
Redis的客户端
最近在看《Redis开发与运维》这本书,个人认为这是一本很好的 Redis 实战书籍,接下来几天将陆续更新这本书的读书笔记,仅供大家参考。
一、客户端通信协议
客户端与服务端之间的通信协议是在TCP协议之上构建的。
Redis制定了RESP(REdis Serialization Protocol,Redis序列化协议)实现客户端与服务端的正常交互。
// 客户端发送一条set hello world命令给服务端,按照 RESP 的标准,客户端需要将其序列化为如下格式(每行用\r\n分隔)
*3
$3
SET
$5
hello
$5
world
*3:set hello world 这个数组的长度
$3:表示下面的字符的长度是3,SET的长度是3
$5:hello的长度是5
$5:world的长度是5
// Redis服务端按照 RESP 将其反序列化为 set hello world,执行后
回复 OK
+OK
二、Java客户端Jedis
1、Jedis 基本用法
Java 有很多优秀的 Redis 客户端,最常用的是 Jedis 和 Redisson,Redis 官方推荐使用 Redisson,我们这里先简单介绍一下 Jedis,后面会详细用一篇文章来介绍 Redission。
Jedis jedis = null;
try {
// 生成一个 Jedis 对象,这个对象负责和指定Redis实例进行通信。
jedis = new Jedis("127.0.0.1", 6379);
// jedis执行set操作
jedis.set("hello", "world");
jedis.get("hello");
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
if (jedis != null) {
// 关闭 Jedis 连接
jedis.close();
}
}
在实际项目中,Jedis操作放在try catch finally里更加合理,一方面可以在Jedis出现异常的时候(本身是网络操作),将异常进行捕获或者抛出;另一个方面无论执行成功或者失败,都会将Jedis连接关闭掉,在开发中关闭不用的连接资源是一种好的习惯。
2、Jedis 提供了字节数组类型的参数,这样的话,当应用中涉及 Java 对象的时候,可以将 Java 对象序列化为二进制进行存储,当应用需要获取对象时,使用 get 函数将字节数组取出,然后反序列化为Java对象即可。
// key 和 value 都是字符串
public String set(final String key, String value)
public String get(final String key)
// key 和 value 都是字节数组
public String set(final byte[] key, final byte[] value)
public byte[] get(final byte[] key)
需要注意的是,和其他NoSQL数据库(例如 Memcache )的客户端不同,Jedis本身没有提供序列化的工具,也就是说开发者需要自己引入序列化的工具。
什么是序列化和反序列化?
序列化:对象 -> 字节数组(二进制)
反序列化:字节数组(二进制) -> 对象
下面我们讲解一下 Jedis(Redis的客户端) 和 protostuff(Protobuf的客户端) 二者配合使用实现 Redis 的序列化操作。Protobuf是谷歌提供的一个具有高效的协议数据交换格式工具库(类似JSON),但是 Protobuf 相比于 JSON 有更高的转化效率,时间效率和空间效率都是 JSON 的3-5倍。
1)引入 protostuff 依赖。
<protostuff.version>1.0.11</protostuff.version>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>${protostuff.version}</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>${protostuff.version}</version>
</dependency>
2)定义实体类。
// 俱乐部
public class Club implements Serializable {
private int id;
private String name;// 名称
private String info;// 描述
private Date createDate;// 创建日期
private int rank;// 排名
// getter setter
}
3)序列化工具类 ProtostuffSerializer 封装了序列化和反序列化方法。
import com.dyuproject.protostuff.LinkedBuffer;
import com.dyuproject.protostuff.ProtostuffIOUtil;
import com.dyuproject.protostuff.Schema;
import com.dyuproject.protostuff.runtime.RuntimeSchema;
import java.util.concurrent.ConcurrentHashMap;
public class ProtostuffSerializer {
private Schema<Club> schema = RuntimeSchema.createFrom(Club.class);
// 序列化方法
public byte[] serialize(final Club club) {
final LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
try {
return serializeInternal(club, schema, buffer);
} catch (final Exception e) {
throw new IllegalStateException(e.getMessage(), e);
} finally {
buffer.clear();
}
}
// 反序列化方法
public Club deserialize(final byte[] bytes) {
try {
Club club = deserializeInternal(bytes, schema.newMessage(), schema);
if (club != null ) {
return club;
}
} catch (final Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
return null;
}
private <T> byte[] serializeInternal(final T source, final Schema<T> schema, final LinkedBuffer buffer) {
return ProtostuffIOUtil.toByteArray(source, schema, buffer);
}
private <T> T deserializeInternal(final byte[] bytes, final T result, final Schema<T> schema) {
ProtostuffIOUtil.mergeFrom(bytes, result, schema);
return result;
}
}
4)测试。
ProtostuffSerializer protostuffSerializer = new ProtostuffSerializer();
Jedis jedis = new Jedis("127.0.0.1", 6379);
//序列化操作
String key = "club:1";
Club club = new Club(1, "AC", "米兰", new Date(), 1);// 定义实体对象
byte[] clubBtyes = protostuffSerializer.serialize(club);// 序列化
jedis.set(key.getBytes(), clubBtyes);
// 反序列化操作
byte[] resultBtyes = jedis.get(key.getBytes());
// [id=1, clubName=AC, clubInfo=米兰, createDate=Tue Sep 15 09:53:18 CST // 2015, rank=1]
Club resultClub = protostuffSerializer.deserialize(resultBtyes);
3、Jedis连接池
上面我们介绍的是 Jedis 的直连方式,所谓直连是指 Jedis 每次都会新建 TCP 连接,使用后再断开连接,对于频繁访问 Redis 的场景显然不是高效的使用方式。
生产环境中一般使用连接池的方式对Jedis连接进行管理,所有Jedis对象预先放在池子中(JedisPool),每次要连接Redis,只需要从池子中拿来就用,用完了再归还给池子。
直连方式和连接池方式的对比见下表:
| 优点 | 缺点 | |
|---|---|---|
| 直连 | 简单方便,适用于少量长期连接的场景 | 1)存在每次新建/关闭TCP连接的开销。 2)无法限制 Jedis 对象的个数,在极端情况下可能会造成连接泄露。 3)Jedis 对象线程不安全。 |
| 连接池 | 1)无需每次连接都生成 Jedis 对象,降低开销。2)使用连接池的形式可以有效地保护和控制连接资源的使用。 | 相对于直连,使用相对麻烦,尤其在资源的管理上需要很多参数来保证,一旦规划不合理就会出现问题。 |
// 使用 common-pool(Apache 的通用对象池工具) 作为资源的管理工具(连接池配置)
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// 设置最大连接数为默认值的5倍
poolConfig.setMaxTotal(GenericObjectPoolConfig.DEFAULT_MAX_TOTAL * 5);
poolConfig.setMaxIdle(GenericObjectPoolConfig.DEFAULT_MAX_IDLE * 3);
// 设置连接池没有连接后客户端的最大等待时间(单位为毫秒)
poolConfig.setMaxWaitMillis(3000);
// 初始化Jedis连接池
JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);
Jedis jedis = null;
try {
// 1. 从连接池获取jedis对象
jedis = jedisPool.getResource();
// 2. 执行操作
jedis.set("hello", "world");
jedis.get("hello");
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
if (jedis != null) {
// 如果使用JedisPool,close操作不是关闭连接,代表归还连接池 jedis.close();
}
}
三、管理客户端的命令
1、client list 命令
在Redis实例上执行 client list 命令,就可以查看与该 Redis 实例相连的所有客户端的信息,返回的信息包括:
127.0.0.1:6379> client list
id=254487 addr=10.2.xx.234:60240 fd=1311 name= age=8888581 idle=8888581 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=300210 addr=10.2.xx.215:61972 fd=3342 name= age=8054103 idle=8054103 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=5448879 addr=10.16.xx.105:51157 fd=233 name= age=411281 idle=331077 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=ttl
id=2232080 addr=10.16.xx.55:32886 fd=946 name= age=603382 idle=331060 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=7125108 addr=10.10.xx.103:33403 fd=139 name= age=241 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=del
id=7125109 addr=10.10.xx.101:58658 fd=140 name= age=241 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=del
......
每一行代表一个客户端的信息,理解这些信息对于Redis的开发和运维人员非常有帮助,下面我们对一些重要的信息进行说明。
1)客户端标识
id:客户端唯一标识,随着Redis的连接自增,重启 Redis后会重置为0。
addr:客户端的ip和端口。
name:客户端的名字。
2)输入缓冲区和输出缓冲区的相关信息
a)什么是输入缓冲区和输出缓冲区?
Redis 为每个客户端分配了输入缓冲区和输出缓冲区,缓冲区的作用是,在客户端和 Redis 之间进行通信时,用来暂存客户端发送的命令,或者是 Redis 返回给客户端的命令执行结果,起到一个缓冲的功能。

b)使用 client list命令,查看输入缓冲区的内存使用情况。
输入缓冲区:client list 命令的返回结果 qbuf 和 qbuf-free 分别代表输入缓冲区的总容量和剩余容量。
输出缓冲区:实际上输出缓冲区由两部分组成,分别是固定缓冲区(16KB)和动态缓冲区,其中固定缓冲区用于暂存比较小的执行结果,而动态缓冲区用于暂存比较大的结果,例如大的字符串、hgetall、smembers等命令的结果。client list命令的返回结果中,obl代表固定缓冲区的长度,oll代表动态缓冲区列表的长度,omem代表输出缓冲区已经使用的字节数。
c)输入缓冲区溢出。
c.1)、输入缓冲区溢出,有什么危害?
一旦输入缓冲区溢出,可能会产生数据丢失、键值淘汰、Redis OOM、客户端关闭的情况。
c.2)、输入缓冲区溢出的原因?
(1)、因为Redis的处理速度跟不上输入缓冲区的输入速度,并且每次进入输入缓冲区的命令包含了大量 bigkey,从而造成了输入缓冲区过大的情况。
(2)、Redis发生了阻塞,短期内不能处理命令,造成客户端输入的命令积压在了输入缓冲区,造成了输入缓冲区过大。
c.3)、如何避免输入缓冲区溢出?
(1)、输入缓冲区的上限阈值为1GB,输入缓冲区根据输入内容大小的不同动态调整,不能通过参数调整。
(2)、为了防止输入缓冲区溢出,首先在代码里设置客户端输入缓冲区大小上限阈值为1GB,其次,避免客户端写入bigkey。
(3)、监控输入缓冲区,一旦超过某个值就进行报警提示。info clients 命令返回的 client_biggest_input_buf 表示当前Redis中最大的输入缓冲区,可以设置它超过10M就进行报警。
127.0.0.1:6379> info clients
client_biggest_input_buf:2097152
......
d)、输出缓冲区溢出。
d.1)、输出缓冲区溢出,有什么危害?
和输入缓冲区溢出一样,一旦输出缓冲区溢出,也可能会产生数据丢失、键值淘汰、Redis OOM、客户端关闭的情况。
d.2)、输出缓冲区溢出的原因?
(1)、bigkey 操作,导致服务器端返回的数据太大。
(2)、在 Redis 高并发场景下,执行了 monitor 命令。
(3)、缓冲区大小设置得不合理。
d.3)、如何避免输出缓冲区溢出?
与输入缓冲区不同的是,输出缓冲区的容量可以通过参数 client-outputbuffer-limit 来进行设置,当输出缓冲区大小超过设置的值,连接就会自动断开。
(1)、避免 bigkey 操作一次性返回大量数据,可以使用 scan 命令,分批次返回小量数据。
(2)、monitor 命令主要用在调试环境中,不要在生产环境中使用 monitor。
monitor命令用于监听当前Redis正在执行的命令,一旦Redis的并发量过大,此时 Redis 中正在执行的命令数量巨大,此时如果执行 monitor 命令,会将 Redis 中正在执行的所有命令写入输出缓冲区,导致客户端的输出缓冲区暴涨甚至溢出。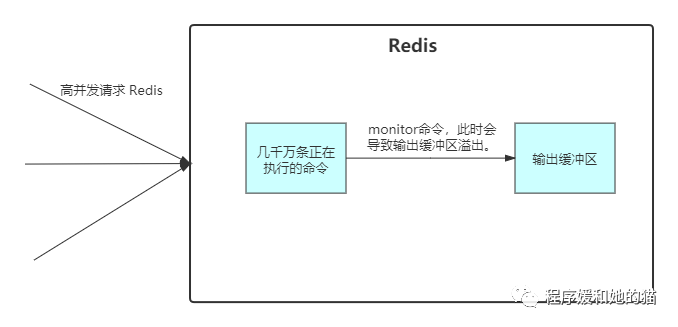
(3)、使用 client-outputbuffer-limit 设置合理的缓冲区大小上限。
// class:客户端类型,分为三种,normal:普通客户端,slave:slave客户端,用于主从之间复制,pubsub:发布订阅客户端。
// hard limit:如果客户端使用的输出缓冲区大于hard limit,客户端会被立即关闭。
// soft limit和soft seconds:如果客户端使用的输出缓冲区超过了soft limit并且持续了soft limit秒,客户端会被立即关闭。
client-output-buffer-limit [class] [hard limit] [soft limit] [soft seconds]
(4)、主从复制的场景,如何避免 Redis 主节点输出缓冲区发生溢出?
如果在主从复制的过程中,Redis 主节点的输出缓冲区发生溢出,那么所有 slave 节点的连接都将被kill,而造成复制重连,之前同步的都白费了,效率降低。
如何避免 Redis 主节点输出缓冲区发生溢出,有三个出发点:
使用 client-outputbuffer-limit,将 Redis 主节点的输出缓冲区设置地大一点。
控制和主节点连接的从节点个数。
控制主节点保存的数据量大小,通常控制在2~4GB。
3)客户端存活状态:age、idle
age:表示当前客户端已经连接了多长时间,idle:表示当前客户端已经空闲多长时间了。
见 1 中 client list 返回信息的第一条记录,当前客户端连接Redis的时间为 8888581 秒,空闲了 8888581 秒,这属于不太正常的情况,因为当 age 等于 idle 时,说明连接一直处于空闲状态,Redis能连多少客户端是有限制的,这样的空闲连接属于对 Redis 资源的一种浪费。
2、info clients 命令
使用 info clients 命令可以查看当前已经连接上 Redis 的客户端的数量。每个客户端都有一个输入缓存和输出缓存,使用 info clients 命令可以获得所有客户端中最大的输入缓存和输出缓存分别是多大。
127.0.0.1:6379> info clients
// connected_clients : 已连接客户端的数量
connected_clients:1414
// 当前连接的客户端当中,最长的输出列表,即最大的输出缓存
client_longest_output_list
// 当前连接的客户端当中,最大的输入缓存
client_longest_input_buf
3、monitor 命令
monitor 命令用于监听当前 Redis 正在执行的命令。
127.0.0.1:6379> monitor
OK
// 1378822105.089572 是时间戳,[0 127.0.0.1:56604] 中的 0 是数据库号码,127... 是 IP 地址和端口,"SET" "msg" "hello world" 是被执行的命令。
1378822105.089572 [0 127.0.0.1:56604] "SET" "msg" "hello world"
1378822109.036925 [0 127.0.0.1:56604] "SET" "number" "123"
1378822140.649496 [0 127.0.0.1:56604] "SADD" "fruits" "Apple" "Banana" "Cherry"
1378822154.117160 [0 127.0.0.1:56604] "EXPIRE" "msg" "10086"
1378822257.329412 [0 127.0.0.1:56604] "KEYS" "*"
4、client kill 命令
client kill 命令用于杀掉指定IP地址和端口的客户端。
// ip:客户端的IP,port:客户端的端口号。
client kill ip:port
// 客户端列表,127.0.0.1:55593 和 127.0.0.1:52343
127.0.0.1:6379> client list
id=49 addr=127.0.0.1:55593 fd=6 name= age=9 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
id=50 addr=127.0.0.1:52343 fd=7 name= age=4 idle=4 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
// 杀掉127.0.0.1:52343这个客户端
127.0.0.1:6379> client kill 127.0.0.1:52343
OK
// 此时客户端列表,只剩下了127.0.0.1:55593这个客户端
127.0.0.1:6379> client list
id=49 addr=127.0.0.1:55593 fd=6 name= age=9 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
由于一些原因(例如设置timeout=0时产生的长时间空闲的客户端),需要手动杀掉客户端连接时,可以使用client kill命令。
四、管理客户端的参数配置
1、客户端相关配置参数
maxclients:最大客户端连接数,即 Redis 最多能连接多少个客户端,一旦连接数超过 maxclients,新的连接将被拒绝。maxclients默认值是10000。
timeout:连接的最大空闲时间,客户端与 Redis 建立连接,如果这个连接的空闲时间(idle)超过了timeout,连接就会断开,客户端就会被关闭。如果设置为0,那么不管连接空闲多久,都不会自动断开。
在开发和运维过程中,建议将timeout设置成大于0,防止由于客户端使用不当或
者客户端本身的一些问题,造成没有及时释放客户端连接,从而造成大量的空闲连
接占据着很多连接资源,一旦超过maxclients,后果将不堪设想。
tcp-keepalive:检测 Redis 与客户端之间 TCP 连接活性的周期,即每隔多久对 TCP 活性进行一次检测。默认值为0,也就是不进行检测,如果需要设置,建议设置为60,那么 Redis 会每隔60秒对它创建的 TCP 连接进行活性检测,防止大量死连接占用系统资源。
tcp-backlog:Redis 与客户端进行 TCP 三次握手后,会将接受的连接放入内部的队列中,tcpbacklog就是队列的大小,它在Redis中的默认值是511。
2、如何获取和修改客户端配置参数?
使用 config get 参数名,来获取已经配置好的参数值,使用 config set 参数名 参数值,对客户端参数进行动态配置。
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "10000"
127.0.0.1:6379> config set maxclients 50
OK
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "50"
五、客户端常见异常
在 Redis 客户端的使用过程中,无论是客户端使用不当还是 Redis 服务端出现 问题,客户端会反应出一些异常。下面我们分析一下 Jedis 使用过程中常见的异常情况。
1、无法从连接池获取到连接
(1)、两种异常情况
第一种情况:JedisPool 中的 Jedis 对象个数是有限的(默认是 8 个),如果 JedisPool 中所有的 Jedis 对象都已经被占用,此时来了一个客户端要从 JedisPool 中借用Jedis,就需要进行等待,等待时长为 maxWaitMillis (连接池设置参数),如果在 maxWaitMillis 时间内,该客户端仍然无法获取到 Jedis 对象,就会抛出如下异常:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
......
Caused by: java.util.NoSuchElementException: Timeout waiting for idle object at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:449)
第二种情况:连接池设置了 blockWhenExhausted=false(blockWhenExhausted,当连接池中所有连接都被占用的时候,当有客户端想要获取连接时是否阻塞,false:不阻塞直接报异常,ture:阻塞直到超时,默认是 true),那么客户端发现连接池中没有资源时,会立即抛出异常不进行等待。
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
......
Caused by: java.util.NoSuchElementException: Pool exhausted at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:464)
(2)、造成连接池没有资源的原因
a)客户端方面的原因:
1、高并发情况下连接池设置过小,供不应求。但是正常情况下只要比默认的最大连接数(8个)多一些即可,因 为正常情况下JedisPool以及Jedis的处理效率足够高。
2、客户端没有正确使用连接池,比如没有及时释放连接资源。
3、客户端存在慢查询操作,这些慢查询持有的 Jedis 对象归还速度会比较慢,造成连接池中没有连接可用。
b)服务端方面的原因:
客户端是正常的,但是 Redis 服务端由于一些原因,造成了客户端的命令在执行过程中发生阻塞,导致连接不能及时还回去。
比如 RDB 持久化时,fork 进程做内存快照,AOF 持久化时,AOF 文件重写,这些操作会占用大量的CPU资源,进而拖慢客户端命令。
2、客户端读写超时
(1)、读写超时异常情况
在使用 Jedis 调用 Redis 时,如果出现了读写超时,会报如下异常:
// 程序报下述的错误信息,就表示当前发生客户端读写超时异常了。
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: Read timed out
(2)、造成超时异常的原因
1、读写超时时间设置得过短。
2、命令本身就比较慢。
3、客户端与服务端之间网络不正常。
4、由于某些原因,Redis自身发生阻塞。
3、客户端连接超时
(1)、连接超时异常情况
在使用 Jedis 连接 Redis 的时候,如果出现连接超时,会报如下异常:
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: connect timed out
(2)、造成连接超时的原因
1、连接超时时间设置得过短,可以通过下面代码进行设置:
// 毫秒
jedis.getClient().setConnectionTimeout(time);
2、Redis发生阻塞,造成 tcp-backlog 已满,造成新的连接失败,tcp-backlog 的含义见 四.1 。
3、客户端与服务端之间网络不正常。
4、客户端数据流异常
(1)、客户端数据流异常
// 数据流意外结束。
redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
(2)、造成客户端数据流异常的原因
1、输出缓冲区溢出。
2、长时间闲置的连接被服务端主动断开了。
3、不正常并发读写,Jedis 对象同时被多个线程并发操作,可能会出现上述异常。
5、Jedis调用Redis时,如果Redis正在加载持久化文件,此时客户端也会报错。
redis.clients.jedis.exceptions.JedisDataException: LOADING Redis is loading the dataset in memory
6、Redis使用的内存超过了 maxmemory 限制,客户端会报错。
redis.clients.jedis.exceptions.JedisDataException: OOM command not allowed when used memory > 'maxmemory'.
这个异常的解决方案是,调整 maxmemory 大小并找到造成内存增长的原因。
7、Redis 连接的客户端数量已经达到 maxclients 限制,此时新来的客户端尝试连接 Redis 会报错。
(1)、Redis 客户端连接数过大报异常的情况
// 已达到最大客户端数
redis.clients.jedis.exceptions.JedisDataException: ERR max number of clients reached
此时新的客户端连接执行任何命令,返回结果都是如下:
127.0.0.1:6379> get hello
(error) ERR max number of clients reached
六、客户端发生异常案例分析
1、Redis内存陡增
1)现象
服务端现象:Redis 主节点内存陡增,几乎用满 maxmemory ,而从节点内存并没有变化。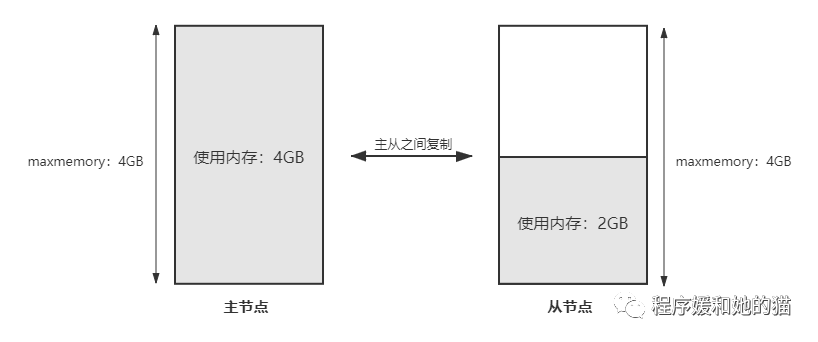
客户端现象:客户端产生了 OOM 异常,也就是说 Redis 主节点使用的内存 已经超过了 maxmemory 的设置,无法再写入新的数据。
2)分析原因
首先查看是否是主从复制出现问题导致主从不一致。
// 主节点的键个数
127.0.0.1:6379> dbsize
(integer) 2126870
// 从节点的键个数
127.0.0.1:6380> dbsize
(integer) 2126870
我们可以看到主从节点键个数一样,可以说明复制是正常的,主从数据基本一致。
其次排查是否是由客户端缓冲区(输入缓冲区和输出缓冲区)溢出,造成主节点内存陡增的。
127.0.0.1:6379> info clients
connected_clients:1891
client_longest_output_list:225698
client_biggest_input_buf:0 blocked_clients:0
很明显输出缓冲区不太正常,最大的客户端输出缓冲区队列已经超过了 20 万个对象了。
因为 client list 命令返回的 omem 表示输出缓冲区使用的字节数(一般来说大部分客户端的 omem 为0,因为处理速度会足够快),所以我们通过 client list命令,可以找到输出缓冲区溢出的那个客户端。
redis-cli client list | grep -v "omem=0"
这样我们就找到了输出缓冲区溢出的客户端,客户端标识:id 为7,IP 和端口为10.10.xx.78:56358,通过 cmd=monitor ,可以知道输出缓冲区溢出是由于执行了 monitor 命令。
id=7 addr=10.10.xx.78:56358 fd=6 name= age=91 idle=0 flags=O db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=224869 omem=2129300608 events=rw cmd=monitor
3)处理方法和后期处理
当发生内存陡增问题时,在当下为了快速恢复业务,只要使用 client kill 命令杀掉这个连接,让其他客户端恢复正常写数据即可。
但是更为重要的是在日后如何及时发现和避免这种问题的发生,基本有三点:1、禁止monitor命令,例如使用rename-command命令重置 monitor命令为一个随机字符串。
2、使用 client-outputbuffer-limit 限制输出缓冲区的大小,使得当输出缓冲区大小超过设置的值时,连接就会自动断开。
3、尽量不要使用 smembers、hgetall、lrange 等返回大量数据结果的命令,避免输出缓冲区溢出。
4、使用专业的 Redis 运维工具,在发生内存陡增时能够及时接受到报警信息,快速发现和定位问题。
2、客户端周期性的超时
1)现象
客户端现象:客户端出现大量超时,经过分析发现超时是周期性出现的,这为问题的查找提供了重要依据。
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: connect timed out
服务端现象:服务端并没有明显的异常,只是有一些慢查询操作。
2)分析原因
首先排查是否是网络原因,经过排查网络没有问题。
再排查是否 Redis 自身出现问题,经过观察Redis日志统计,并没有发现异常。
最后排查是否是客户端的问题,由于超时是周期性出现的,所以将发生超时的时间点和慢查询日志的时间点对比了一下,发现只要慢查询出现,客户端就会产生大量连接超时,两个时间点基本一致。


所以可以断定,这个问题是慢查询操作造成的。查看代码,发现代码中有个定时任务,每 5 分钟对 user_fan_hset_sort 这个 key 执行一次 hgetall 操作,而使用 hlen 发现 user_fan_hset_sort 这个 key 对应的 value 中有 200 万个元素,执行 hgetall 必然导致阻塞。
127.0.0.1:6399> hlen user_fan_hset_sort
(integer) 2883279
3)处理方法和后期处理
从开发层面,尽量避免慢查询操作,类似 smembers、hgetall、lrange 这些 O(n) 的操作。
从运维层面,监控慢查询,一旦超过阀值,就发出报警。