
如何让你的 Python 代码经得起时间检验?
之前一篇文章里我们介绍了 Python 架构模式[1],其中包含了非常多如何设计大型 Python 项目架构的思考和实践方式。不过在日常工作中,除了整体架构外,对于代码本身的工程质量也同样非常重要。
之前给朋友推荐这方面 Python 相关的书籍,一般都是《Fluent Python》或者《Effective Python》这两本,前者相对比较关注 Python 的内部原理,如何灵活应用需要不浅的功力;而后者是相对零散的最佳实践,缺乏一种体系性的感觉。
今年读了一本比较新出的《Robust Python[2]》,发现很好的填补了 Python 在工程质量话题方面的空白,能为维护大型的 Python 项目打下非常好的基础。这篇文章就来简单介绍一下这本书的内容。
背景总览
由于近些年在数据科学,机器学习方面的大量应用,Python 已经成为这个星球上最流行的编程语言之一。随着数据智能、机器学习算法类应用的爆发,整个领域也逐渐从之前的“小作坊实验室”模式往“工业化大规模生产”模式转变。这也是为啥 MLOps 这两年越来越成为一个热门话题的原因。随着算法类软件逐渐走向“工业化”,拥有良好工程能力的算法工程师越来越成为企业急需的人才类型。就拿我们公司来说,之前也考虑过要不要招聘专职的 Python 开发工程师来做 AI 相关产品的研发。
不过嘛,算法类的 Python 开发跟传统的 Web 开发在知识领域上的需求还是有很大区别的,所以绝大多数情况下还是算法工程师补充更多的代码工程技能会更有优势。这也是为什么我非常推荐从事算法工作的同学也可以多学习一下这本书的原因。
Robust Python,顾名思义,就是教我们如何写出更加“健壮”的代码,不易出错,且能长时间的进行修改和维护。Python 本身的语法和概念非常简单,我有很长一段时间甚至都觉得这是一门不需要刻意学习的语言(相比 Rust,Scala 等)。但看了这本书才发现原来写出高质量的工程代码有这么多的讲究,以前好像自己都是“没有穿裤子在上班”那样不专业。
1 Introduction to Robust Python
这一章主要是介绍了一下什么是健壮的代码以及我们为什么需要它,如果面试中有碰到“你认为什么样的代码是好的代码”之类的问题,那么主要就是在考察你有没有过这方面软件工程的思考,而不仅仅是只把当前的功能完成就好。概括来说,编写健壮的代码,能让整个软件系统更加容易修改和维护,且出错的概率更低。如果你的项目能够持续做快速的更新发布,每次迭代的交付质量还很高,没什么 bug,新加入的工程师也能很快理解和上手做功能开发,甚至出现了 bug 也很容易排查,那么就是一个比较理想的软件项目,能带来非常可观的价值回报。
这一章的大部分内容在很多经典著作中都有提到,比如《Clean Code》等,所以熟悉的同学可以快速浏览过去。有两个个人觉得比较有意思的观点在这里 highlight 一下。
健壮性的核心是沟通
其他大佬也发表过一些类似观点,如代码应该是写给人看的,而不是写给机器;没有测试的代码都属于“遗留代码”。文中作者进一步结构化了这个观点,从沟通所需要的“即时性”(是否能跟未来的开发者进行沟通)和投入成本两个维度来考察各种软件工程中的“沟通手段”:
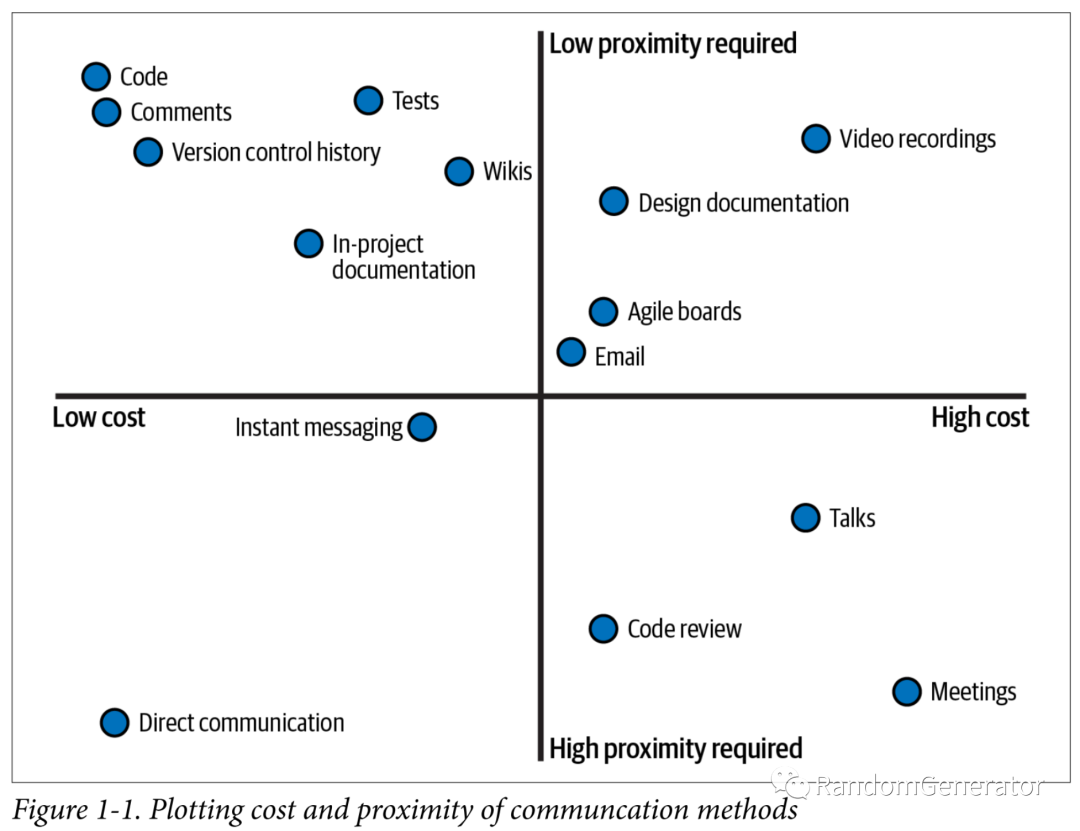
本书中提到的大部分方法都集中在左上象限,即那些不需要投入太高的维护、使用成本,同时在时间维度上没有即时性要求的方法,如清晰的代码,注释,测试等。
约定俗成的意图
从沟通角度看,我们在写代码时使用的各种语言特性,应该传达一种约定俗成的意图,以降低理解成本。文中作者举了很多 Python 中的实际例子,例如当你使用list时,想要存储的是有顺序,可重复的,并且内容可变的元素集合,而且一般来说这些元素都是同一种类型。当你使用不同的循环方法,class 或者 dataclass,不同的编程 pattern 时,其实背后都应该有相应的意图共识。遵守这些约定能最大程度上减少对其他维护者造成的“意外”感觉,我们说的“Pythonic”也大致是这个意思。
2 Introduction to Python Types
本书的第一部分主要都在讲类型方面的最佳实践。Python 支持类型注解也有些年头了,不过绝大多数的学习资料里都没有强调这个特性,导致大家对 Python 的理解都停留在这是一门脚本语言,写起来比较快捷灵活,但非常容易出线上报错,且理解代码时也经常不知道参数是个什么类型这种问题。个人建议如果是工作中使用维护周期超过 1 年的项目,都应该考虑增加类型注解的最佳实践。
回到这一章里,作者对类型系统做了个入门介绍,Python 属于强类型(比较少隐式转换),但又是动态类型的语言,顺带还可以复习一下 duck typing。
3 Type Annotations
这一章开头就引用了一下 Python 之父的话,大意是 喜欢是放肆,但爱是克制 写脚本可以为所欲为,但做项目就要按规矩来。写 Python 时加上类型注解,就是一种成熟稳重负责任的表现 :) 本章内容也比较基础,对类型注解做了基本的介绍,并引入了mypy这类类型检查工具。例如对于下面的代码:
def read_file_and_reverse_it(filename: str) -> str:
with open(filename) as f:
return f.read().encode("utf-8")[::-1]
我们就可以使用mypy来做检查,并发现其中的问题:
❯ mypy chapter3/invalid/invalid_example1.py
chapter3/invalid/invalid_example1.py:3: error: Incompatible return value type (got "bytes", expected "str")
Found 1 error in 1 file (checked 1 source file)
对于什么时候需要加类型注解,作者也给出了一些建议:
其他用户会调用的接口,尤其是 public APIs。 当需要处理的数据类型比较复杂时,比如有嵌套结构。 类型检查工具有提示时。
4 Constraining Types
本章介绍了一些相对“高级”一些的限制类型。比如我们经常在代码中碰到一些异常情况,最简单的做法就是在碰到异常时返回一个None,然后程序在后面运行时指不定哪里就出现了一个错误:
AttributeError: 'NoneType' object has no attribute '...'
对于这种问题,我们可以在程序的 return type 上指定Optional类型的注解,这样就能通过类型检查工具来帮我们尽量避免上述报错的出现。
此外还有很多非常实用的类型,如特定场景下,Union相比 dataclass 或者Tuple这些类型,能把 Product Type 转为 Sum Type,大大减少的表达空间的可能性,也降低了犯错的几率。Literal可以指定相应的取值范围(当然Enum可能更强大一些)。NewType可以对同一种类型的“状态”做区分,Final可以用于构造不变量等。
5 Collection Types
对于 collections 的注解,我们建议应该把集合里的元素类型也加上,便于用户理解。比如用list[str]这样的形式,而不只是list。这里也顺带引出了一个最佳实践,就是对于各种集合,绝大多数情况下我们应该保存“同质”的类型。只有少数的例外情况:
使用 tuple 来存放不同字段信息,例如 Cookbook = tuple[str, int] # name, page count。这也是 tuple 约定俗成的用法,当然为了增加可读性,后续会提到的 dataclass 更为合适。使用 dict 来存放一些参数,配置信息,相比 tuple 来说可以支持更复杂的嵌套结构。事实上很多 json,yaml 库都是这么做的。
对于后者,作者建议可以使用 TypedDict 来做,可以更多的利用类型检查来帮助减少错误发生的可能,同时也能帮助其他开发者理解复杂数据结构。例如:
from typing import TypedDict
class Song(TypedDict):
name : str
year : int
song: Song = {'name': 'We Will Rock You' , 'year': 1977}
不过个人觉得这个注解对于复杂类型用起来还是挺麻烦的,还是 dataclass 更实用些。
接下来作者介绍了 Python 中的 Generics,说实话我之前还真不知道 Python 还有“泛型”的支持……例如:
from typing import TypeVar
T = TypeVar("T")
APIResponse = Union[T, APIError]
def get_nutrition_info(recipe: str) -> APIResponse[NutritionInfo]:
# ...
def get_ingredients(recipe: str) -> APIResponse[list[Ingredient]]:
#...
def get_restaurants_serving(recipe: str) -> APIResponse[list[Restaurant]]:
# ...
后面还介绍了如何在 Python 中扩展或构建自定义的集合类型,提到了两种方法,一种是继承已有类型,但注意如果涉及到魔法方法的修改,应该使用collections.UserDict而不是dict,因为后者的很多方法都做了方法内联;另一种是使用collections.abc里提供的抽象类。
6 Customizing Your Typechecker
讲完了具体的类型,这一章主要介绍了各种类型检查工具及相应的配置。包括mypy,pyre,和pyright。其中mypy属于 Python 官方开发维护,是目前应用最广的一个库。不过其它几个来头也不小,比如pyre来自 Facebook,pyright来自 Microsoft。根据我参与过的一些开源项目,绝大多数用的都是mypy,像pandas也用了pyright来进行补充。从作者的介绍来看,pyright因为是微软出品,还提供了非常棒的 VS Code 集成,实时的检查与提示能够让问题更快暴露,提升开发效率。如果有用 VS Code 的同学可以尝试一下。
7 Adopting Typechecking Practically
很多历史项目在开始时并没有做类型注解的意识,或者因为开始的比较早,当时的 Python 版本还不支持,所以我们在实际应用时需要制定一些策略来注解应用类型注解和检查的最佳实践。相比测试来说,类型注解更大的问题在于只针对一两个数据结构,函数做注解,能获得的收益并不明显,书中给出了一个示意图:
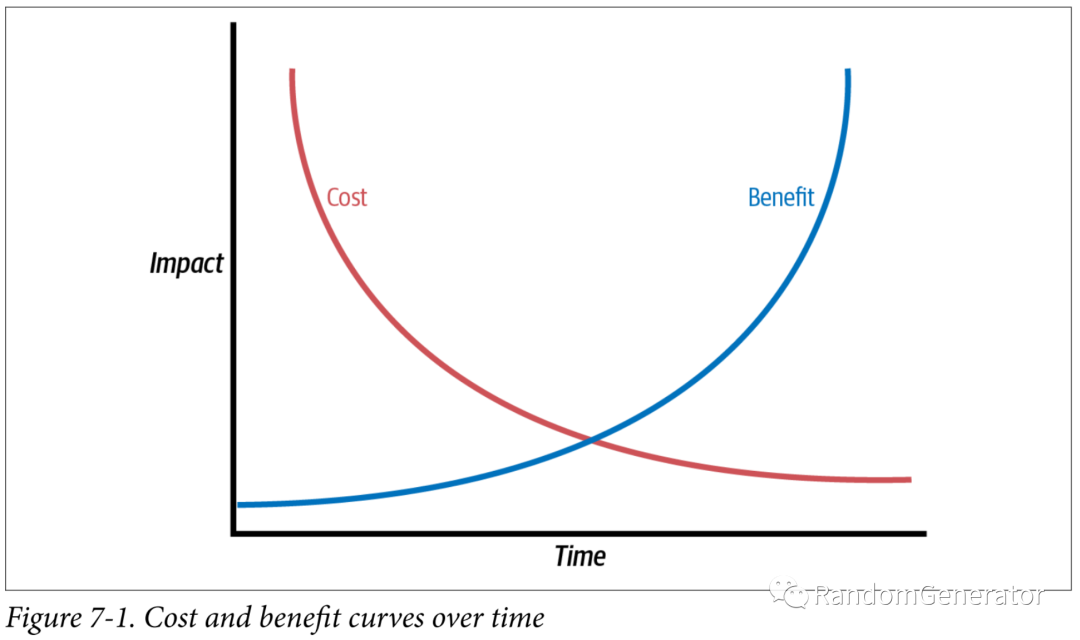
为了能尽快达到一个有显著产出,且投入开销可控的状态,书中建议针对项目痛点来进行开展,并提供了一套行动建议:
新写的代码,都加上类型注解。 对于经常被 import 的项目通用代码添加类型注解。 对于产生业务价值的核心代码添加类型注解。 针对变化比较频繁的代码来添加类型注解。 对逻辑复杂的代码添加类型注解。
这里有个小彩蛋,可以通过以下命令来寻找 commit 最频繁的代码文件:
git rev-list --objects --all | awk '$2' | sort -k2 | uniq -cf1 | sort -rn | grep "\.py" | head
最后作者还建议可以利用一些工具来帮助自动生成代码中的类型注解,如 Instagram 的 MonkeyType[3] 和来自 Google 的 pytype[4],大家也可以一试。
8 User-Defined Types: Enums
从这一章开始进入了第二部分,创建自定义的类型。为什么自定义类型对健壮性有帮助呢,书中举了个非常生动的例子:
def calculate_total_with_tax(restaurant: tuple[str, str, str, int],
subtotal: float) -> float:
return subtotal * (1 + tax_lookup[restaurant[2]])
和
def calculate_total_with_tax(restaurant: Restaurant,
subtotal: decimal.Decimal) -> decimal.Decimal:
return subtotal * (1 + tax_lookup[restaurant.zip_code])
这两段代码是在做同一件事情,但从可读性来说,后面这段通过有意义的类别名称,大大降低了理解的难度。从 DDD 的角度来看,领域类型抽象是非常重要的一环。
回到这一章的重点,主要介绍了Enum类型。这跟前面提到过的Literal类型在用途上很相似,不过Enum提供了更多的高级功能。比如支持多选的Flag类型,支持做数值比较的IntEnum,或者通过unique装饰器来保证 key 的唯一性等。
9 User-Defined Types: Data Classes
前面在讲集合类型时有提到过 TypedDict,但类似场景下的默认选址应该还是本章介绍的 dataclass。相比 dict,dataclass 能更好的指定各个成员变量的类型,还能提供字段名的检查,大大减少了出错可能。相比原版的 class,dataclass 在定义时更加简单,不用写一堆的__init__方法,只需要直接列出成员变量即可:
from dataclasses import dataclass
@dataclass
class MyFraction:
numerator: int = 0
denominator: int = 1
此外 dataclass 还有很多便利功能,如默认提供了更好可读性的 string representation,可以直接做相等,大小比较等。甚至跟 class 一样,dataclass 中也可以定义各种方法,这就是 dict 等完全不具备的能力了。
文中还给出了 dataclass 与其它类型如 dict, TypedDict,namedtuple 之间的用途比较,基本上结论也是在处理异构数据的集合(一般就是领域模型)时,优先使用 dataclass。
10 User-Defined Types: Classes
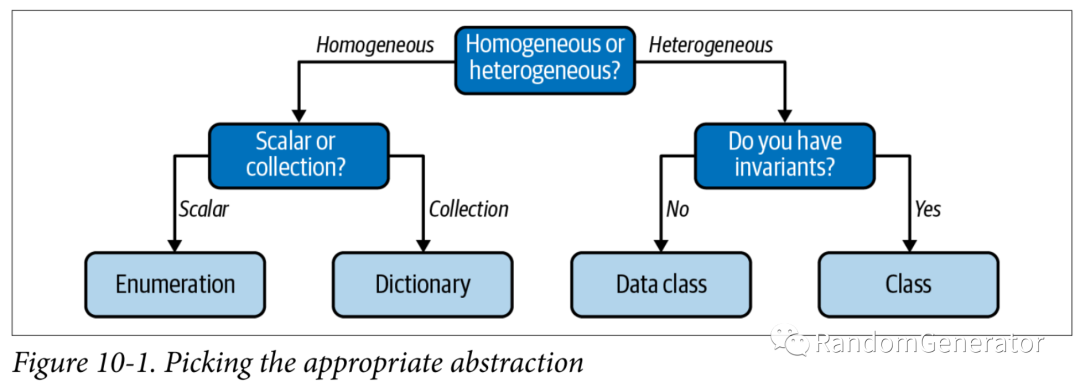
看完 dataclass,一个很自然的想法是感觉 dataclass 功能已经很全了,好像没有啥时候需要用到传统的 class 了?作者给出的解答是,class 最大的作用是可以维护不变性。在做类的初始化时,我们可以在__init__方法中加入各种检查,来确保创建的对象是符合业务逻辑的。而在类的实例使用过程中,我们也同样需要维护这些不变性,作者建议我们可以用私有变量结合 setter 方法来实现。对于如何做 class 的抽象,文中也简单介绍了一下 SOLID 原则。本章的结尾,作者还对上面提到的一系列自定义类型的选用总结了一张决策图:
11 Defining Your Interfaces
这一章主要介绍了如何来设计好用的接口,这其实是一个非常重要的话题,尤其很多新手都会觉得设计个函数签名是很简单直白的事情。但稍微做过一些实际的大型项目就会发现,要设计好的 API 相当的困难。没有好的 API,用户/维护者就容易误用你的代码,或者仅使用一小部分功能,自己再“重建”一些相关接口,让代码库中出现各种重复的功能点,进一步加大了开发者选择正确接口的难度。而且对于用户基数大的库,要做 API 设计的变动也是非常麻烦的一件事情,因此在这个问题上,必须投入足够的精力进行重视。
文中给出的建议是可以通过 test-driven development 或者 README-driven development 的方法代入用户视角,更早的发现 API 设计的问题。文中还通过一个实例介绍了“Natural Interfaces”的设计方法,穿插介绍了一下 Python 中的魔法方法,以及利用 contextmanager 来让代码“不容易被误用”(这里主要是处理失败路径)。不过总体来说,接口设计是一门挺大的学问,文中简短的例子也看不出多少系统性的方法论。如果有这方面比较好的学习资料,也欢迎大家推荐。
12 Subtyping
这又是一个值得好好讨论的话题,因为很多新人知道了继承的用法之后,就会在各种不管合适不合适的地方进行使用,造就了很多难以维护的代码库。比如最常见的误区,只要复用了方法,就可以用继承。还有很多文章给出的建议是,只要满足了“is-a”关系的,就可以用继承,但这个定义其实并不清晰。文中用正方形和长方形的例子对此进行了反驳,并提出了更加规范化的“里氏替换原则”:
如果在使用父类的任何情况下,你都可以传递一个子类进去而不出现问题,那么理论上来说就可以用继承。 子类必须保留所有父类中的“不变性”,比如长方形的长和宽两个变量是独立的,但正方形并不是,所以就打破了这个不变性。 子类的前置条件不能比父类的前置条件更严格。 子类的后置条件不能比父类的后置条件更宽松。
对于这些原则,书中还给出了一系列检查点,比如前置的if条件,是否提早return了,有没有抛出不同的 exception,没有调用super等。
在大多数情况下,composition 都比 subtyping 更好,更容易维护,书中也对 Mixin 等手段做了简单的介绍。
13 Protocols
前面提到的一系列自定义类型,继承与组合等都可以更好的利用类型检查系统来减少程序出错的概率,但这些手段看起来都比较偏向传统的静态类型系统语言的做法。Python 里也提供了非常灵活的 duck typing 的支持,那么我们能不能把类型检查跟 duck typing 结合起来呢?这就引出了这一章要讲的 protocols。利用 protocol 的定义,我们可以很方便的在实现 duck typing 支持的同时,也能利用上类型检查的保护。例如:
from typing import Protocol
class Flyer(Protocol):
def fly(self) -> None:
"""A Flyer can fly"""
class FlyingHero:
"""This hero can fly, which is BEAST."""
def fly(self):
# Do some flying...
class RunningHero:
"""This hero can run. Better than nothing!"""
def run(self):
# Run for your life!
class Board:
"""An imaginary game board that doesn't do anything."""
def make_fly(self, obj: Flyer) -> None: # <- Here's the magic
"""Make an object fly."""
return obj.fly()
def main() -> None:
board = Board()
board.make_fly(FlyingHero())
board.make_fly(RunningHero()) # <- Fails mypy type-checking!
可以看到只需要在 class 中实现了 protocol 中定义的方法就可以了,如果没有,则mypy之类的工具能够检查出不符合 duck typing 要求的实例。在此基础上,本章也介绍了 Protocols 的一些高级功能,如组合,runtime check,针对 module 的 protocol 等。
14 Runtime Checking With pydantic
前面提到的很多类型检查大多只能满足静态代码检查,但在 Python 中还有很多运行时出现的问题,最典型的场景就是用户传入的接口请求,配置读取或者数据库内容获取等。通常来说最直接的防范方式是写很多检查逻辑。本章主要介绍了一个强大的工具pydantic,能够在基础的类型检查的基础上支持更多的业务逻辑检查,非常的好用,例如:
from pydantic.dataclasses import dataclass
from pydantic import conlist, constr
from pydantic import validator
@dataclass
class Restaurant:
name: constr(regex=r'^[a-zA-Z0-9 ]*$',
min_length=1, max_length=16)
owner: constr(min_length=1)
address: constr(min_length=1)
employees: conlist(Employee, min_items=2)
dishes: conlist(Dish, min_items=3)
number_of_seats: PositiveInt
to_go: bool
delivery: bool
@validator('employees')
def check_chef_and_server(cls, employees):
if (any(e for e in employees if e.position == 'Chef') and
any(e for e in employees if e.position == 'Server')):
return employees
raise ValueError('Must have at least one chef and one server')
这本书介绍了不少这类好用的工具,实用性满分!
15 Extensibility
这里开始进入了第三部分,讲可扩展的 Python,即应对不断变化的需求,如何让我们的代码更容易拓展与变更。这一章以一个发送消息通知的例子来进行了介绍,同时也讲了一下“开放封闭原则”。个人比较有收获的是在最后作者也提了一下我们并不是一味的追求可扩展性,如果针对可扩展性做了过度的设计,可能会导致抽象层次过多,可读性下降,且模块的耦合度变高的问题。所以在实际项目中,还是需要根据业务变化的频率来决定具体的代码结构设计。
16 Dependencies
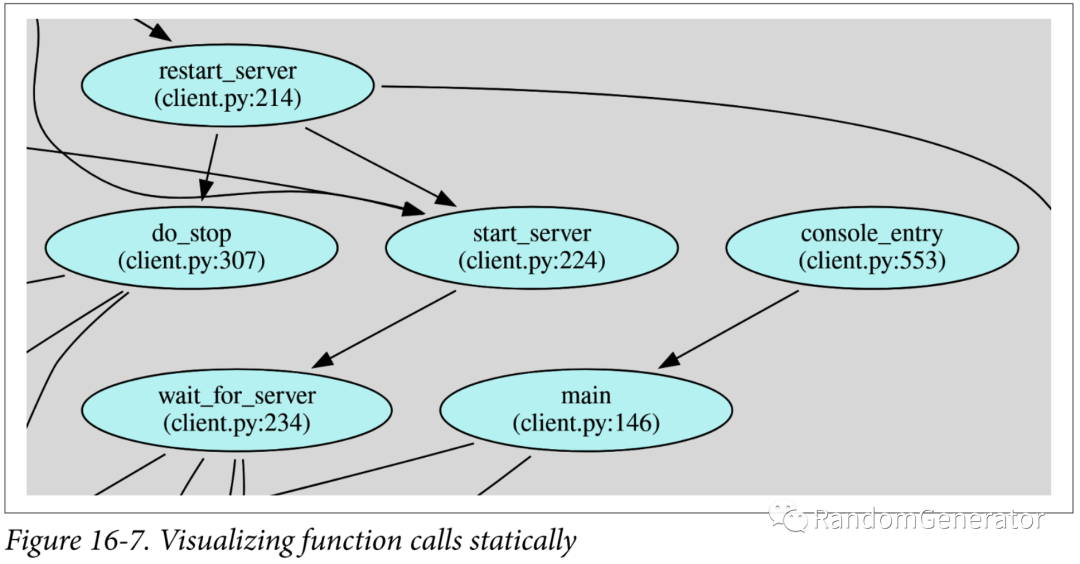
这一章主要介绍了各种依赖,作者分成了三类,包括物理的,逻辑的和时序的,并讨论了一些其中的取舍。比较有意思的后半部分对于各种依赖的可视化展示的工具,包括pipdeptree:
pydeps:
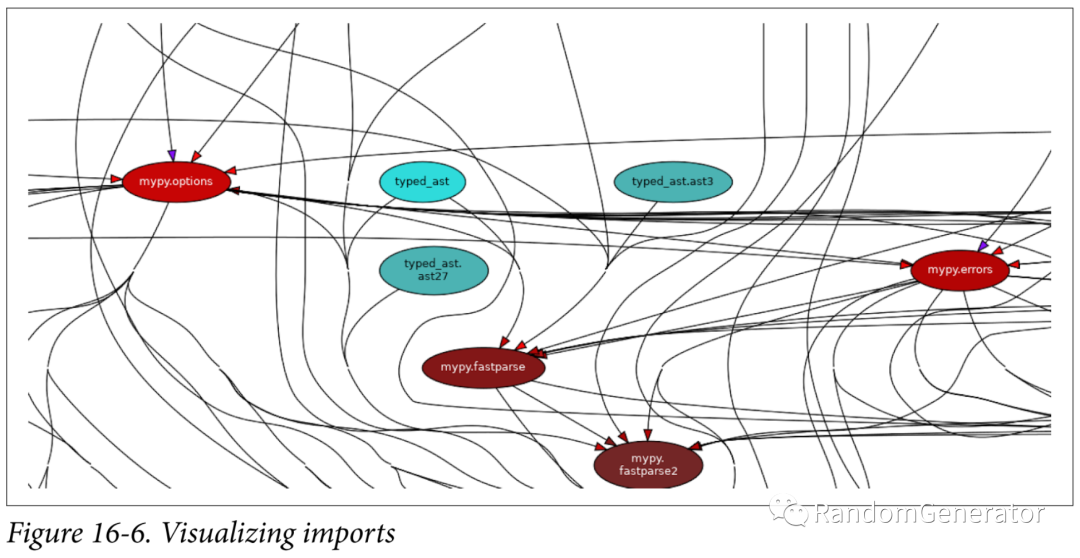
pyan3:
cProfile结合gprof2dot:
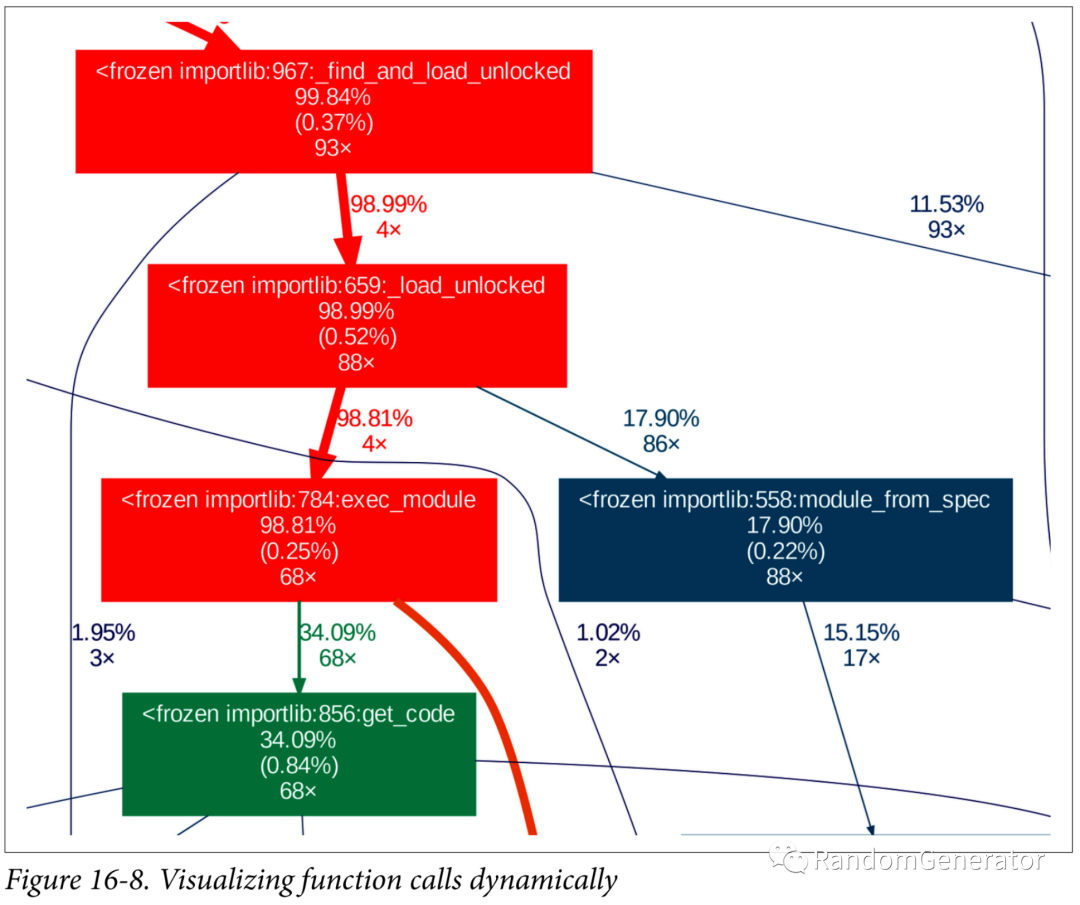
上面这个功能在 PyCharm 里也有。通过可视化,可以检查代码依赖是否清晰。
17 Composability
作者在这一章里继续通过例子来说明如何实践“可组合”的编程,提出了把 policy 和 mechanism 分离的原则,以及函数组合,装饰器,算法组合等话题。这章的内容让我联想到在算法领域很多计算图定义和具体计算执行引擎分离的设计方式,不知道有没有特定的名称来描述这种 pattern。
18 Event-Driven Architecture
前面几章描述的可扩展性实践主要聚焦在项目代码层面,这一章把视角拉高了一些,从整体架构的角度来看这个问题,并介绍了可扩展性、可组合性非常优异的事件驱动架构。具体包括了基础的 PubSub 模式,观察者模式,和更复杂的 streaming event 模式。这本书里介绍的架构相对简单一些,额外介绍了一些 Python 相关的库的支持,如PyPubSub和RxPy。之前介绍的 Python 架构模式里则介绍了更加复杂和完整的消息驱动架构,不过 Python 库这块则用的相对比较基础一些。
19 Pluggable Python
延续上一章介绍了 plug-in 相关的设计模式和系统架构,包括 template pattern 和 startegy pattern。个人对设计模式这块不是很感冒(虽然这本书讲的还算挺 practical,没有硬套一堆 class),不过后面这个 plug-in 架构里作者介绍了一个很强大的 Python 库 stevedore[5],感觉很有意思。例如:
import itertools
from stevedore import extension
Recipe = str
Dish = str
def get_inventory():
return {}
# 遍历所有 plug-in 来获取菜谱
def get_all_recipes() -> list[Recipe]:
mgr = extension.ExtensionManager(
namespace='ultimate_kitchen_assistant.recipe_maker',
invoke_on_load=True,
)
def get_recipes(extension):
return extension.obj.get_recipes()
return list(itertools.chain.from_iterable(mgr.map(get_recipes)))
# 调用具体的 plug-in 来执行 prepare_dish 操作
from stevedore import driver
def make_dish(recipe: Recipe, module_name: str) -> Dish:
mgr = driver.DriverManager(
namespace='ultimate_kitchen_assistant.recipe_maker',
name=module_name,
invoke_on_load=True,
)
return mgr.driver.prepare_dish(get_inventory(), recipe)
20 Static Analysis
进入到了全书的最后一部分,通过构建“安全网”来促进软件的健壮性。这一章先介绍了各种代码静态检查。我观察到很多研发人员在使用 PyCharm 之类的 IDE 做开发时,并不会注意各种代码 warning 的提示,这些其实就是通过静态分析得出的潜在问题。例如代码没有符合 PEP 8 的编码规范,有些申明的变量并没有使用,调用了私有方法等。实际上在大多数的标准工程实践中,应该把这类静态检查加到 CI 流程中,如果没有通过相关检查,不允许做代码的合并。书中作者主要介绍了pylint的使用,另外项目中使用flake8也挺常见的。此外还有一系列针对专门用途的检查工具:
代码复杂度检查工具: mccabe,或者也可以通过检查“空格”的数量来评估代码复杂度密码泄露检查工具:dodgy[6] 安全缺陷检查工具:Bandit[7]
21 Testing Strategy
接下来的几章都跟测试有关,这一章先起个头对测试做个总体介绍。比如各种不同的测试类型:
Unit test Integration test Acceptance test Performance test Load test Security test Usability test
对于不同测试的数量的阐释,把经典的测试三角(界面,集成,单元测试)进一步泛化了一下:
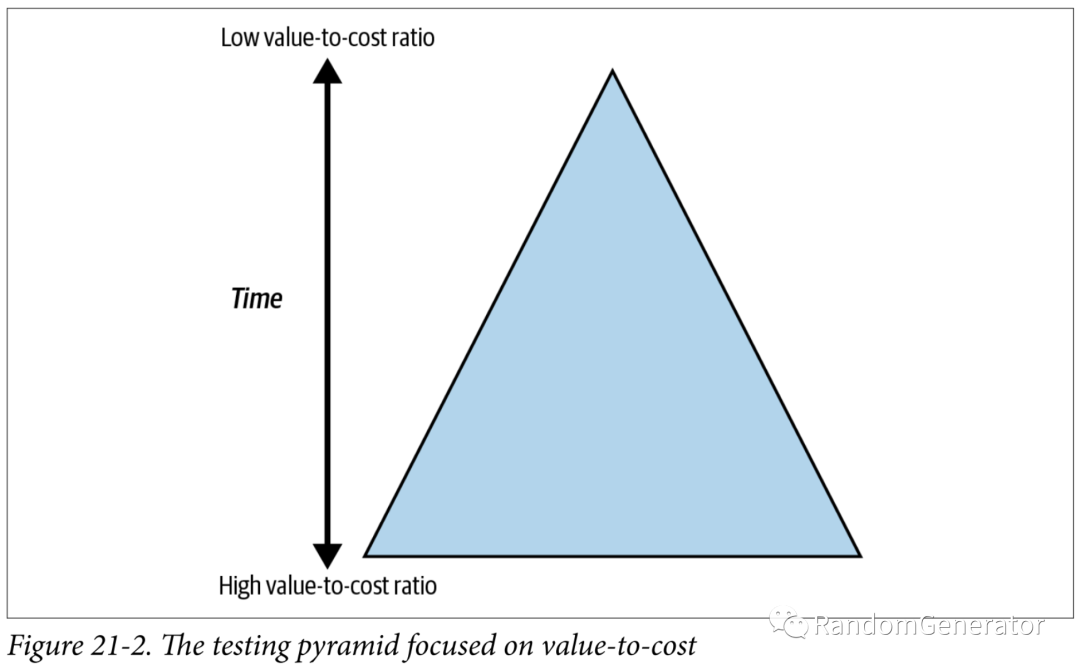
这里的 cost 主要指的是撰写,维护和执行测试所需要的开销。所以也比较好理解,UI 测试一般来说要么使用手工测试,执行成本较高,或者做自动化的话维护成本就很高,一般来说都属于测试数量最少的那一类,位于三角形的顶端。而单元测试这类执行速度快,维护成本低,一般就会数量较多,位于三角形的底部。
后面的部分以pytest为工具,介绍了最常见的 AAA(Arrange-Act-Assert)测试模式,以及其中的一些降低测试成本的技巧,如 fixture,mocking,参数化,Hamcrest matchers[8] 等。个人建议如果不知道如何入手来写测试的话,也可以去参考一些开源项目里的做法,比如 sklearn,pandas 等。
22 Acceptance Testing
前面的pytest比较适用于研发人员对于各种功能 spec 的测试,这一章里作者提出更重要的是我们需要交付符合业务需求的软件,这就需要适用 acceptance 测试来支持了。这章主要介绍的是 Behavior-driven development,包括使用 Gherkin 语言来描述需求,使用behave框架来执行相关的需求验证测试。相应的需求描述长这样:
Feature: Vegan-friendly menu
Scenario: Can substitute for vegan alternatives
Given an order containing a Cheeseburger with Fries
When I ask for vegan substitutions
Then I receive the meal with no animal products
对应的测试:
from behave import given, when, then
@given("an order containing {dish_name}")
def setup_order(ctx, dish_name):
if dish_name == "a Cheeseburger with Fries":
ctx.dish = CheeseburgerWithFries()
elif dish_name == "Meatloaf":
ctx.dish = Meatloaf()
ctx.dish = Meatloaf()
@when("I ask for vegan substitutions")
def substitute_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
ctx.dish.substitute_vegan_ingredients()
@then("I receive the meal with no animal products")
def check_all_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
assert all(is_vegan(ing) for ing in ctx.dish.ingredients())
behave框架还支持生成 junit 格式的 report,然后再通过junit2html转化为 html 格式的报告:
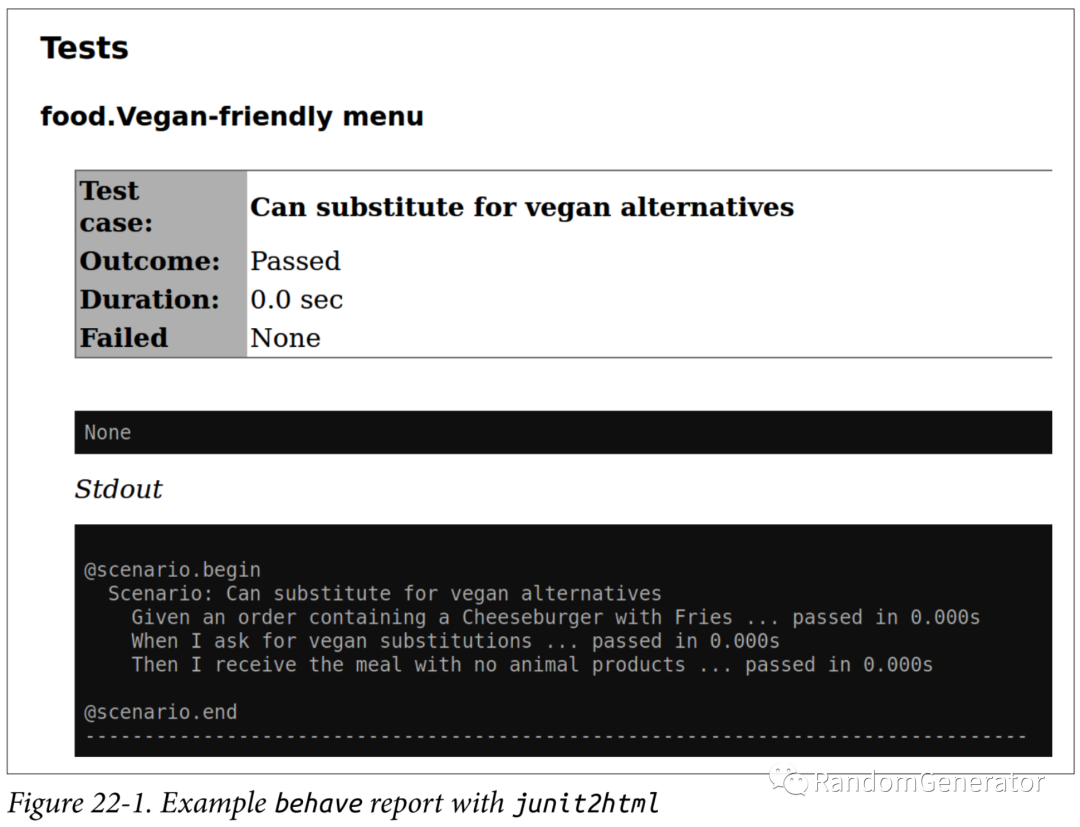
不过个人经历过的项目里,基本没有见过实践 BDD 方法的,不知道各位小伙伴们有没有了解过这方面应用比较好的场景和最佳实践?
23 Property-Based Testing
这一章要介绍的工具有点厉害了,可以自动帮助我们来生成测试!传统的测试中,我们一般是自己构造数据,然后执行测试,最后验证对应的结果符合某个具体数值的预期。而在 property-based 测试中,我们可以指定一些数据的 spec,然后hypothesis这个库会帮忙来生成符合 spec 的随机数据,执行测试,最后我们验证结果符合预期。例如下面这个例子,我们让hypothesis来生成具体的 calories 值,然后测试生成的 meal 推荐符合预期:
from hypothesis import given, example
from hypothesis.strategies import integers
def get_recommended_meal(Recommendation, calories: int) -> list[Meal]:
return [Meal("Spring Roll", 120),
Meal("Green Papaya Salad", 230),
Meal("Larb Chicken", 500)]
@given(integers(min_value=900))
def test_meal_recommendation_under_specific_calories(calories):
meals = get_recommended_meal(Recommendation.BY_CALORIES, calories)
assert len(meals) == 3
assert is_appetizer(meals[0])
assert is_salad(meals[1])
assert is_main_dish(meals[2])
assert sum(meal.calories for meal in meals) < calories
书中还有更多的拓展功能介绍和代码案例,感兴趣的同学可以学习一下。这个库让我想起之前还有个 model-based testing 方法,通过构建应用的状态机模型,来遍历所有状态组合生成各种测试用例。不过这个建模本身的成本有点高,所以见到的应用好像也比较少。
24 Mutation Testing
最后一章也介绍了一种非常有意思的测试类型,“变异测试”。大概的原理就是随机改动原始的代码文件,应该会让原有的测试用例失败,如果没有的话,则表明改动的那一行代码缺少相应的测试来覆盖。例如书中给出的例子:
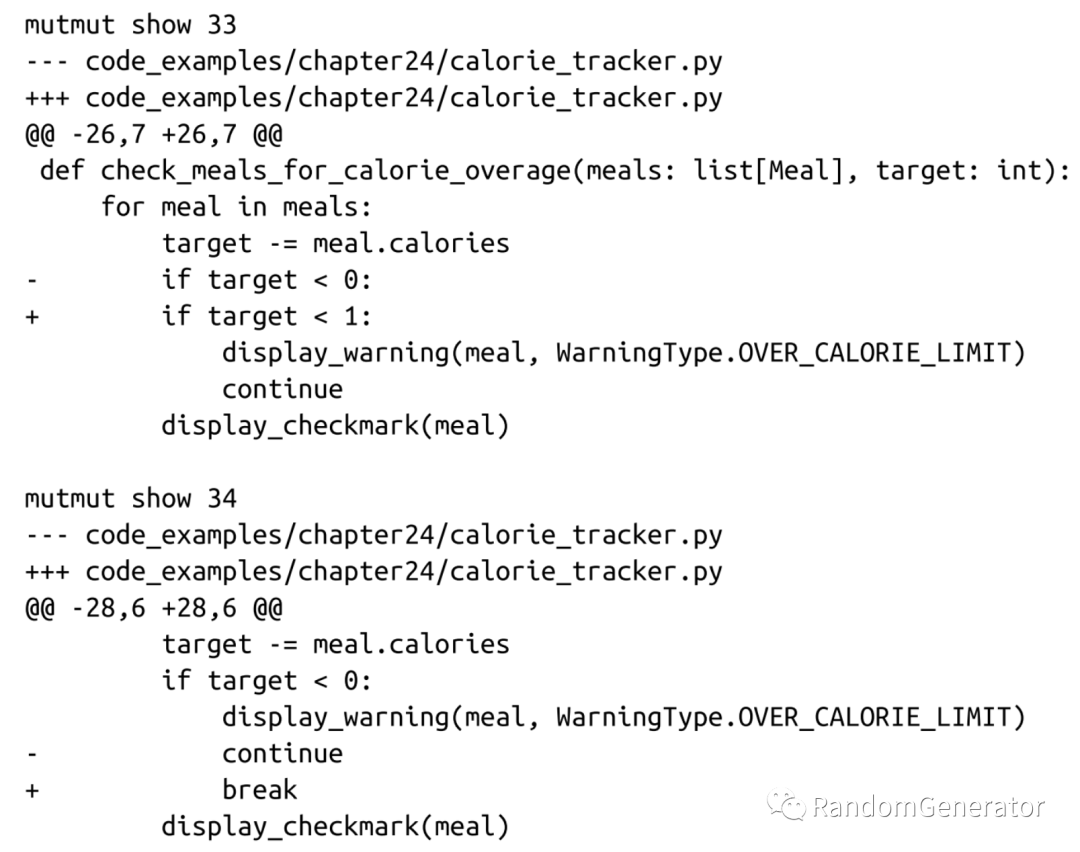
可以看到某些明显改变软件行为的代码当前是缺少测试覆盖的,我们应该进行补充。这个方法对于帮助补充测试用例还是有一定作用的,不过主要问题还是执行这类测试的代价会比较高,而且更适合于已经有比较完善测试覆盖的代码库。书中也给出了一些建议,比如可以根据 code coverage 来执行对应的变异测试。
最后作者还批评了一下各种软件工程中的指标,尤其是通过 code coverage 来代表软件质量的高低。他也建议可以通过变异测试来检查一下高代码覆盖率的测试集是否真的都有效。
参考资料
Python 架构模式: https://zhuanlan.zhihu.com/p/257281522
[2]Robust Python: https://book.douban.com/subject/35553532/
[3]MonkeyType: https://github.com/Instagram/MonkeyType
[4]pytype: https://github.com/google/pytype
[5]stevedore: https://github.com/openstack/stevedore
[6]dodgy: https://github.com/landscapeio/dodgy
[7]Bandit: https://bandit.readthedocs.io/en/latest/
[8]Hamcrest matchers: https://github.com/hamcrest/PyHamcrest

还不过瘾?试试它们