现这个更改。
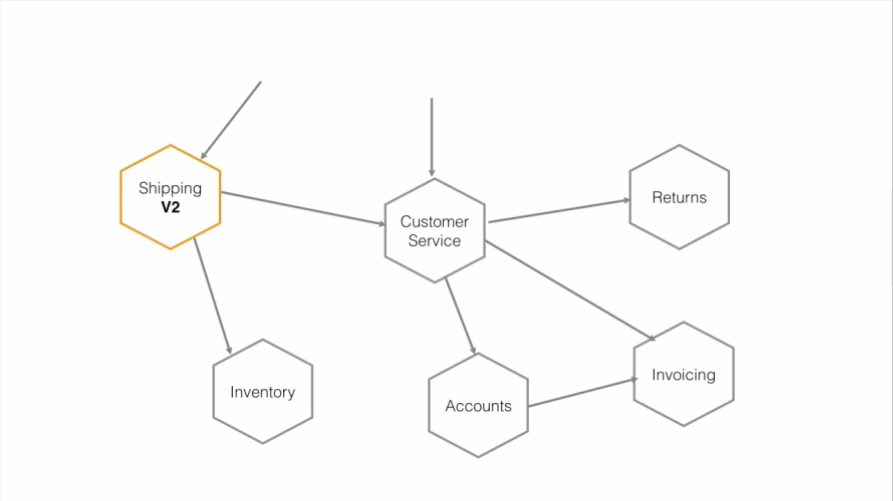 图 1:微服务方法示意图
图 1:微服务方法示意图
将微服务架构与单体做下比较。我们认为,单体是一个单一的、无法透视的块,我们无法对它作出任何更改。单体被认为是我们生活中最糟糕的东西,是难以摆脱的沉重负担。我认为这非常不公平。最终,“单体”一词在过去两三年里取代了我们之前使用的“遗留问题(legacy)”一词。这是一个根本性问题,因为有些人开始将单体视为遗留问题,是需要移除的东西。我认为这非常不合适。
单体有多种形式和规模。在讨论单体应用程序时,我主要是将单体作为部署单元来讨论。考虑下经典的单体,它是将所有代码打包在单个进程中。它可能是 Tomcat 中的一个 WAR 文件,也可能是一个基于 PHP 的应用程序,所有代码都打包在一个可部署单元中,该单元会与数据库通信。
这种单体类型可以看作是一个简单的分布式系统。分布式系统是由多台通过非本地网络相互通信的计算机组成的系统。在这种情况下,所有的代码都打包在一个进程中,重要的是,所有数据都保存在于一个运行在不同机器上的大型数据库中。把所有数据都放在一个数据库中,将来会给我们带来很多痛苦。
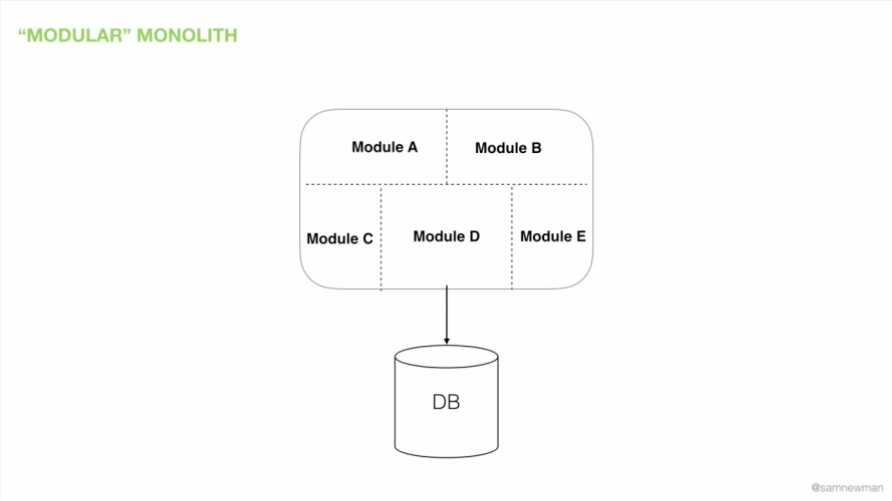 图 2:模块化单体
图 2:模块化单体
我们还可以考虑下单进程单体的一种变体,称为模块化单体。这种模块化单体使用了关于结构化编程的前沿思想(诞生于 20 世纪 70 年代初,几十年后,我们中的一些人仍在努力掌握这些思想!)。如图 2 所示,我们将单进程单体应用程序分解为模块。如果我们正确地划分了模块边界,我们就可以独立地处理每个模块。但是,本质上,部署过程仍然是静态链接的方法:我们必须链接好所有模块才能进行部署。比如一个 Ruby 应用程序,它由许多 GEM 文件、NuGet 包或通过 Maven 组装的 JAR 文件组成。
虽然我们仍然是单体部署,但模块化单体有一些显著的好处。把代码分解成模块确实可以让我们在一定程度上独立地完成工作。它可以方便不同的团队一起工作,并处理系统的不同方面。我认为这是一个被严重低估的选项。这其中存在的问题是,人们往往不善于定义模块边界——更确切地说,即使他们擅长定义模块边界,他们也不擅长保持这些边界。遗憾的是,结构化编程或模块化的概念往往会遭遇“泥球”问题。
对于我服务过的许多组织来说,使用模块化单体比使用微服务架构会更好。在过去的三年里,我对我一半的客户说过:“微服务不适合你。“有些客户甚至听了我的话。对于它们中的许多来说,一种可以定义模块边界的好方法就足以满足它们的需要。他们可以得到一个比较简单的分布式系统,以及一定程度上独立、自主地工作。
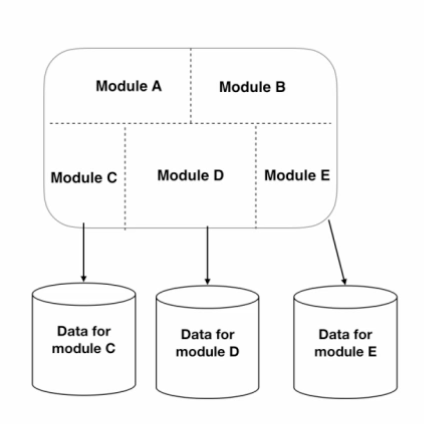
图 3:模块化单体的一种变体
模块化单体也有变体。图 3 看起来有点奇怪,但这是我多次提出的建议,特别是对于初创公司,我通常认为,他们最好不要着急上微服务。如图 3 所示,我们使用了模块化单体,并将后台单个的整体数据库进行了分解,这样就可以单独存储和管理每个模块的数据。
虽然这看起来很奇怪,但归根结底这是一种对冲架构。人们认识到,分解单体架构时最困难的工作之一是处理数据层。如果我们能提前设计好与这些模块相关联的独立数据库,以后迁移到单独的微服务就会更容易。如果我正在处理模块 C,我对与模块 C 关联的数据具有完全的所有权和控制权。当模块 C 变成一个单独的服务时,迁移它应该会更容易。
当我还在 ThoughtWorks 工作时,我的一位老同事 Peter Gillard-Moss 第一次向我展示了这种模式。这是他为我们正在开发的一个内部系统设计的。他说,“我觉得这能行。我们不确定我们是否想要提供服务,所以也许它应该是一个单体。”
我说,“试一试。看看会发生什么。“大约 6 年过去了,去年我和 Peter 谈过,ThoughtWorks 仍然没有改变架构。它仍然运行得很欢快。他们让不同的人处理不同的模块,即使是在这个级别上将数据分离开来,也给他们带来了巨大的好处。
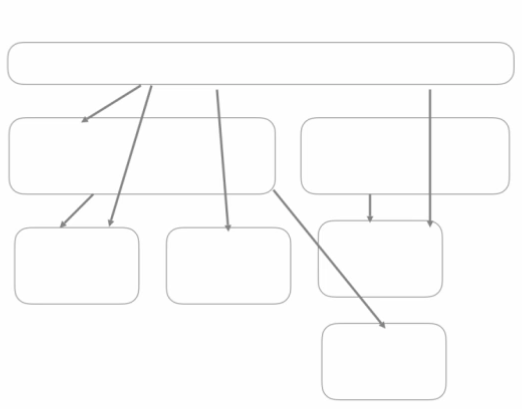
图 4:分布式单体
现在,我们来看看最糟糕的单体——分布式单体。我们的应用程序代码现在运行在彼此通信的独立进程上。不管出于什么原因,我们都必须将整个系统作为一个单元同步部署。经常,这种情况的出现是因为我们弄错了服务边界。我们将业务逻辑胡乱地放在了不同的层上。我们没有遵从关于耦合和内聚的要点,现在,我们的结账逻辑分布在服务栈中 15 个不同的地方。我们要做任何工作,都必须协调多个团队。如果组织中存在大量的横切更改,通常表明组织边界或服务边界定义的不对。
分布式单体的问题在于,它本质上是一个更加分布式的系统,但是对于所有相关的设计、运行和操作挑战,我们仍然需要单体需要的那些协调活动。我想在线部署,但我不能。我必须等你完成更改,但你也完不成,因为你在等别人。现在,我们一致同意:“好吧,7 月 5 日,我们将一起上线。每个人都准备好了吗?三、二、一,部署。“当然,一切都很顺利。对于这类系统,我们从来没有遇到过任何问题。
如果一个组织有一位全职的发布协调经理或这方面的其他职位,那么他们可能有一个分布式单体。协调分布式系统的同步部署一点都不好玩。我们最终会付出更高的更改成本。部署的范围会大很多,可能会有更多的地方出错。这种难以避免的协调活动,不只存在于发布活动中,而且存在于一般部署活动中。
稍微看下精益生产的内容就会发现,减少交接是优化生产力的关键。等待别人为我做点什么只会产生浪费。这会导致生产力瓶颈。为了更快地交付软件,减少交接和协调非常关键。遗憾的是,分布式单体往往会创造出不得不进行协调的环境。
有时,我们的问题不在于服务边界在哪里。有时,它完全是始于我们开发软件的方式。有些人从根本上误解了发布序列。发布序列一直被认为是一种治疗性的发布技术,而不是一种进取性的活动。我们会选择像发布序列这样的东西来帮助组织转向持续交付。发布序列的概念以定期为基础,也许每四周,软件的所有部分已经准备就绪。如果软件还没有准备好,它就会被推迟到下一个发布序列。对许多组织来说,这是向前迈出了一步。我们应该缩小发布序列之间的间隔,最终完全消除。然而,有太多的组织在采用了发布序列就再也没有继续前进。
当若干团队都朝着同一个发布序列而努力时,所有已经准备好的软件都会在这个发布序列中交付——突然之间,我们会一次性部署大量的服务。这是真正的问题所在。当实践发布序列时,最重要的一件事是,至少要将这些发布序列分解,使它们成为团队发布序列。允许不同的团队安排自己的发布序列。最终,我们应该抛弃这些序列。它们应该只是迈向持续交付的一个步骤。
遗憾的是,一些营销敏捷的优秀成果已经将发布序列作为交付软件的最终方式。我们知道他们已经这么做了,因为许多公司组织里挂着的 SAFe 图解上都印着“发布序列”的字样。这不是好事。不管是对于 SAFe,还是你遇到的任何其他问题,发布序列始终都是一种补救技术,是自行车的辅助轮。我们应该向着持续交付继续前进。问题是,如果我们使用这些发布序列时间太长,最终的架构就会是一个分布式单体,因为我们已经习惯了将所有服务部署在一起。要注意这一点。这可能不会在一夜之间发生。我们可以从支持独立部署的架构开始,但如果我们使用发布序列太久,我们的架构就会开始围绕这些发布实践聚合在一起。
归根结底,分布式单体是一个问题,因为它同时具有分布式系统的所有复杂性和单个部署单元的缺点。我们应该跨越它,寻找更好的工作方式。分布式单体是一件很棘手的事情,关于如何处理这种情况的建议已经有很多。有时,正确的答案是将其合并回单进程单体。但是,如果现如今我们有一个分布式单体,最好的办法是弄清楚为什么我们会有这样的单体,并且在添加任何新服务之前,着手让架构中的某些部分可以独立部署。在这种情况下,添加新服务很可能会增加我们开展工作的难度。
我们使用微服务架构是因为它具有独立部署的特性。我们希望能够在不改变其他任何东西的情况下将服务的更改部署到产品中。这是微服务的黄金法则。在演讲或文章中,这似乎很容易。在现实生活中,要做到这一点要困难得多,尤其是考虑到大多数人并非从零开始。绝大多数人都觉得他们的系统太大了,想把它分成更小的部分。他们想知道从哪里开始。
领域驱动设计(DDD)有一些很好的方法可以帮助我们找出服务边界。当与研究微服务迁移的组织合作时,我们通常是从在现有的单体应用程序架构上执行 DDD 建模练习开始。我们这样做是为了弄清楚单体应用内部发生了什么,并从业务域的角度确定工作单元。
尽管单体看起来像一个巨大的盒子,但当我们应用 DDD,并将逻辑模型投射到该单体上时,我们意识到,其内部被组织成订单管理、PDF 渲染、客户端通知等内容。虽然代码可能没有围绕这些概念进行组织,但从用户或业务领域模型的角度来看,这些概念存在于代码中。这些业务领域的边界(DDD 中通常称为“有界上下文”)就成为我们分解的单元,原因我这里就不展开讨论了。
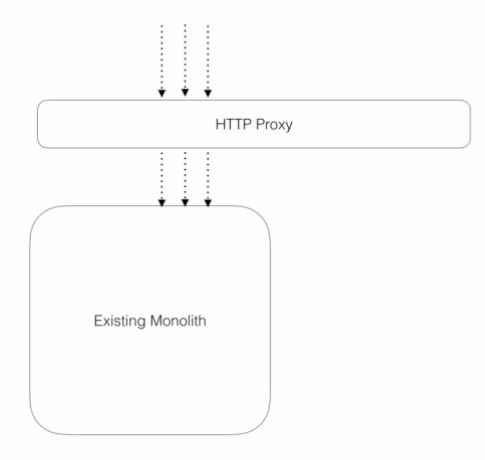
图 5:找出单体中的分解和依赖项单元
首先要做的是问下从哪里开始,什么事情可以优先处理,我们的工作单元是什么。在图 5 所示的初始单体中,我们有订单管理、发票和通知。DDD 建模练习将使我们了解它们之间的关系。但愿我们能得出一个有向无环图,来描述这些不同功能之间的依赖关系。(如果我们得到是一个依赖关系的循环图,我们就得做更多的工作。)我们可以看到,在这个单体中,有很多东西都依赖于向客户发送通知的能力。那似乎是领域的核心部分。
我们可以开始问问题了,比如我们应该先提取什么。我可以完全从这个角度来看问题。我们可能会看到,通知被很多功能使用——如果微服务更好,那么提取系统中很多部分都在使用的东西将使更多的东西变得更好。也许我们应该从那里开始。但是,看看所有的入站依赖关系。因为有太多的部分需要通知功能,所以我们很难将其从现有的单体架构中剥离出来。在这个单体系统中,像结账或订单管理之类的概念似乎更加独立。它们可能是更容易分解的东西。决定从哪一部分开始,从根本上讲是一种渐进式分解方法。
首先要记住,单体并不是敌人。我希望大家都好好地思考一下。人们将任何单体系统都视为问题。在过去几年里,我看到的最令人担忧的事情之一是,微服务现在似乎成了许多人的默认选择。
有人可能记得一句老话:“没有人会因为购买 IBM 产品而被解雇。”意思是,因为其他人都在买 IBM 产品,你也可以买——如果你买的东西不适合你,那也不是你的错,因为大家都在这么做。你没必要冒险。现在每个人都在做微服务,我们也面临同样的问题。每个人都吵着要做微服务。这对我很有好处:我写关于该主题的书,但对你可能不是好事。
从根本上说,这取决于我们想要解决什么问题。我们想要达到而在当前的架构下无法达到的目标是什么?也许微服务是答案,或者其他什么东西才是答案。理解我们想要达到的目标至关重要,否则,我们将很难确定如何迁移我们的系统。我们正在做的事情将改变我们分解系统的方式,以及我们如何确定工作的优先级。
微服务迁移不像一个开关,没有开 / 关切换。这更像是转动一个旋钮。在采用微服务的过程中,我们转动一下旋钮,增加一两个服务。我们想看看一个服务如何发挥作用,它是否提供了我们需要的东西,是否解决了我们的问题。如果是,而且我们也满意,我们就可以继续转动旋钮。
不过,我看到很多人都会转动旋钮,增加 500 项服务,然后插上耳机,检查音量。这是让鼓膜破裂的好方法。我们不知道我们将要面对什么问题,那些问题在开发人员的笔记本电脑上碰不到。它们会在生产环境中出现。当我们从提供一个单体系统转为一次性提供 500 个服务时,所有的问题都会同时出现。不管我们最后是提供一项、两项还是五项服务,还是像 Monzo 那样拥有 800 项或 1500 项服务,我们都必须从一个小转变开始。我们需要选择一些服务来启动迁移。让它们在生产环境中运行,积累经验,并尽快把这种经验付诸实践。通过逐步调整,以渐进的方式创建和发布新的微服务,我们可以更好地发现和处理出现的问题。每个项目将要面对的问题都会有所不同,这取决于许多不同的因素。
我们想要从单体系统中提取一些功能,让它与单体系统的剩余部分通信并集成,并且要尽快完成。我们不想再进行大爆炸式的重写了。我们过去是每年向用户发布软件,因为有一个为期 12 个月的窗口期,所以我们可以这样说:“现有的系统太糟糕了,现在已经无法使用了,但是我们还有 12 个月的时间来发布下一个版本。如果我们努力,完全可以重写系统,我们不会再犯过去犯过的错误,现有的功能一个都不会少,而且还会有更多的新功能,一切都会很好。”
当每年发布一次软件时,我们从来没有那样做。当人们期望每月、每周或每天发布软件时,我不知道该如何证明其合理性。套用 Martin Fowler 的话来说,“如果你要进行大爆炸式的重写,你唯一能确定的就是大爆炸。”我喜欢动作片中的爆炸场面,但不喜欢我的 IT 项目里出现这种情况。我们需要从不同的角度思考如何做出这些更改。
我是架构增量演进的忠实拥护者。我们不应该认为我们的架构是一成不变的。我们需要有一些模式来帮助我们以渐进的方式向微服务转变。
我们首先看下应用程序模式 Strangler Fig,它以一种植物命名,这种植物在树冠上生根,然后卷须向下缠绕在树干上。绞杀榕(strangler fig)靠自身无法爬到林冠层以获得足够的阳光,所以它不像普通树木一样从一棵小树苗慢慢长大,而是包裹在现有的植物体上。它依赖于现有的树的高度和力量。随着时间的推移,这些绞杀榕成长起来,变得越来越大,能够独立生存了。如果下面的树死了,腐烂了,就只剩下绞杀榕和一根空心的柱子。这些东西看起来就像蜡滴在其他树上——看起来真的很令人不安。
但是作为应用程序迁移策略的一种模式,这种思想是有用的。我们找一个现有的系统(它完成我们想要它做的所有事情,即现有的单体应用程序),然后开始围绕它封装出我们的新系统。在这里,就是我们的微服务架构。实现 Strangler Fig 应用程序有两个关键。第一个是资产捕获,即确定把哪些功能迁移到微服务架构的过程。然后我们需要进行转接。以前对于单体应用程序的调用得转接到新功能上。如果功能没有迁移,调用就不需要转接;非常简单。
有些人对如何转移功能感到困惑。如果我们真的够幸运的话,也许可以简单地复制代码。如果结账服务的代码在单体代码库中一个叫“结账”的漂亮盒子中,我们就可以剪切并粘贴到新服务中。我认为,如果代码库是这种状态,那你可能不需要任何帮助。更大的可能是,我们将不得不快速浏览系统,设法收集所有与结账相关的代码。我们可能会做一些重构前的活动。也许我们可以重用这些代码,但在这种情况下,那将是复制粘贴,而不是剪切粘贴。我们想把这个功能留在这个单体应用中,原因我将在后面讨论。更常见的情况是,人们会进行一些重写。
实现 Strangler Fig 的方法有很多种。让我们来看一种简单的方法。
假设我们有一个基于 HTTP 的单体系统。这可能是一个无头应用程序。我们可以在用户界面的后台使用 API Boundary 拦截调用。我们需要的是可以将调用重定向的东西,因此,我们将使用某种 HTTP 代理。对于这类架构,HTTP 协议非常有效,这是因为它非常适合透明地重定向调用。通过 HTTP 发起的调用可以被转接到许多不同的地方。有很多软件可以帮你做到这一点,而且非常简单。
图 6:HTTP 代理拦截对单体的调用,增加了一个网络跃点
首先要做的是,在上游流量和下游单体系统之间放置一个代理,别的什么都不用做。我们将把这个代理部署到生产环境中。此时,它还没有转接任何调用。我们可以看下它在生产环境中是否有效。我们要担心的一件事是网络质量,因为我们增加了一个网络跃点。通常是直接调用单体系统,但现在通过我们的代理。在这种情况下,延迟是杀手。通过代理转接只会给现有的调用增加几毫秒的开销——少于 10 毫秒就很棒。如果额外增加一个网络跃点增加了 200 毫秒的延迟,我们就需要暂停微服务迁移,因为我们还有其他需要首先解决的大问题。
准备好代理之后,我们接下来将处理新的结账服务。我们将其部署到生产环境中。即使它功能还不全,也没什么问题,因为它还没有被使用。我们要在脑海中将部署到生产环境和使用这两个概念分开。开始采用微服务后,我们希望定期地将功能部署到生产环境中,以确保我们的部署机制能够正常工作。在添加功能时,我们可以单独测试新服务。我们还没有把它发布给用户,但它已经在生产环境中了。我们可以将它连接到我们的仪表板上,确保日志聚合正常,或者做其他我们想做的事。
关键是我们只对一个服务进行操作。我们甚至可以将那个服务的提取过程分解为许多小步骤:创建服务框架、实现方法、在生产环境中测试它,然后部署发布版本。准备就绪之后,当我们认为新实现已经等同于旧系统时,我们只需重新配置代理,将调用从旧的单体功能转到新的微服务。
事到如今,你可能认为现在应该从这个单体中删除旧功能。先别这么做!如果新创建的微服务在生产环境中出现问题,我们有一种非常快的补救技术:我们只需还原代理配置,将流量转到原功能所在的单体上。不过,要想实现这一点,我们必须考虑数据的作用——这点我们稍后讨论。
我们希望,将这个功能提取成微服务是一种真正的重构,改变代码的结构而不是行为。在功能上,微服务应该等同于单体中的同一功能。我们应该能够在它们之间切换,直到微服务正常工作为止。
如果我们想要保留切换的能力,那么在迁移完成、我们不再需要这种切换能力之前,我们就不应该添加新的功能或更改现有的功能。
在很多情况下,这项简单的 Strangler Fig 技术都出奇的好。这个例子使用了 HTTP,但是我也看过使用 FTP 的情况。我已经用消息拦截器做到了这一点。我在上传固定文件时就这么做了:我们插入固定文件,在新服务中剔除我们希望去掉的内容,然后把剩下的内容传递下去。
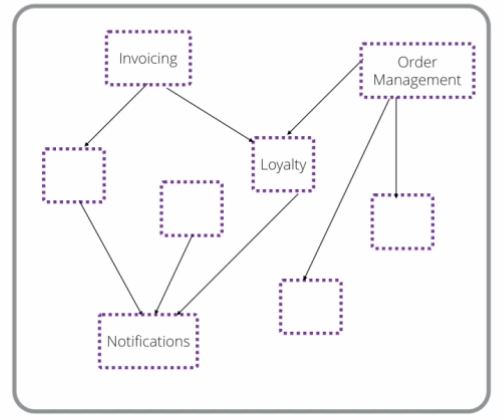
图 7:微服务架构的有向无环图
Strangler Fig 对于结账或订单管理等功能非常有效,这些功能在我们的调用堆栈中处于更高的位置,如图 7 所示的依赖关系图。但是,进入单体系统的调用没有哪个是为了获得像忠诚奖励积分或给客户发送通知这样的能力。进入单体的调用是“下订单”或“付款”。只是作为这些操作的副作用,我们可能会奖励积分或发送电子邮件。因此,我们无法在单体系统的外围拦截对忠诚奖励积分或通知的调用。那是在单体系统内部完成的。
假设我们要把通知功能提取出来。我们必须提取这块功能,并用一种增量的方式拦截这些入站链接,这样我们就不会破坏系统的其余部分。
一种名为“抽象分支”的技术可以很好地完成这项工作。在基于主干的开发环境中,抽象分支是一种经常讨论的模式,这是一种很好的软件开发方式。在这种情况下中,抽象分支作为一种模式也很有用。我们在现有的单体系统中创建了一个空间,同一功能的两种实现可以在其中共存。在很多方面,这是里氏替换原则的一个例子。这是对完全相同的抽象做的一个独立实现。对于本例,我们将从现有代码中提取通知功能。
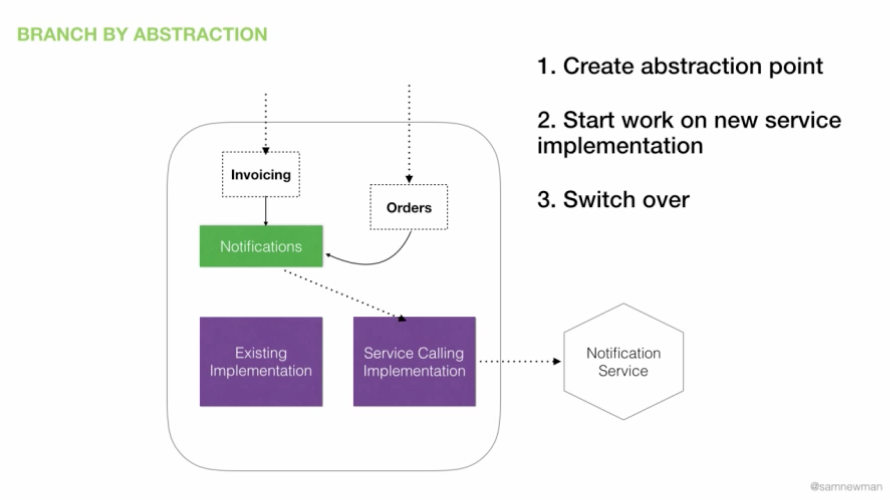
图 8:用于迁移到一个微服务的抽象分支
通知代码散布在我们的系统中。我们要做的第一件事是为新服务收集所有这些代码。我们将把服务隐藏在抽象点后面。我们希望结账代码和订单代码通过一个明确的抽象点来访问这个功能。起初,我们有一个通知抽象的实现——它封装了单体中当前所有与通知相关的功能。我们的所有调用——到 SMTP 库、到 Twilio、发送 SMS——都被打包到这个实现中。
此时,我们所做的只是在代码中创建了一个很好的抽象点。我们可以停了。我们已经厘清了我们的代码库,并使其更容易测试,这已经是改进了。这是一种很好的老式重构。我们也创造了一个机会来更改结账或订单使用的通知功能的实现。我们可以用几天或几周的时间来完成这项重构工作,同时做一些其他的事情,比如实际发布特性。
接下来,我们开始创建通知服务的新实现。这可以分成两个部分。我们已经在单体中实现了新接口,但这只是调用另一部分(新建的通知微服务)的客户端代码。部署这些实现很安全,因为它们还没有被使用。我们更频繁地集成代码,减少合并工作,并确保一切工作正常。
一旦单体内部调用新服务的代码和单体外部的通知服务可以正常工作,我们所需要做的就是切换我们正在使用的抽象实现。我们可以使用特性开关、文本文件、专用工具,或者任何我们希望使用的方式。我们还没有删除旧功能,所以如果有问题,我们可以轻松切回旧功能。同样,这个服务的迁移被分解成许多小步骤,我们试图通过所有这些步骤尽快将其部署到生产环境。
一切工作正常之后,我们就可以选择清理代码了。如果不再需要这个功能,我们可以删除其特性标识,甚或删除旧代码。现在删除旧代码很容易了,因为我们已经花了一些时间将所有代码整理好。我们删除了那个类,它消失了。我们把单体变小了,每个人都对自己感到满意。
就代码重构而言,我强烈推荐 Michael Feathers 的著作《修改代码的艺术》。他对遗留代码的定义是没有测试代码的代码。关于如何在不破坏现有系统的情况下,在代码库中找出并创建这些抽象,这本书提供了很多好主意。即使你不使用微服务,仅仅创建这个抽象点就可能会使你的代码处于更好、更可测试的状态。
我已经强调过,不要太早删除旧实现。保留两种实现有很多好处。它为我们如何部署和上线软件提供了有趣的方法。当调用进入抽象点时,它可以触发对这两个实现的调用。这叫做并行运行。这可以帮助我们确保新的微服务实现功能上等价。我们运行该功能的两个副本,然后比较结果。
要做这个比较,只需运行这两个实现并比较结果。我们必须指定其中之一作为真相来源,因为我们不希望把两者串联起来:例如,在发送通知时,我们只想发送一封邮件,结果却发了两封。并行运行是一种实用而直接的实时比较,不仅是功能等价性的比较,而且包含可接受的非功能等价性比较。我们不仅要测试是否创建了正确的电子邮件,并将其发送到正确的虚拟 SMTP 服务器,而且还要测试新服务的响应速度是否同样快,或者错误率在可接受范围之内。
通常,我们信任旧的功能实现,并使用其结果。我们将它们并行运行一段时间,如果新实现提供了可接受的结果,我们最终将处理掉旧的。
GitHub 可以帮我们做这件事。他们创建了一个名为 GitHub Scientist 的库,这是一个很小的 Ruby 库,用于封装不同的抽象并对它们进行评分。在重构应用程序中的关键代码路径时,我们可以使用它来进行实时比较。GitHub Scientist 已经被移植到了很多不同的语言上,令人费解的是,Perl 有三种不同的移植:显然,在 Perl 社区,并行运行是一件很重要的事情。关于如何在应用程序内部并行运行,已经有很多很好的建议。
从根本上说,我们需要将部署的概念与发布的概念分离开来。传统上,我们认为这两种活动是一回事,部署软件和向生产环境用户发布软件是一回事。这就是为什么每个人都害怕生产环境会发生什么事情,这就是生产环境成为一个封闭环境的原因。
我们可以把这两个概念分开。将某样东西部署到生产环境中与将它发布给我们的用户是不一样的。这个想法是人们现在所说的“渐进式交付”的基础,这是一个涵盖了一系列不同技术的总称,包括金丝雀发布、蓝 / 绿部署、抹黑启动等。我们可以快速推出软件,但不必向任何客户公开。我们可以把它放到生产环境中,在那里测试,然后自己承受出现的任何问题。
如果我们将部署与发布分开,那么部署的风险就会小很多。我们就会更加勇敢地进行更改。我们将能够更频繁地发布,而且发布的风险将更低。
RedMonk 联合创始人 James Governor 在公司的博客上对渐进式交付做了很好的阐述。该文探讨了渐进式交付,其中最重要的结论是,主动部署与主动发布不是一回事,并且你可以控制发布活动如何发生。
我们将现有的单体应用程序和数据锁定在系统中,如图 9 所示。我们已经决定提取结账功能,但是它需要访问数据。
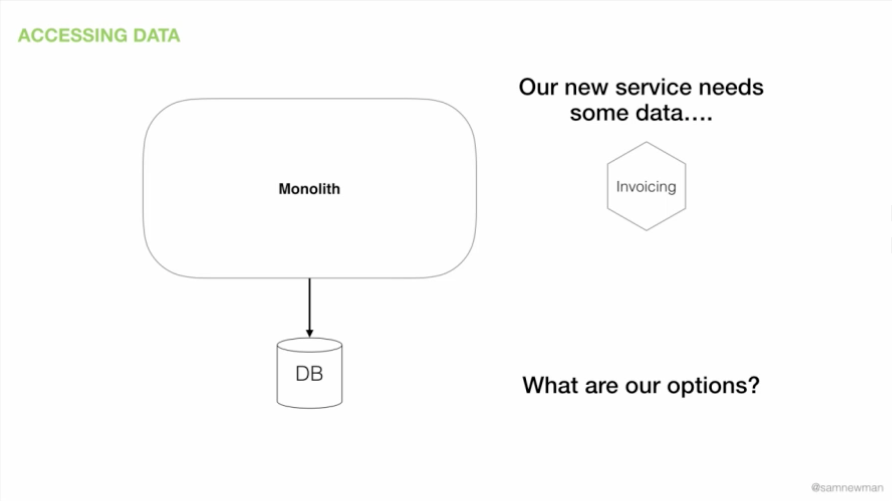
图 9:从新服务访问旧数据
选项一是直接访问单体的数据。如果我们仍然在测试并在单体中的结账功能和微服务里的结账功能之间进行切换,我们会希望这两种实现之间具有数据兼容性和一致性,这种方式可以保证这一点。这在短时间内是可以接受的,但它违背了数据库的黄金规则之一:不共享数据库。这不是可以长期依赖的东西,因为它会导致根本性的耦合问题。我们希望保持独立部署的能力。
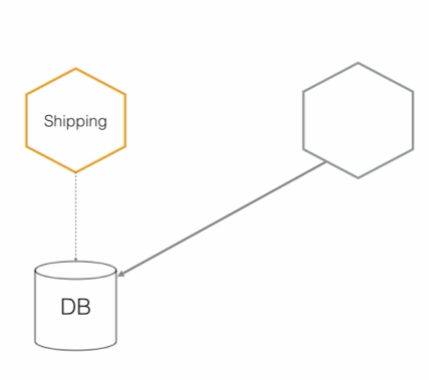
图 10:从新服务直接访问旧数据
如图 10 所示,我们有一个 Shipping 服务和数据库,我们允许其他人访问我们的数据。我们已经向外部公开了内部实现细节。这使得 Shipping 服务的开发人员很难知道哪些内容可以安全地更改。哪些数据要共享,哪些数据要隐藏,并没有做区分。
20 世纪 70 年代,David Parnas 提出了“信息隐藏”的概念,我们就是以此为基础考虑模块分解。我们希望在模块或微服务的边界内隐藏尽可能多的信息。如果我们创建一个定义良好的服务接口来共享数据,而不是直接公开数据库,那么这个接口就让 Shipping 服务的开发人员可以明确知道这个契约以及他们可以向外界公开什么。只要遵守该契约,开发人员就可以在 Shipping 服务中做任何他们想做的事情。也就是说,这些服务可以独立演进和开发。不要直接访问数据库,除非是在极其特殊的情况下。
抛开直接访问,我们有两种选择:要么访问别人的数据,要么保存自己的数据。对于这个例子,假如我们已经确定新开发的结账微服务已经足够好,可以作为我们的真相来源。
此时,如果我们想要使用别人的数据,那么这可能意味着数据属于单体,我们必须向单体请求数据。我们在单体上创建某种显式的服务接口(在我们的示例中是一个 API),通过它获取我们想要的数据。
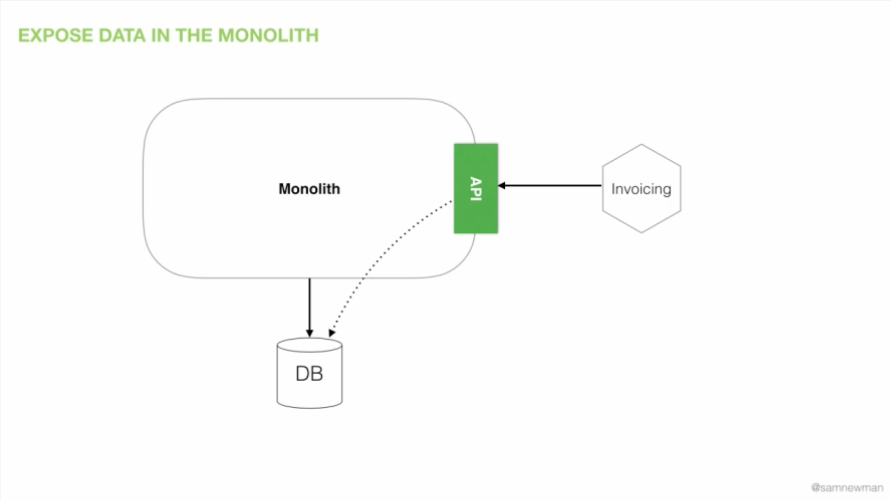
图 11:新开发的微服务使用单体显式提供的一个服务接口
我们是结账服务,而不是订单服务,但我们可能需要订单数据。订单功能存在于单体中,因此我们将从那里获取数据。这样来说,我们需要在单体上定义服务接口以公开不同的数据集,而且,在这样做时,我们可以看到其他实体从单体中显现出来。我们可能会发现,订单服务正等待着从单体中喷发出来,就像《异形》中的异形幼体,在电影中,单体是由 John Hurt 扮演的,它会死去。
另一种选择是保存服务自己的数据——在本例中,是单体数据库中的结账数据。至此,我们必须把数据移到一个结账数据库,这真的很难。从现有系统(尤其是关系数据库)中提取数据会带来很多麻烦。我们将看一个简单的例子,看看它带来的挑战。我将带大家深入了解一下,如何处理连接。
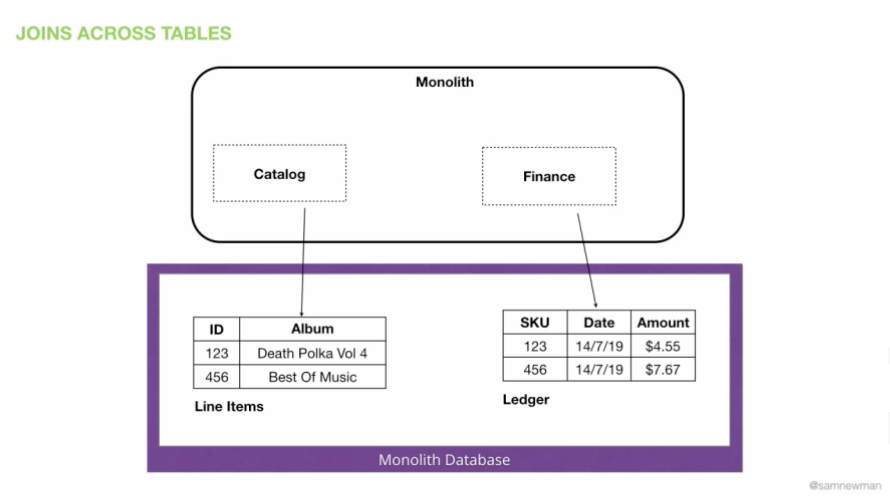
图 12:在线销售光盘的单体
图 12 描述了一个现有的、在线销售光盘的单体应用程序。(你可以看出我这个例子已经用了多久了。)Catalog 功能知道某些东西多少钱,并将信息存储在 Line Items 表中。Finance 功能管理我们的财务交易,并将数据存储在 Ledger 表中。我们要做的其中一件事是,生成一个每周销量前 10 的专辑列表。在这种情况下,我们需要做一个简单的连接操作。我们从 Ledger 表上查出 10 个最畅销的。我们根据行和其他东西来限制这个查询。这样我们就能得到 ID 列表了。
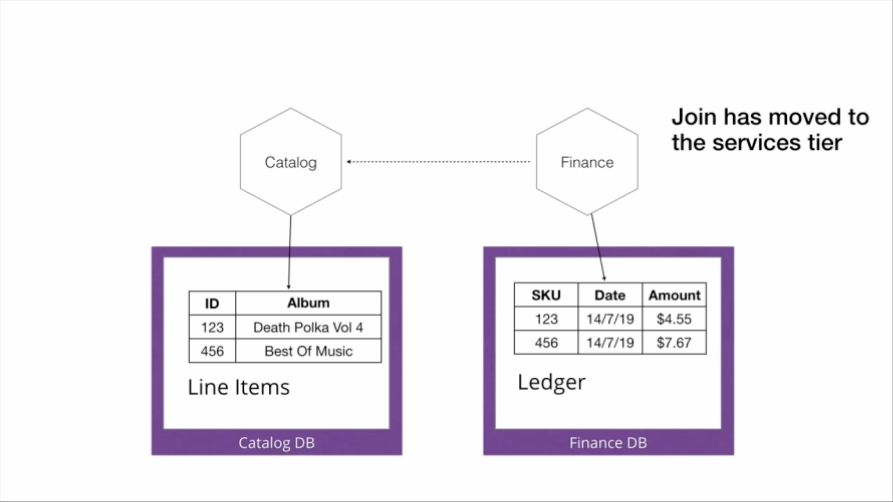
图 13:在线销售光盘的微服务架构
在进入微服务领域后,我们需要在应用层执行连接操作。我们从 Finance 数据库中提取财务交易数据。关于我们出售的物品的信息则存在于 Catalog 数据库中。为了生成销量前 10 名列表,我们必须从 Ledger 表中提取最畅销商品的 ID,然后转到 Catalog 微服务,查询所销售商品的信息。我们过去在关系层中执行的连接操作转移到了应用程序层。
延迟可能会变得令人震惊。现在,我不是做一个一次往返的连接操作,而是要调用 Finance 服务获取销量前 10 的 ID,然后调用另一个 Catalog 服务请求这 10 个 ID 的信息,然后 Catalog 服务从 Catalog 数据库中取得这些 ID,然后我们才得到响应。图 13 说明了这个过程。
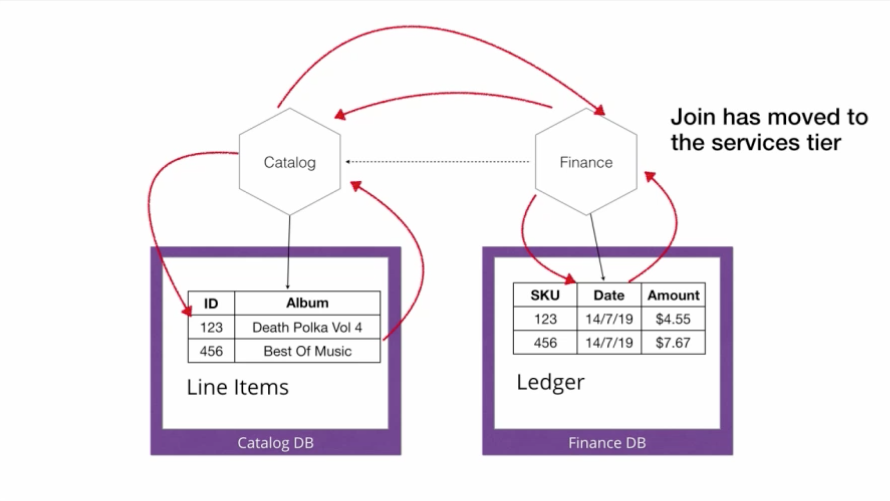
图 14:微服务架构会导致更多的跃点和延迟
我们还没有涉及到像缺乏数据完整性这样的问题(在这种情况下,关系型数据库如何实现引用完整性)。
如果你想深入研究诸如处理延迟和数据一致性之类的问题,我在《从单体到微服务》一书中进行了深入的阐述。
无论你是否决定继续自己的微服务迁移之旅,我都建议你仔细考虑下,自己正在做什么以及为什么要这样做。不要把注意力都放在创建微服务上。相反,你要清楚自己想要达到的结果。你认为微服务会带来什么结果?专注于这一点——你可能会发现,你可以在不进入复杂的微服务世界的情况下实现同样的结果。

(干货)吐血总结:技术大佬都是怎么学习的?

面试官:如何发现 Redis 热点 Key ,解决方案有哪些?