
高性能无锁并发框架 Disruptor,太强了!

Java技术栈
www.javastack.cn
关注阅读更多优质文章
Disruptor是一个开源框架,研发的初衷是为了解决高并发下队列锁的问题,最早由LMAX提出并使用,能够在无锁的情况下实现队列的并发操作,并号称能够在一个线程里每秒处理6百万笔订单
官网:http://lmax-exchange.github.io/disruptor/
目前,包括Apache Storm、Camel、Log4j2在内的很多知名项目都应用了Disruptor以获取高性能
为什么会产生Disruptor框架
「目前Java内置队列保证线程安全的方式:」
ArrayBlockingQueue:基于数组形式的队列,通过加锁的方式,来保证多线程情况下数据的安全;
LinkedBlockingQueue:基于链表形式的队列,也通过加锁的方式,来保证多线程情况下数据的安全;
ConcurrentLinkedQueue:基于链表形式的队列,通过CAS的方式
我们知道,在编程过程中,加锁通常会严重地影响性能,所以尽量用无锁方式,就产生了Disruptor这种无锁高并发框架
基本概念
参考地址:https://github.com/LMAX-Exchange/disruptor/wiki/Introduction#core-concepts
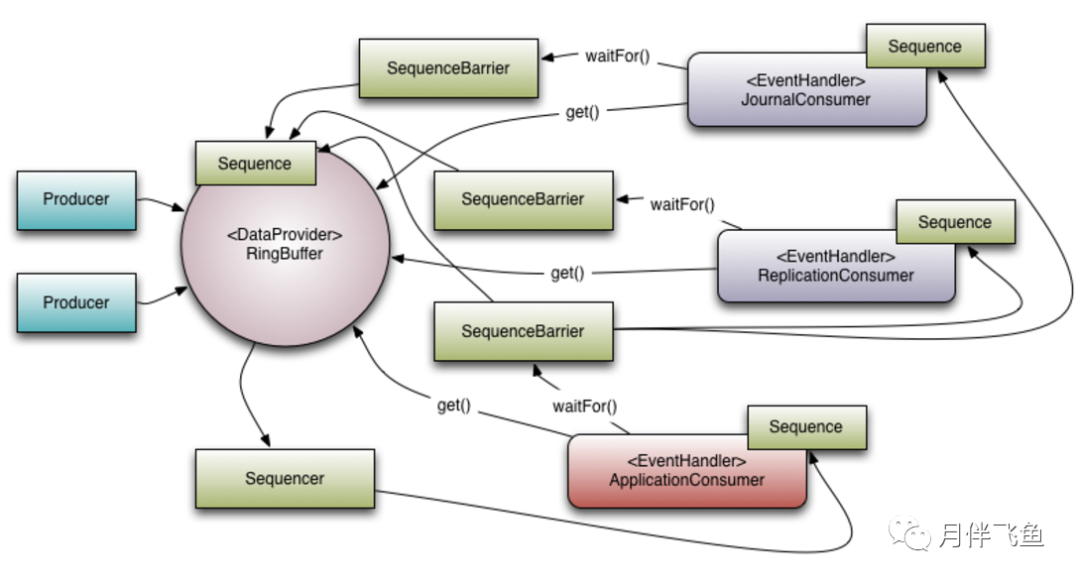
RingBuffer——Disruptor底层数据结构实现,核心类,是线程间交换数据的中转地;
Sequencer——序号管理器,生产同步的实现者,负责消费者/生产者各自序号、序号栅栏的管理和协调,Sequencer有单生产者,多生产者两种不同的模式,里面实现了各种同步的算法;
Sequence——序号,声明一个序号,用于跟踪ringbuffer中任务的变化和消费者的消费情况,disruptor里面大部分的并发代码都是通过对Sequence的值同步修改实现的,而非锁,这是disruptor高性能的一个主要原因;
SequenceBarrier——序号栅栏,管理和协调生产者的游标序号和各个消费者的序号,确保生产者不会覆盖消费者未来得及处理的消息,确保存在依赖的消费者之间能够按照正确的顺序处理
EventProcessor——事件处理器,监听RingBuffer的事件,并消费可用事件,从RingBuffer读取的事件会交由实际的生产者实现类来消费;它会一直侦听下一个可用的序号,直到该序号对应的事件已经准备好。
EventHandler——业务处理器,是实际消费者的接口,完成具体的业务逻辑实现,第三方实现该接口;代表着消费者。
Producer——生产者接口,第三方线程充当该角色,producer向RingBuffer写入事件。
Wait Strategy:Wait Strategy决定了一个消费者怎么等待生产者将事件(Event)放入Disruptor中。
等待策略
源码地址:https://github.com/LMAX-Exchange/disruptor/blob/master/src/main/java/com/lmax/disruptor/WaitStrategy.java
「BlockingWaitStrategy」
Disruptor的默认策略是BlockingWaitStrategy。在BlockingWaitStrategy内部是使用锁和condition来控制线程的唤醒。BlockingWaitStrategy是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现。
「SleepingWaitStrategy」
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,通过使用LockSupport.parkNanos(1)来实现循环等待。
「YieldingWaitStrategy」
YieldingWaitStrategy是可以使用在低延迟系统的策略之一。YieldingWaitStrategy将自旋以等待序列增加到适当的值。在循环体内,将调用Thread.yield()以允许其他排队的线程运行。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
「BusySpinWaitStrategy」
性能最好,适合用于低延迟的系统。在要求极高性能且事件处理线程数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
「PhasedBackoffWaitStrategy」
自旋 + yield + 自定义策略,CPU资源紧缺,吞吐量和延迟并不重要的场景。
使用举例
参考地址:https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started
<dependency>
<groupId>com.lmaxgroupId>
<artifactId>disruptorartifactId>
<version>3.3.4version>
dependency>
//定义事件event 通过Disruptor 进行交换的数据类型。
public class LongEvent {
private Long value;
public Long getValue() {
return value;
}
public void setValue(Long value) {
this.value = value;
}
}
public class LongEventFactory implements EventFactory<LongEvent> {
public LongEvent newInstance() {
return new LongEvent();
}
}
//定义事件消费者
public class LongEventHandler implements EventHandler<LongEvent> {
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception {
System.out.println("消费者:"+event.getValue());
}
}
//定义生产者
public class LongEventProducer {
public final RingBuffer ringBuffer;
public LongEventProducer(RingBuffer ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer byteBuffer) {
// 1.ringBuffer 事件队列 下一个槽
long sequence = ringBuffer.next();
Long data = null;
try {
//2.取出空的事件队列
LongEvent longEvent = ringBuffer.get(sequence);
data = byteBuffer.getLong(0);
//3.获取事件队列传递的数据
longEvent.setValue(data);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} finally {
System.out.println("生产这准备发送数据");
//4.发布事件
ringBuffer.publish(sequence);
}
}
}
public class DisruptorMain {
public static void main(String[] args) {
// 1.创建一个可缓存的线程 提供线程来出发Consumer 的事件处理
ExecutorService executor = Executors.newCachedThreadPool();
// 2.创建工厂
EventFactory eventFactory = new LongEventFactory();
// 3.创建ringBuffer 大小
int ringBufferSize = 1024 * 1024; // ringBufferSize大小一定要是2的N次方
// 4.创建Disruptor
Disruptor disruptor = new Disruptor(eventFactory, ringBufferSize, executor,
ProducerType.SINGLE, new YieldingWaitStrategy());
// 5.连接消费端方法
disruptor.handleEventsWith(new LongEventHandler());
// 6.启动
disruptor.start();
// 7.创建RingBuffer容器
RingBuffer ringBuffer = disruptor.getRingBuffer();
// 8.创建生产者
LongEventProducer producer = new LongEventProducer(ringBuffer);
// 9.指定缓冲区大小
ByteBuffer byteBuffer = ByteBuffer.allocate(8);
for (int i = 1; i <= 100; i++) {
byteBuffer.putLong(0, i);
producer.onData(byteBuffer);
}
//10.关闭disruptor和executor
disruptor.shutdown();
executor.shutdown();
}
}
核心设计原理
Disruptor通过以下设计来解决队列速度慢的问题:
「环形数组结构:」
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好
❝原因:CPU缓存是由很多个缓存行组成的。每个缓存行通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个缓存行。在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。
❞
「元素位置定位:」
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
「无锁设计:」
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据,整个过程通过原子变量CAS,保证操作的线程安全
数据结构
框架使用RingBuffer来作为队列的数据结构,RingBuffer就是一个可自定义大小的环形数组。
除数组外还有一个序列号(sequence),用以指向下一个可用的元素,供生产者与消费者使用。
原理图如下所示:
Sequence
mark:Disruptor通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。
「数组+序列号设计的优势是什么呢?」
回顾一下HashMap,在知道索引(index)下标的情况下,存与取数组上的元素时间复杂度只有O(1),而这个index我们可以通过序列号与数组的长度取模来计算得出,index=sequence % table.length。当然也可以用位运算来计算效率更高,此时table.length必须是2的幂次方。
写数据流程
单线程写数据的流程:
申请写入m个元素; 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素; 若是返回的正确,则生产者开始写入元素。 
使用场景
经过测试,Disruptor的的延时和吞吐量都比ArrayBlockingQueue优秀很多,所以,当你在使用ArrayBlockingQueue出现性能瓶颈的时候,你就可以考虑采用Disruptor的代替。
参考:https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results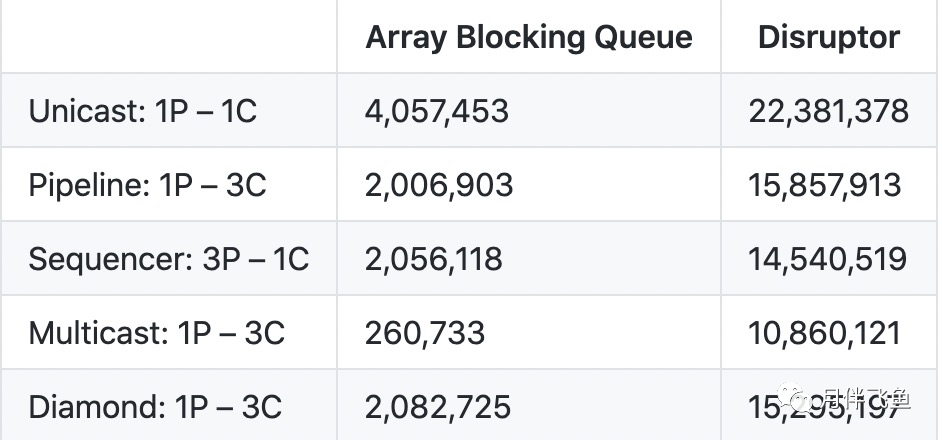
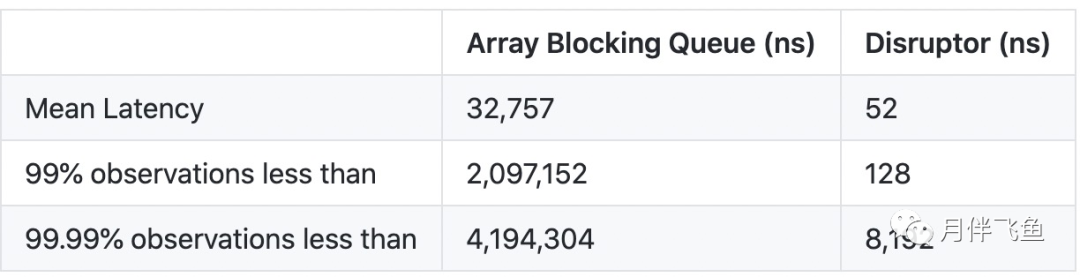
当然,Disruptor性能高并不是必然的,所以,是否使用还得经过测试。
Disruptor的最常用的场景就是“生产者-消费者”场景,对场景的就是“一个生产者、多个消费者”的场景,并且要求顺序处理。
举个例子,我们从MySQL的BigLog文件中顺序读取数据,然后写入到ElasticSearch(搜索引擎)中。在这种场景下,BigLog要求一个文件一个生产者,那个是一个生产者。而写入到ElasticSearch,则严格要求顺序,否则会出现问题,所以通常意义上的多消费者线程无法解决该问题,如果通过加锁,则性能大打折扣
参考:
https://tech.meituan.com/2016/11/18/disruptor.html
https://github.com/LMAX-Exchange/disruptor/wiki






关注Java技术栈看更多干货
