
如何评价FAIR提出的MaskFeat:一种适用图像和视频分类的自监督学...
共 5135字,需浏览 11分钟
·
2022-01-03 18:42
↑ 点击蓝字 关注迈微AI研习社
作者丨谢凌曦、董力、小麻花来源丨https://www.zhihu.com/question/506657286
迈微导读
Facebook新作MaskFeat,该工作的ViT-B在ImageNet 1K上的准确率达到了84.0%,MViT-L在Kinetics-400上的准确率达到了86.7%,一举超越了MAE,BEiT和SimMIM等方法。
# 回答一
作者:谢凌曦
来源链接:https://www.zhihu.com/question/506657286/answer/2275700206
所有内容均只代表作者本人观点,均有可能被推翻,二次转载务必连同声明一起转载。
利益相关:做过且正在做自监督学习相关研究,认识本文的一作,并且讨论过近期发展趋势。
一句话评价:MaskFeat提供了一条新的线索,让我们能够审视手工特征在生成式模型中的作用。
但是,从整体看今年这波自监督学习的工作(包括但不限于BEIT、iBOT、MAE、SimMIM、PeCo、SaGe、MaskFeat),我感受到的迷茫比希望要更多一些。
下面简单解释一下我的观点。限于个人水平,很多看法并不全面,还请轻喷。
自监督学习,本质上就是要解决一个问题:新知识从哪里来?过去几年,业界经历了基于几何的学习方法(包括预测patch相对位置、预测图像旋转角度等)、基于对比的学习方法(包括instance discrimination、feature prediction等)后,终于开始回归最本源的,基于生成的学习方法。然而,在基于生成的学习中,我们必然面临一个核心问题:如何判断生成图像的质量?
怎样的视觉识别算法才是完整的?(https://zhuanlan.zhihu.com/p/376145664)
这个问题,我曾经在之前的文章https://arxiv.org/abs/2105.13978中讨论过,文章大意可参见上面的知乎链接。我的观点是:解决图像质量判断问题,等价于解决新知识从哪里来的问题,也就等价于自监督学习本身。在我们用各种方式扰乱输入的情况下(包括我一直倡议的对图像信号做压缩),像素级评测恢复效果显然不是最佳方案。相信这个道理大家都懂,但是大家是如何做的呢?看看近期的工作:
- MAE、SimMIM:直接用像素评判;
- BEIT、PeCo:使用一个离线预训练的tokenizer:这个tokenizer和VQ-VAE挂钩,而VQ-VAE的目标是恢复像素——因此几乎可以认为,这种tokenizer的作用和像素级恢复是相当的;
- iBOT:将上述tokenizer改为在线训练,利用类似于teacher-student的方式做监督——我很喜欢它无需引入离线预训练的性质,虽然它的训练效率要低一些;
- SaGe:使用一个离线BYOL预训练的网络来抽特征;
- MaskFeat:使用手工的HOG特征——这是2005年的CVPR paper,新人们有多少能第一时间反应出HOG是啥玩意儿的?
然后重点来了:根据我们的研判,上述几种方法的效果,其实没有很本质的差别。这波工作只所以能够达到看似很高的性能,关键在于vision transformer的应用,以及它和masked image modeling任务的绝妙配合。当然,一组组优秀的参数也是功不可没的。
这意味着什么呢?视觉自监督领域做了这么些年,从最早的生成式学习出发,绕了一圈,又回到生成式学习。到头来,我们发现像素级特征跟各种手工特征、tokenizer、甚至离线预训练网络得到的特征,在作为判断生成图像质量方面,没有本质区别。也就是说,自监督也许只是把模型和参数调得更适合下游任务,但在“新知识从哪里来”这个问题上,并没有任何实质进展。
诚然,大家可以说:视觉自监督不需要学习任何知识,只需要拟合给定数据集的分布,使得下游微调更方便即可。可我总觉得,这不应该是自监督所追求的唯一目标。
道阻且长!
# 回答二
作者:董力
来源链接:https://www.zhihu.com/question/506657286/answer/2276537031
为了使生成式自监督预训练发挥作用,BEiT( https://arxiv.org/pdf/2106.08254.pdf)中提供的一个insight是"pixel-level recovery task tends to waste modeling capability on pre-training short-range dependencies and high-frequency details",具体到每个工作,大家的解决办法都不太一样:
- BEiT: 使用dVAE tokenizer构造bottleneck,将pixel-level details学在tokenzier参数中 ("BEiT overcomes the above issue by predicting discrete visual tokens, which summarizes the details to high-level abstractions.")
- MAE: 1) 增加了decoder部分用来记忆pixel-level details;2) encoder部分去除了[M],把masked patch信息推到decoder中;3) per-patch-norm 归一化掉细节信息,鼓励学习semantic content
- PeCo: 在BEiT tokenizer中加入perceptual loss (在style transfer里面充当content loss),鼓励visual tokens保留semantic content,抑制具体的纹理、style等信息
- iBOT: 框架上类似BEiT+DINO,其中DINO部分得到的online tokenizer,通过data augmentation抑制细节信息的学习
- MaskFeat: 利用人工构造的HOG features作为学习目标,消除细节信息
基于BEiT中提出的masked image modeling (MIM)预训练任务,可以发现目前的绝大多数工作都是从上面说的这个insight去提升自监督效果。问题中的提到的MaskFeat验证了人工构造的HOG特征,也可以起到很好的效果。希望未来有更形式化的工作,去指引大家创新。
# 回答三
作者:小麻花
来源链接:
https://www.zhihu.com/question/506657286/answer/2276460942
paper:https://arxiv.org/abs/2112.09133
论文解读
要想理解论文,我们先搞明白什么是HOG特征
“HOG(方向梯度直方图)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,HOG特征通过计算和统计图像局部区域的梯度方向直方图来构成特征”

HOG可以表示图像得物体特征,能够检测出这类物体,在早期的计算机视觉,HOG就已经有应用了,比如HOG+SVM的行人检测
这里不详细讲HOG,有兴趣的同学可以搜论文,下面开始正题
遮蔽左图,人类通常能猜出这个大概是什么,并绘制想象信息的轮廓,比如我们猜 masked input,大家大概能猜出来是一个狗
我们要教计算机来会猜,BEiT是去猜经过dVAE的visual token,MAE是去猜pixel,而这篇工作是去猜HOG
作者也证明猜这个HOG很牛的,不仅在视频牛逼,而且也在图像牛逼,通过这个思路,被训练的模型可以充分理解复杂时空结构

我们看看网络的结构是什么样的,方法很简单,一个原图经过masked后进入encoder,然后linear一下,预测这个原图的HOG,具体做法是,首先获得原图的HOG特征图,然后分块,把要mask的部分平坦化,最小化预测的HOG和原始HOG的L2损失
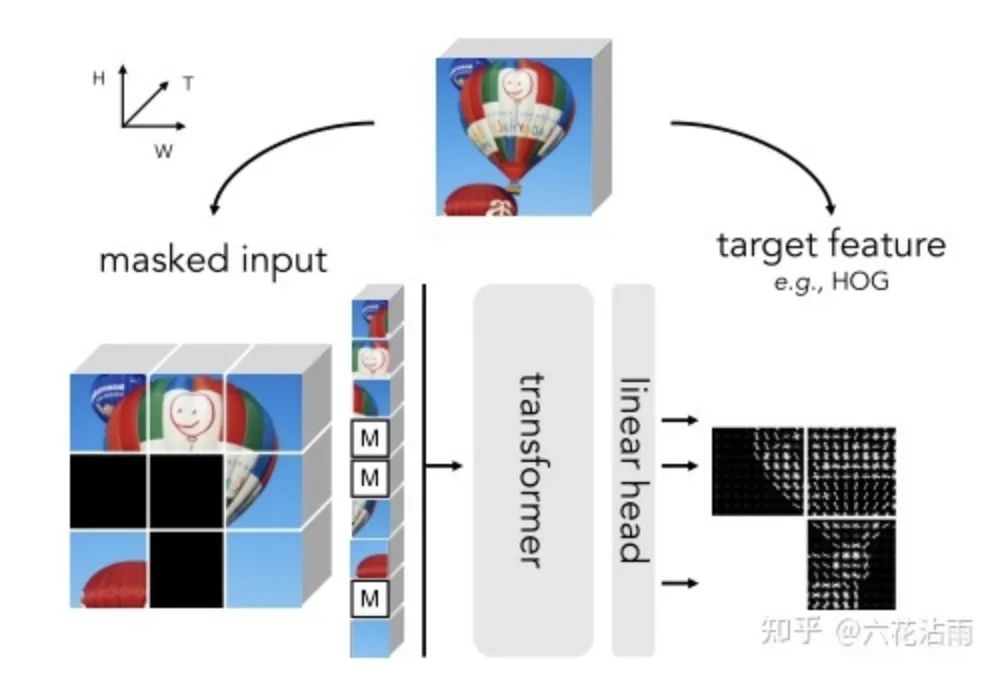
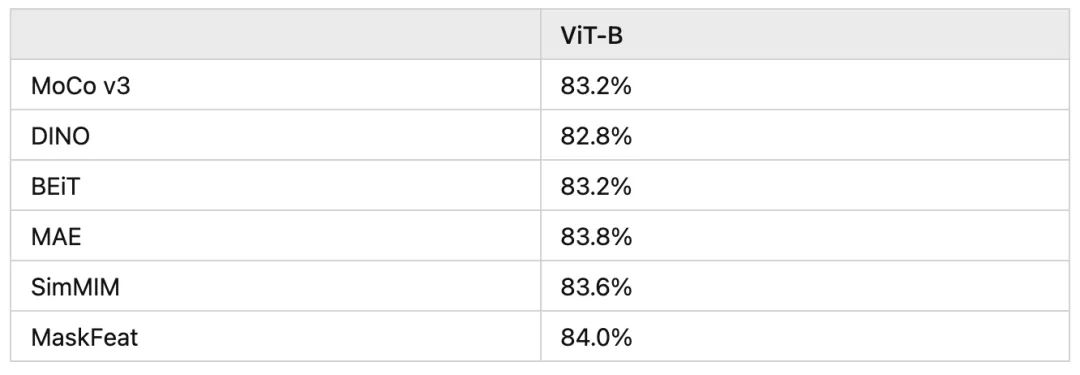
就这么简单,没有BEiT那种复杂的dVAE,MaskFeat 不仅在视频方面取得了不俗的性能,而且在图像方面也有不俗的性能,在ViT-B模型上性能超越BEiT、SimMIM、MAE等
自监督的MIM说到底就是在玩去预测什么,以及为什么预测这个能牛逼,bert是预测被mask的词语,beit是预测被mask的visual token,mae是预测被mask的pixel,而现在我们要说一下为什么maskfeat去预测被mask的部分的HOG可以work?
为了证明HOG可以作为很好的预测特征,作者列出了其他的特征,通过实验对比来证明HOG的优势
- pixel color
这个在以前的图像修补任务经常用到,但是有一个潜在的缺点,会过度拟合局部统计数据和高频细节,局部统计这里是指光照和对比变化,这会给模型理解事物本质造成噪声
- HOG
HOG擅长捕捉局部形状和外观,一定程度不受几何变化影响,对光照变化和对比度变化鲁棒,这一点在HOG+SVM行人检测十分重要,同时HOG计算开销很小,卷积然后进行直方图和归一化就行了,可以忽略
- dVAE
会引起额外的计算开销,如BEiT
- Deep feature、pseudo label
deep feature和dVAE一样会带来额外的计算开销,pseudo label参考TokenLabeling
为了比较上述那个好,作者做了简单的实验,如下图所示,基于RGB和基于HOG是one stage的,因为不会引入别的额外模型,直接从图像得到数据,其他的都是two stage(除了scratch外),都需要设定额外模型来对原图进行特征提取
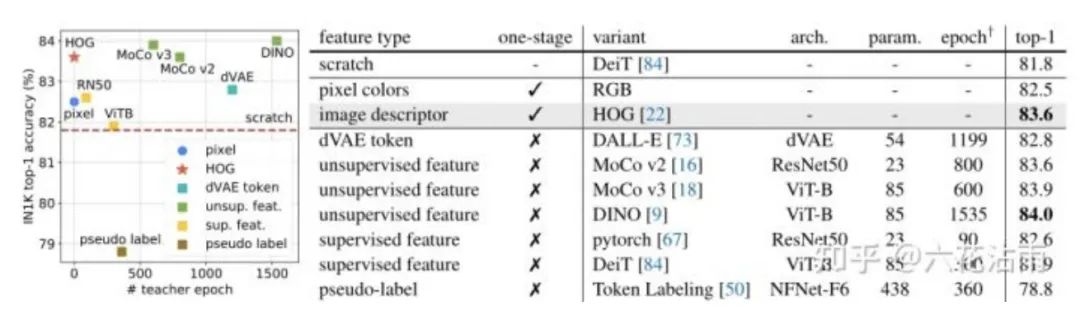
作者注意到,在微调过程中,superviesd 和 pseudo-label 会出现显著的过拟合,表明从类别标签学习在Maskfeat是不合适的,一定程度说明,先ssl然后做fine tune确实有一定的效果
考虑性能和计算成本的权衡,作者选择了HOG作为pretext task
接下来作者基于HOG做了一系列的实验
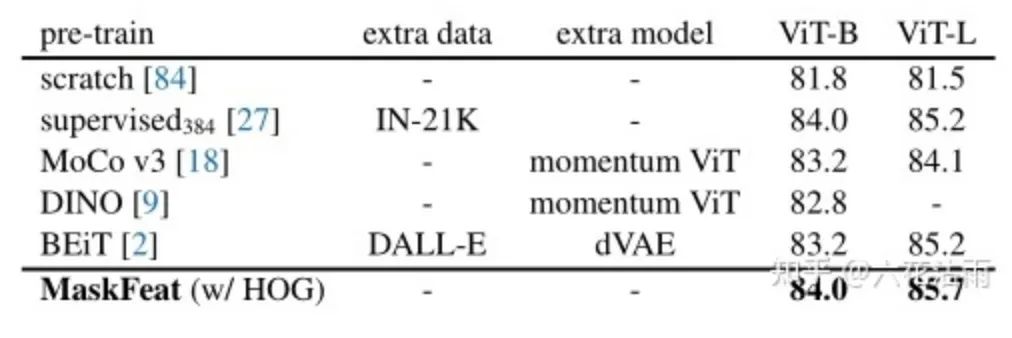
上图所示,MaskFeat无需额外数据(baseline为ImagNet1k),无需额外模型,得到了具有竞争力的性能,pre-train 1600 epoch,fine-tune 100 epoch(vit-l 50 epoch)有趣得的是,在vit-l大模型下得到了非常好的扩展性,相比scratch,自监督确实是大模型一个很好的解决之路
此外,针对Pixel和HOG更详细的对比,作者做了一系列的实验,如下所示,基于Pixel的预测会生成模糊的图像,如下所示

更形象一点,在高频区域下,比如预测海胆,周边的毛刺可以看做高频区域,基于Pixel的方式会产生模糊的颜色预测,而HOG的预测可以很好抓住高频区域的纹理变化,对模糊性更加鲁棒

实际上,在MAE的实验中,这个现象也存在,如下图所示,高频部分被模糊,纹理特征不明显(另外推广一下飞桨的自监督库PASSL~

Refer
[1] Histograms of Oriented Gradients for Human Detection (inria.fr)
[2] facebookresearch/deit: Official DeiT repository (github.com)
[3] zihangJiang/TokenLabeling: Pytorch implementation of "All Tokens Matter: Token Labeling for Training Better Vision Transformers" (github.com)
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注迈微AI研习社,获取最新CV干货公众号后台回复“transformer”获取最新Transformer综述论文下载~
推荐阅读
(更多“抠图”最新成果)
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve
如果觉得有用,就请点赞、转发吧!