
终于有人把监督学习、强化学习和无监督学习讲明白了
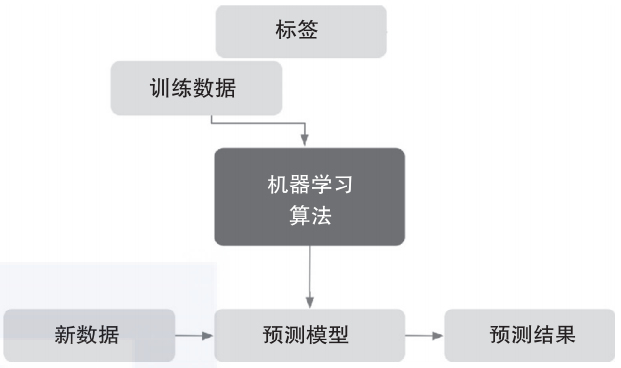
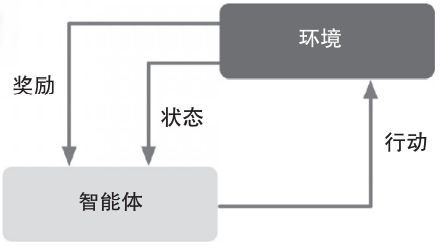
导读:本文将讨论监督学习、无监督学习和强化学习这三种类型的机器学习。

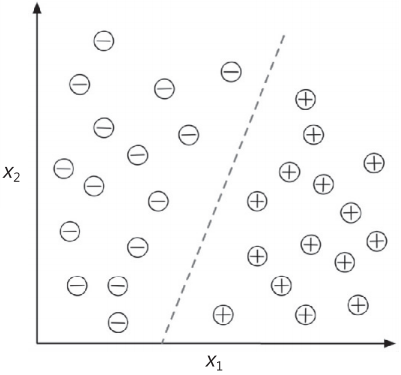
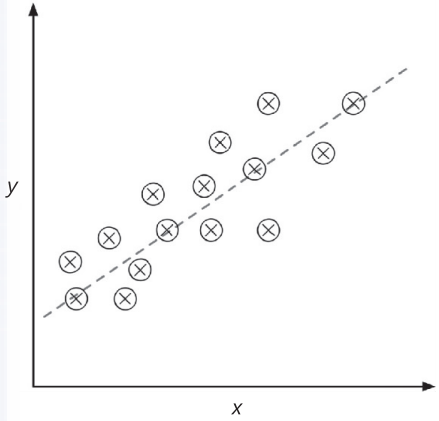
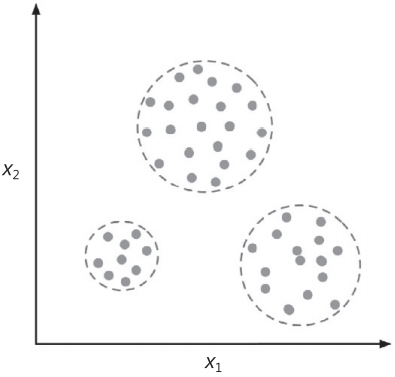
均值回归 1886年,Francis Galton在其论文Regression towards Mediocrity in Hereditary Stature中首次提到回归一词。Galton描述了一种生物学现象,即种群身高的变化不会随时间的推移而增加。
关于作者:塞巴斯蒂安·拉施卡(Sebastian Raschka),密歇根州立大学博士,他在计算生物学领域提出了几种新的计算方法,还被科技博客Analytics Vidhya评为GitHub上最具影响力的数据科学家。
瓦希德·米尔贾利利(Vahid Mirjalili),密歇根州立大学计算机视觉与机器学习研究员,致力于把机器学习应用到各种计算机视觉研究项目。他在学术和研究生涯中积累了丰富的Python编程经验,其主要研究兴趣为深度学习和计算机视觉应用。


评论