
一文读懂 | Linux 网络命名空间
1 前景回顾
1.1 Linux网络
Linux 是因特网的产物, 这是无可争议的. 首先, 得感谢因特网通信, Linux的开发过程证明了一个很多人曾持有的观点是荒谬的 : 对分散在世界各地的一组程序员进行项目管理是不可能的. 第一个内核源代码版本是在十多年前通过FTP服务器提供的, 此后网络便成了数据交换的支柱, 无论是概念和代码的开发, 还是内核错误的消除, 都是如此.
内核邮件列表是个活生生的例子, 它几乎没有改变过. 每个人都能够看到最新贡献的代码, 并为促进Linux的开发提出自己的意见, 当然, 得假定所表达的意见是合理的. Linux对各种网络适应得都很好, 这是可以理解的, 因为它是与因特网共同成长的.
在构成因特网的服务器中, 大部分是运行Linux的计算机. 不出所料, 网络实现是Linux内核中一个关键的部分, 正在获得越来越多的关注. 实际上, Linux不支持的网络方案很少.
网络功能的实现是内核最复杂、牵涉最广的一部分. 除了经典的因特网协议(如TCP、UDP)和相关的IP传输机制之外, Linux还支持许多其他的互联方案,使得所有想得到的计算机/操作系统能够互操作.
Linux也支持大量用于数据传输的硬件, 如以太网卡和令牌环网适配器及ISDN卡和调制解调器, 但这并没有使内核的工作变得简单.
尽管如此, Linux开发人员提出了一种结构良好得令人惊讶的模型, 统一了各种不同的方法. 虽然本章是本书最长的章之一, 但并没有涵盖网络实现的每个细节. 即使概述一下所有的驱动程序和协议, 也超出了一本书的范围, 由于信息量巨大, 实际上可能需要许多本书. 不算网卡驱动程序, 网络子系统的C语言实现在内核源代码中就占了15MB, 如果将相应的代码打印到纸上要有6000多页. 与网络相关的头文件的数目巨大, 使得内核开发者将这些头文件存储到一个专门的目录include/net中, 而不是存储到标准位置include/linux. 网络相关的代码中包含了许多概念, 这些形成了网络子系统的逻辑支柱, 我们在本章中最感兴趣的就是这些概念. 我们的讨论主要限于TCP/IP实现, 因为它是目前使用最广泛的网络协议.
当然, 网络子系统的开发, 并不是从头开始的. 在计算机之间交换数据的标准和惯例都已经存在数十年之久, 这些都为大家所熟知且沿用已久. Linux也实现了这些标准, 以连接到其他计算机.
1.2 网络实现的分层模型
内核网络子系统的实现与本章开头介绍的TCP/IP参考模型非常相似
相关的C语言代码划分为不同层次,各层次都有明确定义的任务,各个层次只能通过明确定义的接口与上下紧邻的层次通信。这种做法的好处在于,可以组合使用各种设备、传输机制和协议。例如,通常的以太网卡不仅可用于建立因特网(IP)连接,还可以在其上传输其他类型的协议,如Appletalk或IPX,而无须对网卡的设备驱动程序做任何类型的修改。
图12-3说明了内核对这个分层模型的实现

网络子系统是内核中涉及面最广、要求最高的部分之一。为什么是这样呢?答案是,该子系统处理了大量特定于协议的细节和微妙之处,穿越各层的代码路径中有大量的函数指针,而没有直接的函数调用。这是不可避免的,因为各个层次有多种组合方式,这显然不会使代码路径变得更清楚或更易于跟踪。此外,其中涉及的数据结构通常彼此紧密关联。为降低描述上复杂性,下文的内容主要讲述 因特网协议。
分层模型不仅反映在网络子系统的设计上,而且也反映在数据传输的方式上(或更精确地说,对各层产生和传输的数据进行封装的方式)。通常,各层的数据都由首部和数据两部分组成, 如图12-4所示。

首部部分包含了与数据部分有关的元数据(目标地址、长度、传输协议类型等),数据部分包含有用数据(或净荷)。
传输的基本单位是(以太网)帧,网卡以帧为单位发送数据。帧首部部分的主数据项是目标系统的硬件地址,这是数据传输的目的地,通过电缆传输数据时也需要该数据项。
高层协议的数据在封装到以太网帧时,将协议产生的首部和数据二元组封装到帧的数据部分。在因特网网络上,这是互联网络层数据。
因为通过以太网不仅可以传输IP分组,还可以传输其他协议的分组,如Appletalk或IPX分组,接收系统必须能够区分不同的协议类型,以便将数据转发到正确的例程进一步处理。分析数据并查明使用的传输协议是非常耗时的。因此,以太网帧的首部(和所有其他现代网络协议的首部部分)包含了一个标识符,唯一地标识了帧数据部分中的协议类型。这些标识符(用于以太网传输)由一个国际组织(IEEE)分配。
协议栈中的所有协议都有这种划分。为此,传输的每个帧开始都是一系列协议首部,而后才是应用层的数据,如图12-5所示
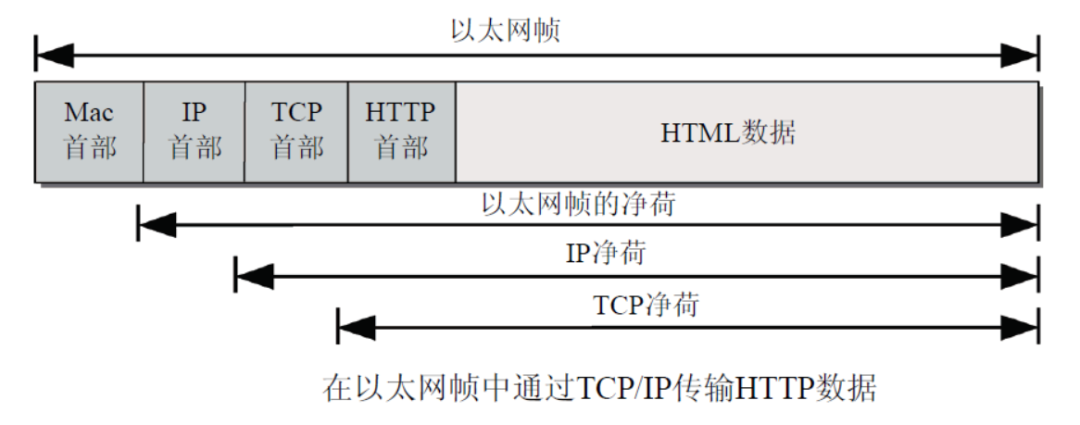
图12-5清楚地说明了为容纳控制信息所牺牲的部分带宽.
2 网络命名空间net
回想之前讲解进程调度中时我们提到了pid的命名空间, 我们知道内核的许多部分包含在命名空间中. 这可以建立系统的多个虚拟视图, 并彼此分隔开来. 每个实例看起来像是一台运行Linux的独立机器,但在一台物理机器上,可以同时运行许多这样的实例。在内核版本2.6.24开发期间,内核也开始对网络子系统采用命名空间. 这对该子系统增加了一些额外的复杂性,因为该子系统的所有属性在此前的版本中都是"全局"的,而现在需要按命名空间来管理, 例如, 可用网卡的数量. 对特定的网络设备来说,如果它在一个命名空间中可见,在另一个命名空间中就不一定是可见的.
2.1 网络命令空间net
照例需要一个中枢结构来跟踪所有可用的命名空间, 即struct net, 其定义如下:
struct net {
atomic_t passive; /* To decided when the network
* namespace should be freed.
*/
atomic_t count; /* To decided when the network
* namespace should be shut down.
*/
spinlock_t rules_mod_lock;
atomic64_t cookie_gen;
struct list_head list; /* list of network namespaces */
struct list_head cleanup_list; /* namespaces on death row */
struct list_head exit_list; /* Use only net_mutex */
struct user_namespace *user_ns; /* Owning user namespace */
spinlock_t nsid_lock;
struct idr netns_ids;
struct ns_common ns;
struct proc_dir_entry *proc_net;
struct proc_dir_entry *proc_net_stat;
#ifdef CONFIG_SYSCTL
struct ctl_table_set sysctls;
#endif
struct sock *rtnl; /* rtnetlink socket */
struct sock *genl_sock;
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
unsigned int dev_base_seq; /* protected by rtnl_mutex */
int ifindex;
unsigned int dev_unreg_count;
/* core fib_rules */
struct list_head rules_ops;
struct net_device *loopback_dev; /* The loopback */
struct netns_core core;
struct netns_mib mib;
struct netns_packet packet;
struct netns_unix unx;
struct netns_ipv4 ipv4;
#if IS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
#if IS_ENABLED(CONFIG_IEEE802154_6LOWPAN)
struct netns_ieee802154_lowpan ieee802154_lowpan;
#endif
#if defined(CONFIG_IP_SCTP) || defined(CONFIG_IP_SCTP_MODULE)
struct netns_sctp sctp;
#endif
#if defined(CONFIG_IP_DCCP) || defined(CONFIG_IP_DCCP_MODULE)
struct netns_dccp dccp;
#endif
#ifdef CONFIG_NETFILTER
struct netns_nf nf;
struct netns_xt xt;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct netns_ct ct;
#endif
#if defined(CONFIG_NF_TABLES) || defined(CONFIG_NF_TABLES_MODULE)
struct netns_nftables nft;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
struct netns_nf_frag nf_frag;
#endif
struct sock *nfnl;
struct sock *nfnl_stash;
#if IS_ENABLED(CONFIG_NETFILTER_NETLINK_ACCT)
struct list_head nfnl_acct_list;
#endif
#if IS_ENABLED(CONFIG_NF_CT_NETLINK_TIMEOUT)
struct list_head nfct_timeout_list;
#endif
#endif
#ifdef CONFIG_WEXT_CORE
struct sk_buff_head wext_nlevents;
#endif
struct net_generic __rcu *gen;
/* Note : following structs are cache line aligned */
#ifdef CONFIG_XFRM
struct netns_xfrm xfrm;
#endif
#if IS_ENABLED(CONFIG_IP_VS)
struct netns_ipvs *ipvs;
#endif
#if IS_ENABLED(CONFIG_MPLS)
struct netns_mpls mpls;
#endif
struct sock *diag_nlsk;
atomic_t fnhe_genid;
};
使网络子系统完全感知命名空间的工作才刚刚开始。读者现在看到的情况,即内核版本2.6.24中的情况,仍然处于开发的早期阶段。因此,随着网络子系统中越来越多的组件从全局管理转换为可感知命名空间的实现,struct net 的长度在未来会不断增长。现在,基本的基础设施已经转换完毕。
对网络设备的跟踪已经考虑到命名空间的效应,对最重要的一些协议的命名空间支持也是可用的。由于本书中尚未讨论网络实现的任何具体内容,struct net 中引用的结构当然还是未知的(但在本章行文过程中,这一点会逐渐改变)。现在,只需要简要地概述一下,哪些概念是以可感知命名空间的方式进行处理的即可.
count是一个标准的使用计数器,在使用特定的net实例前后,需要分别调用辅助函数get_net和put_net. 在count降低到0时,将释放该命名空间,并将其从系统中删除.
所有可用的命名空间都保存在一个双链表上,表头是net_namespace_list。list用作链表元素. copy_net_ns函数向该链表添加一个新的命名空间。在用create_new_namespace创建一组新的命名空间时,会自动调用该函数。
由于每个命名空间都包含不同的网络设备,这必然会反映到procfs的内容上(参见10.1节)。各命名空间的处理需要三个数据项:/proc/net由proc_net表示,而/proc/net/stats由proc_net_stats表示,proc_net_root指向当前命名空间的procfs实例的根结点,即/proc
每个命名空间都可以有一个不同的环回设备,而loopback_dev指向履行该职责的(虚拟)网络设备.
网络设备由struct net_device表示。与特定命名空间关联的所有设备都保存在一个双链表上,表头为dev_base_head。各个设备还通过另外两个双链表维护:一个将设备名用作散列键(dev_name_head),另一个将接口索引用作散列键(dev_index_head)。
请注意,术语“设备”和“接口”有细微的差别。设备表示提供物理传输能力的硬件设备,而接口可以是纯虚拟的实体,可能在真正的设备上实现。例如,一个网卡可以提供两个接口。对我们来说,两个术语的区别不那么重要,在下文中将交替使用这两个术语。网络子系统的许多组件仍然需要做很多工作才能正确处理命名空间,要使网络子系统能够完全感知命名空间,还有相当长的路要走。例如,内核版本2.6.25(在撰写本章时,仍处于开发中)将开始一些最初的准备工作,以便使特定的协议能够感知到命名空间:
struct net
{
/* ...... */
struct net_device *loopback_dev; /* The loopback */
struct netns_core core;
struct netns_mib mib;
struct netns_packet packet;
struct netns_unix unx;
struct netns_ipv4 ipv4;
#if IS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
/* ...... */
}
ipv4用于存储协议参数(此前是全局的), 为此引入了特定于协议的结构. 这个方 法是逐步进行的:首先设置好基本框架,后续的各个步骤,将全局属性迁移到各命名空间的表示,这些结构最初都是空的。在未来的内核版本中,还将引入更多此类代码
linux系统包括默认的命名空间 : "init_net"和用户自定义的net
我们通常说的namespace 一般是默认的命名空间 : "init_net", 也就是所有的"网络通信协议"+"网络设备"都是属于默认的命名空间.
大多数计算机通常都只需要一个网络命名空间. 即只有默认命名空间init_net(该变量实际上是全局的,并未包含在另一个命名空间中,其定义如下:
// http://lxr.free-electrons.com/source/net/core/net_namespace.c?v=4.7#L35
struct net init_net = {
.dev_base_head = LIST_HEAD_INIT(init_net.dev_base_head),
};
EXPORT_SYMBOL(init_net);
init_net会被链接到net_namespace_list这个双向链表上, 定义如下所示:
net_namespace_list就包含了所有的网络命令空间, 其以init_net为表头
LIST_HEAD(net_namespace_list);
EXPORT_SYMBOL_GPL(net_namespace_list);
2.2 初始化 & 清理元组 pernet_operations(创建命名空间)
初始化 & 清理元组pernet_operations
每个网络命名空间由几个部分组成, 例如, 在procfs中的表示. 每当创建一个新的网络命名空间时, 必须初始化这些部分. 在删除命名空间时, 也同样需要一些清理工作. 内核采用下列结构来跟踪所有必需的初始化/清理元组.
// http://lxr.free-electrons.com/source/include/net/net_namespace.h?v=4.7#L288
struct pernet_operations {
struct list_head list;
int (*init)(struct net *net);
void (*exit)(struct net *net);
void (*exit_batch)(struct list_head *net_exit_list);
int *id;
size_t size;
};
// http://lxr.free-electrons.com/source/include/net/net_namespace.h?v=4.7#L316
int register_pernet_subsys(struct pernet_operations *);
void unregister_pernet_subsys(struct pernet_operations *);
int register_pernet_device(struct pernet_operations *);
void unregister_pernet_device(struct pernet_operations *);
这个结构没什么特别之处 :
| 字段 | 描述 |
|---|---|
| list | 所有可用的pernet_operations实例通过一个链表维护,表头为pernet_list. 字段list用作链表元素 |
| init | 存储了初始化函数 |
| exit | 而清理工作由exit处理 |
内核pernet_operations结构将被链接到pernet_list这个双向链表上, 定义:
static LIST_HEAD(pernet_list);
static struct list_head *first_device = &pernet_list;
DEFINE_MUTEX(net_mutex);
辅助函数register_pernet_subsys和unregister_pernet_subsys分别向该链表添加和删除数据元素. 每当创建一个新的网络命名空间时, 内核将遍历pernet_operations的链表, 用表示新命名空间的net实例作为参数来调用初始化函数。在删除网络命名空间时,清理工作的处理是类似的
网络命令空间的创建
每个network namespace包换许多元件, 所以当一个新的network namespace被创建, 这些元件必须被初始化. 同样, 当它被删除时,需要做必要的清理工作.
Kernel引入了如下结构pernet_operations来维护所有需要做的 initialization/cleanup工作
当一个新的network namespace被创建, kernel遍历pernet_operations 的list, 即遍历pernet_list, 并调用其init函数.
在linux内核中默认情况下, 会有一个"默认的网络命名空间", 其名为init_net, 并也将其导出, 作为全局变量.
kernel2.4、2.6:通过 copy_net_ns和net_create函数向内核中添加一个网络命名空间, 其中copy_net_ns函数
// http://lxr.free-electrons.com/source/net/core/net_namespace.c?v=2.6.32#L120
// 这个函数用于向内核中添加一个网络命名空间
// struct net *net_create(void);
// 这个函数主要做了三件事 :
// 1. 通过struct net*net_alloc(void)函数分配了一个structnet结构体
// 2. 通过setup_net(struct net*ns)函数对分配的struct net结构体进行了相应的设置;
// 3. 将分配的struct net结构体加入到 net_namespace_list的双链表尾部
// http://lxr.free-electrons.com/source/net/core/net_namespace.c?v=2.6.32#L143
struct net *copy_net_ns(unsigned long flags, struct net *old_net)
{
if (!(flags & CLONE_NEWNET))
return get_net(old_net);
return net_create();
}
// 1. 如果设置了CLONE_NEWNET, 就通过net_create创建一个新的net网络命令空间
// 2. 否则的话, 返回旧的网络命令空间
kernel 3.10之后删除了 net_create 函数, 而通过 copy_net_ns函数添加一个网络命名空间。
释放一个网络命名空间
内核可以通过net_free和net_drop_ns函数来释放掉指定的网络命名空间.
定义:
static void net_free(struct net *net)
{
kfree(rcu_access_pointer(net->gen));
kmem_cache_free(net_cachep, net);
}
void net_drop_ns(void *p)
{
struct net *ns = p;
if (ns && atomic_dec_and_test(&ns->passive))
net_free(ns);
}
2.3 总结
记住下列事实就足够了
网络子系统实现的所有全局函数,都需要一个网络命名空间作为参数,而网络子系统的所有全局属性,只能通过所述命名空间迂回访问.
linux系统包括默认的命名空间 :init_net和用户自定义的netnamespace一般是默认的命名空间:init_net, 也就是所有的"网络通信协议"+"网络设备"都是属于默认的命名空间.网络命名空间定义了2个链表,
pernet_list和net_namespace_listinit_net会被链接到net_namespace_list这个双向链表上pernet_operations结构将被链接到first_device = pernet_list这个双向链表上如果没自定义网络命名空间的话,所有想用网络命名空间时都将利用默认的
init_net
3 网络命令空间设备
命名空间设备指的是那些?
就是网络设备. 通过register_pernet_device注册:就是"注册一个网络设备"到"所有的网络命名空间net", 网络设备包括两类:虚拟的网络设备和物理网络设备 :
3.1 虚拟网络设备
虚拟网络设备的协议根据自身设计特点对skb数据进行处理, 并通过全局变量xx_net_id和各个协议私有的特殊数据结构xx_net, 寻找到该数据包对应的应用层socket插口, 并将其放在该socket插口的接收队列中; 最后应用层在某个时刻会通过read系统调用读取该数据
| 设备 | 描述 | 定义 |
|---|---|---|
| pv6隧道设备 | static struct pernet_operations ip6_tnl_net_ops = {用于ipv6与iPv4之间互通 | net/ipv6/ip6_tunnel.c |
| pppoe设备 | pppoe是一个完整的协议,是从应用层到设备之间的协议模块,从这个意义上来讲,它和INET域中的协议是等价的,定义协议族:PF_PPPOX | drivers/net/ppp/pppoe.c |
| ipv4gre设备(GRE路由协议) | ||
| vti协议设备 |
3.2 物理网络设备
比如网卡驱动、无线网卡驱动
3.3 namespace与socket, 网络设备的关系
上述的socket索引方法有个绕弯的地方:就是每个协议私有的xx_net结构可以直接由协议模块本身分配,索引起来也方便,不要用到全局的net_generic。而目前内核所用的方法,其实是为了另外的目的,那就是命名空间namespace。也就是虚拟多用户的一套机制,具体的也没细看,好像目前内核整个namespace还没有全部完成。
network的命名空间问题主要在于,每个协议模块的xx_net私有结构不仅是一个,而是由内核全局决定的,即每注册一个新的用户(有点像虚拟机机制),就分配一个新的xx_net结构,这样多用户间可以用参数相同的socket连接,但却指向不同的socket, 可以看到socket的操作,都会有个net参数,就是为了这个作用,主要实现函数在namespace.c中
在Linux协议栈中引入网络命名空间,是为了支持网络协议栈的多个实例,而这些协议栈的隔离就是由命名空间来实现的(有点像进程的线性地址空间,协议栈不能访问其他协议栈的私有数据)。需要纳入命名空间的元素包括进程,套接字,网络设备。进程创建的套接字必须属于某个命名空间,套接字的操作也必须在命名空间内进行,网络设备也必须属于某个命名空间,但可能会改变,因为网络设备属于公共资源<~/include/net.h>
在内核中引入命名空间工作量非常大. 为了保持与向后兼容,网络系统在初始化的时候只初始化了一个命名空间,即init_net命名空间。所有的命名空间通过list项组织起来。每个网络设备都对应有一个命名空间。命名空间下的所有网络设备通过dev_base_head组织在一起
转自:
https://github.com/liexusong/LDD-LinuxDeviceDrivers/tree/master/study/kernel/04-net/02-net_namespace