
一文读懂CV中的注意力机制
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文配合相关的论文,讲述了多种CV注意力机制(Non-local Neural Networks、Squeeze-and-Excitation Networks、CBAM、DANet)的概念、特点以及相关实验。
Non-local ~ SE ~ CcNet ~ GC-Net ~ Gate ~ CBAM ~ Dual Attention ~ Spatial Attention ~ Channel Attention ~ ...
【只要你能熟练的掌握加法、乘法、并行、串行四大法则,外加知道一点基本矩阵运算规则(如:HW * WH = HH)和sigmoid/softmax操作,那么你就能随意的生成很多种注意力机制】
空间注意力模块 (look where) 对特征图每个位置进行attention调整,(x,y)二维调整,使模型关注到值得更多关注的区域上。 通道注意力模块 (look what) 分配各个卷积通道上的资源,z轴的单维度调整。
论文:https://arxiv.org/abs/1711.07971v1
计算机视觉领域注意力机制的开篇之作。提出了non-local operations,使用自注意力机制建立远程依赖。- local operations: 卷积(对局部领域)、recurrent(对当前/前一时刻)等操作。- non-local operations用于捕获长距离依赖(long-range dependencies),即如何建立图像上两个有一定距离的像素之间的联系,如何建立视频里两帧的联系,如何建立一段话中不同词的联系等。Non-local operations 在计算某个位置的响应时,是考虑所有位置 features 的加权——所有位置可以是空间的,时间的,时空的。
1. Non-local 定义
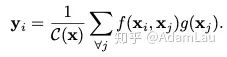
其中x表示输入信号(图片,序列,视频等,也可能是它们的features),y表示输出信号,其size和x相同。f(xi,xj)用来计算i和所有可能关联的位置j之间pairwise的关系,这个关系可以是比如i和j的位置距离越远,f值越小,表示j位置对i影响越小。g(xj)用于计算输入信号在j位置的特征值。C(x)是归一化参数。理解: i 代表的是当前位置的响应,j 代表全局响应,通过加权得到一个非局部的响应值。
Non-Local的优点是什么?
提出的non-local operations通过计算任意两个位置之间的交互直接捕捉远程依赖,而不用局限于相邻点,其相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息。 non-local可以作为一个组件,和其它网络结构结合,经过作者实验,证明了其可以应用于图像分类、目标检测、目标分割、姿态识别等视觉任务中,并且效果有不同程度的提升。 Non-local在视频分类上效果很好,在视频分类的任务中效果可观。
论文中给了通用公式,然后分别介绍f函数和g函数的实例化表示:
g函数:可以看做一个线性转化(Linear Embedding)公式如下:
是需要学习的权重矩阵,可以通过空间上的1×1卷积实现(实现起来比较简单)。
f函数:这是一个用于计算i和j相似度的函数,作者提出了四个具体的函数可以用作f函数。
1.Gaussian function 2. Embedded Gaussian 3. Dot product 4. Concatenation
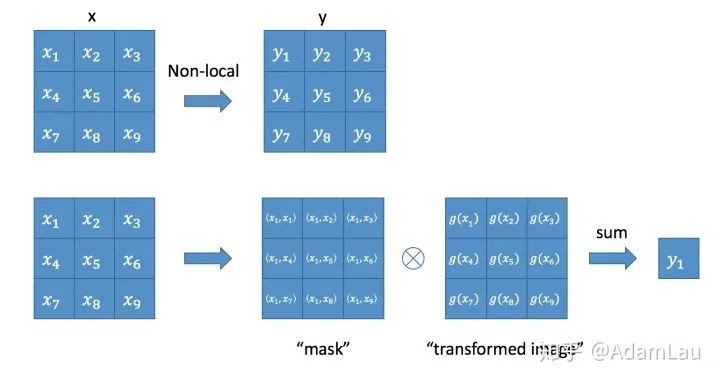
2. Non-local block
实际上是一个卷积操作,它的输出channel数跟x一致。这样以来,non-local操作就可以作为一个组件,组装到任意卷积神经网络中。
3. 实验
文中提出了四个计算相似度的模型,实验对四个方法都进行了实验,发现了这四个模型效果相差并不大,于是有一个结论:使用non-local对baseline结果是有提升的,但是不同相似度计算方法之间差距并不大,所以可以采用其中一个做实验即可,文中用embedding gaussian作为默认的相似度计算方法。 作者做了一系列消融实验来证明non local NN的有效性: 对比四个计算相似度模型,并无太大差异; 以Resnet50为例:对比non-local模块加在不同stage下的结果,在2,3,4stage处提高较大,可能由于第五层空间信息较少; 对比加入non-local模块数量的结果,越多性能越好,但速度越慢;作者认为这是因为更多的non-local block能够捕获长距离多次转接的依赖。信息可以在时空域上距离较远的位置上进行来回传递,这是通过local models无法实现的; 时间、空间及时空域上做non-local,效果均有提升; non-local VS 3D卷积,non-local更有效率,且性能更好; non-local和3D conv是可以相互补充的; 更长的输入序列,所有模型在长序列上都表现得更好。
论文:https://arxiv.org/abs/1709.01507
很多前面的工作都提出了以空间维度提升网络的性能,比如inception结构获取不同感受野信息、inside-outside结构更多考虑上下文信息、空间注意力机制等。是否有其他层面去提升性能??
SENet是首个提出从channel-wise层面提出Squeeze-and-Excitation模块的通道注意力机制,可以自适应调整各通道的特征响应值。
网络应用于分类,如何应用到分割上?
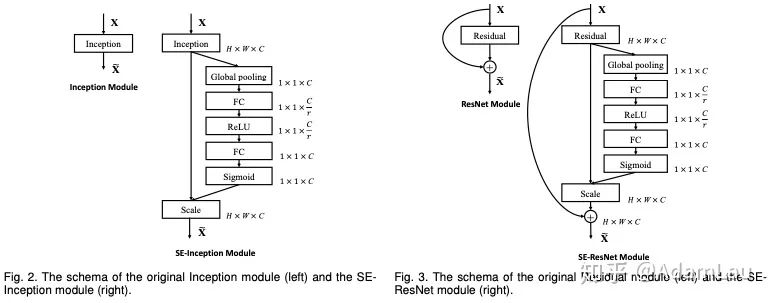
1. SE模块
网络结构如下所示:
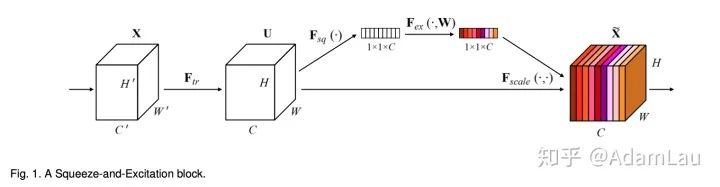
Squeeze 使用全局平均池化(也可用其他方式)生成通道信息统计,实现通道描述;
将全局空间信息压缩为一个通道描述符;
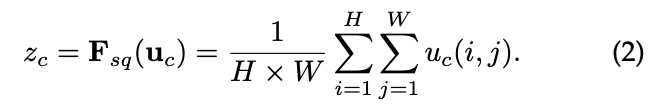
Excitation 实现方式要灵活,且必须能学习一个非互斥的关系
使用了sigmoid激活函数的门限机制来实现,使权重在(0,1)上
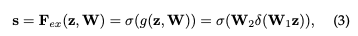
最后通过一个scale的操作将所求的权重乘上原来每个通道的二维特征上
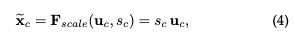
训练全连接网络学习到每个特征通道的权重,权重可以显示地建模特征通道的相关性。
2. 实验
SE模块可以应用到inception、resblock等多种结构,非常灵活。
消融实验非常完备,实验结果也是当时的STOA,夺得了ILSVRC2017的冠军。(较为简略,具体看论文)
3. 结论
SE模块能够动态自适应完成在通道维度上对原始特征进行重标定,首次关注了模型通道层面的依赖关系。另外,由SE块产生的特征重要性值是否能用于网络剪枝(模型压缩)。
论文:https://arxiv.org/pdf/1807.06521.pdf
代码:https://github.com/luuuyi/CBAM.PyTorch
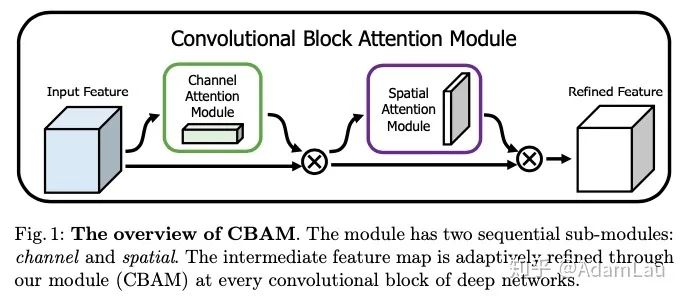
论文Introduction部分提出了影响卷积神经网络模型性能的三个因素:深度、宽度、基数。并且列举了一些代表新的网络结构,比如和深度相关的VGG和ResNet系列,和宽度相关的GoogLeNet和wide-ResNet系列,和基数相关的Xception和ResNeXt。
除了这三个因素之外,还有一个模块,也能影响网络的性能,这就是attention——注意力机制。
动机:所以文章提出了两个注意力机制的模块,分别是channel attention module和spatial attention module。通过级联方式连接起来。模块较为灵活,可以嵌入到ResBlock等。
1. Channnel attetion module(通道注意力模块)
通道注意力模块主要是探索不同通道之间的feature map的关系。每一个通道的feature map本身作为一个特征检测出器(feature detetor),通过这个通道注意力模块来告诉模型,我们更应该注意哪一部分特征。
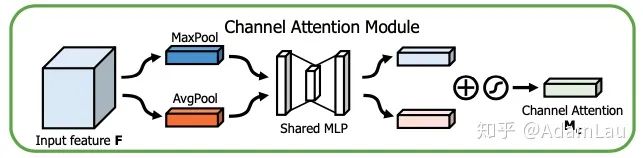
同时使用average-pooling和max-pooling聚合空间维度特征,产生两个空间维度描述符。随后经MLP(fc+Relu+fc)+sigmoid层(和SE-Net相同,只是squeeze操作多了一步max pooling),为每个通道产生权重,最后将权重与原始未经channel attention相乘。
2. Spatial attention module(空间注意力模块)
利用空间注意力模块来生成一个spatial attention map,用来利用不同特征图之间的空间关系,以此来使模型注意特征图的哪些特征空间位置。
网络应用于分类,如何应用到分割上?
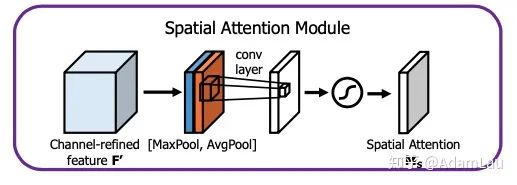
这一次是在轴的方向上对不同特征图上相同位置的像素值进行全局的MaxPooling和AvgPooling操作,分别得到两个spatial attention map并将其concatenate,shape为[2, H, W]。 再利用一个7*7的卷积对这个feature map进行卷积。后接一个sigmoid函数。得到一个语言特征图维数相同的加上空间注意力权重的空间矩阵。 最后把得到的空间注意力矩阵对应相乘的原特征图上,得到的新的特征图。
3. 实验
Comparison of different channel attention methods:

用maxpooling与avgpooling一起比SENet(仅用avgpooling)效果更好。
Comparison of different spatial attention methods:
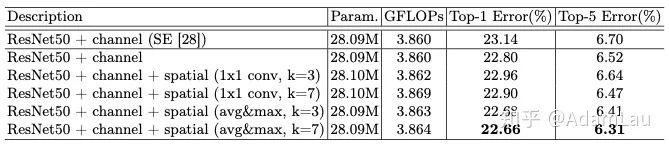
使用7x7卷积核的原因是具有更大的感受野,还有个人认为小卷积核可能会造成一些特征图的confusion。
Combining methods of channel and spatial attention:

整体的消融实验。
论文:https://arxiv.org/pdf/1809.02983.pdf
虽然上下文融合有助于捕获不同比例的对象,但却无法利用全局视图中对象之间的关系。容易忽略不显眼的对象,或是没有综合考虑各个位置的联系和相关性,致使分割的类内不一致性,产生误分割。对于语义分割,每个通道的map相当于是对每一类的响应,因此对于通道间的相关性也应着重考虑。
为解决这一问题,提出了双注意力网络(DANet),基于自注意力机制来分别捕获空间维度和通道维度中的特征依赖关系。具体而言,本文在dilated FCN上附加了2种注意力模块,分别对空间维度和通道维度上的语义依赖关系进行建模。
应用于分割的注意力网络,空间注意力模块与通道注意力模块并联连接,最终将两个模块的结果进行elementwise操作。在特征提取处,作者对ResNet做出以下改动,将最后的downsampling取消,采用空洞卷积来达到即扩大感受野又保持较高空间分辨率的目的,最终的特征图扩大到了原图的1/8。
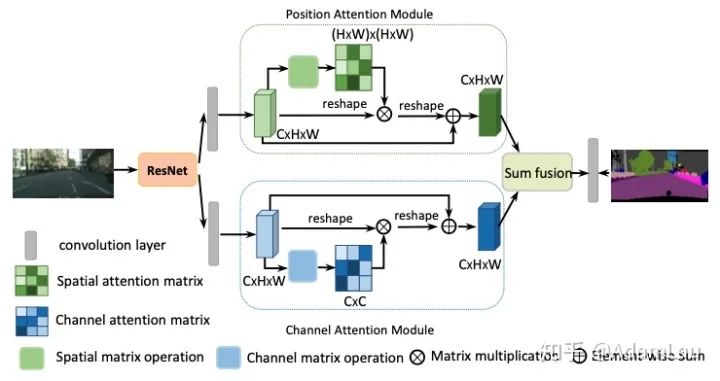
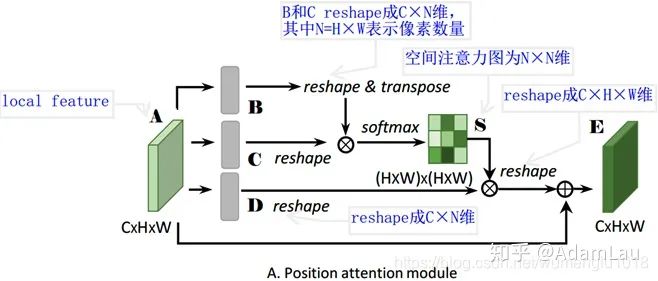
1. Position Attention Module(PAM)
位置注意力模块旨在利用任意两点特征之间的关联,来相互增强各自特征的表达。
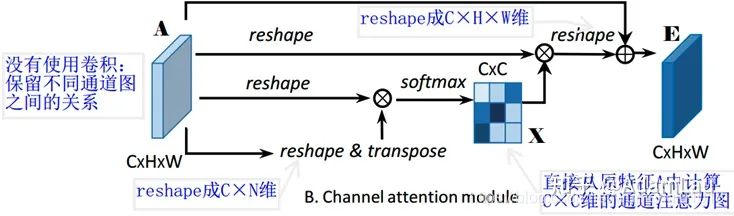
2. Channel Attention Module(CAM)
每个high level特征的通道图都可以看作是一个特定于类的响应,通过挖掘通道图之间的相互依赖关系,可以突出相互依赖的特征图,提高特定语义的特征表示。
为了进一步获得全局依赖关系的特征,将两个模块的输出结果进行相加融合,获得最终的特征用于像素点的分类。
3. 总结
总的来说,DANet网络主要思想是 CBAM 和 non-local 的融合变形。把deep feature map进行spatial-wise self-attention,同时也进行channel-wise self-attetnion,最后将两个结果进行 element-wise sum 融合。
在 CBAM 分别进行空间和通道 self-attention的思想上,直接使用了 non-local 的自相关矩阵 Matmul 的形式进行运算,避免了 CBAM 手工设计 pooling,多层感知器等复杂操作。
参考:
https://blog.csdn.net/elaine_bao/article/details/80821306 https://zhuanlan.zhihu.com/p/102984842 https://zhuanlan.zhihu.com/p/93228308 https://zhuanlan.zhihu.com/p/106084464 https://blog.csdn.net/wumenglu1018/article/details/95949039 https://blog.csdn.net/xh_hit/article/details/88575853
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~