
记一次elasticsearch 跨机房迁移
目标将A机房的ES集群迁移到B机房的ES集群
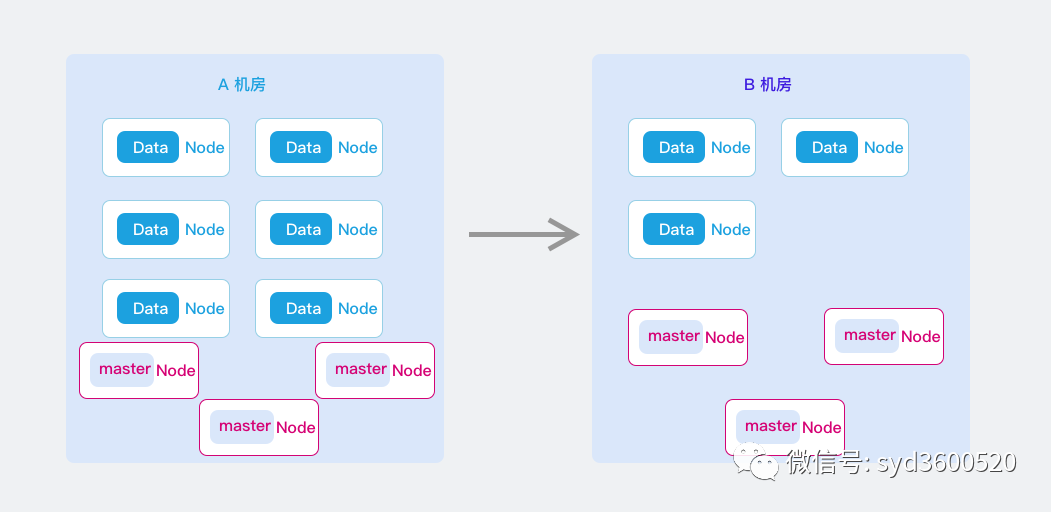
调研了在线和离线迁移两种比较有代表性的方案,两种方案都进行了测试演练,不过最终选择了离线的方式,原因有几点:
在线迁移方式仍然会存在短暂的服务不可用 数据丢失无法容忍 虽然可以配以辅助方案解决 但是增加了复杂度 在线迁移方式操作相对复杂 集群数据量几百G并不大 离线操作可以到达稳定 快速
在线迁移
思路:通过集群扩容的方式加入B机房ES节点,通过缩容的方式去掉A机房节点,始终保持一个集群原则,分片在集群内部进行迁移,集群及索引配置不更改,对业务友好;
影响:存在两次master选举 短暂时间集群不可用 每次选举时长 网上都说不超过2分钟(但是实测超过2min);
1.在A机房ES集群扩容节点,将新节点全部加入到A机房ES集群,此时B机房和A机房共同组成新的跨机房集群;
限制已有索引数据的分布范围,暂时只容许分布在旧的数据节点上
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable":"none"
"cluster.routing.rebalance.enable":"none"
"cluster.routing.allocation.include._name" : "A机房节点"
}
}'
cluster.routing.allocation.enable 设置成none,主要是影响集群中新创建的索引无法进行分片分配(把分片分配到某个节点上去)。cluster.routing.rebalance.enable设置成none, 主要是影响集群中已有索引的分片不会rebalance到(迁移)其他节点上去
B机房的ES配置 elasticsearch.yml
cluster.name: xxx #A B机房集群保持一致
discovery.seed_hosts: ["A机房IP", "B机房IP"]
启动B机房ES节点
2.在集群内部迁移A机房data节点上的分片到B机房的data节点上,此时集群中所有数据分片都在B机房的data节点上; 执行RESTful API迁移分片:
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.include._name" : "B机房节点"
}
}'
3.更改ES客户端配置文件中“data.elasticsearch.cluster-nodes”,去掉A机房的节点配置,改成B机房的master节点(tcp端口),然后客户端实例灰度重启并生效配置;
4.下线A机房的节点,再下线A机房的副master节点,最后下线A机房的主master节点,此时集群会进入master节点重新选举,且新的主master节点一定会在B机房的master节点中产生,此时集群会有短暂的不可访问;
5.去掉B机房master、data节点配置文件中的A机房节点配置,逐个重启data节点,再重启副master节点,最后重启主master节点(集群也会短暂不可访问时间)后全部生效,等待ES集群再次恢复;
discovery.seed_hosts: ["B机房IP"]
只留B机房的master节点
6.B机房的客户端访问均正常后,下线A机房的master、data节点
7.重新启动集群平衡
#禁用集群新创建索引分配
cluster.routing.allocation.enable:true
#禁用集群自动平衡
cluster.routing.rebalance.enable:true
此时整个迁移任务完毕。
检查node中的切片数量
$ curl http://localhost:9200/_cat/allocation?v
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node
3 622.5mb 655.4mb 1.7tb 1.7tb 0 10.1.11.43 10.1.11.43 node-e
3 932.3mb 965.4mb 1.7tb 1.7tb 0 10.1.11.44 10.1.11.44 node-f
0 0b 32.5mb 1.7tb 1.7tb 0 10.1.11.25 10.1.11.25 node-a
2 309.8mb 394.4mb 1.7tb 1.7tb 0 10.1.11.27 10.1.11.27 node-d
确认分片数量为0后,即可登入到需要扩容节点的系统中停止elasticsearch服务并关机。
离线迁移
1.创建索引
因动态配置无法生效 需采用手动创建索引
curl -H "Content-Type: application/json" -XPUT 'http://localhost:9200/my_index' -d '{
"settings":{
"index" : {
"search" : {
"slowlog" : {
"level" : "info",
"threshold" : {
"fetch" : {
"warn" : "1s",
"trace" : "2000ms",
"debug" : "5000ms",
"info" : "20ms"
},
"query" : {
"warn" : "10s",
"trace" : "5000ms",
"debug" : "2s",
"info" : "5000ms"
}
}
}
},
"refresh_interval" : "10s",
"sort" : {
"field" : "ActiveTime",
"order" : "desc"
},
"store" : {
"preload" : [
"nvd",
"dvd",
"tim",
"dim"
]
},
"number_of_replicas" : "1"
}
},
"mappings":{"properties":{"ActiveTime":{"type":"integer"}}}
}'
数据同步
#mappings
./node-v10.13.0-linux-x64/bin/elasticdump --input=http://A机房IP:9200/index_1 --output=http://B机房IP:9200/index_1 --type=mapping
#data
./node-v10.13.0-linux-x64/bin/elasticdump --input=http://A机房IP:9200/index_1 --output=http://B机房IP:9200/index_1 --type=data --limit=10000
#alias
./node-v10.13.0-linux-x64/bin/elasticdump --input=http://A机房IP:9200/new_index_3/alias_index_1 --output=http://B机房IP:9200 --type=alias
需要注意的是,这里我们A,B机房网络打通了 所以不用将数据导出,然后再导入,直接进行数据搬迁
数据迁移时可以通过指定--limit来进行加速,但如果数据量过大可能会遇到413 Request Entity Too Large的异常,不过不用担心:
在elasticsearch.yml配置文件加入http.max_content_length: 300mb来调整数据传输大小限制。注意此配置需要重启实例才能生效