
带你实现完整的视频弹幕系统
作者丨视频团队刘小壮
来源丨搜狐技术产品(ID:sohu-tech)
本文字数:6244字
预计阅读时间:35分钟
+
介绍
弹幕诞生于日本的视频平台,后来被B站这种短视频平台引入到国内,并在国内发展壮大。后来逐渐被长视频平台所接受,现在视频相关的应用基本上都会有弹幕。
但是长视频弹幕和B站这类的短视频弹幕还不太一样,短视频平台有自己特有的弹幕文化,所以弹幕更注重和用户的互动。长视频平台还是以看剧为主,弹幕类似于评论的功能,所以不能影响用户看剧,弹幕不能太密集,而且相互之间最好不要有遮盖,否则会对视频内容会有比较明显的影响。
本篇文章主要从长视频平台的角度来讲弹幕的实现原理,但其实短视频平台的弹幕也是同样的原理,区别在于短视频可能弹幕种类会多一些。
+
技术实现
画布
以我公司应用为例,有iPhone和iPad两个平台,在iPhone平台上有横竖屏的概念,都需要展示弹幕。在iPad上有大小屏的概念,也需要都展示弹幕。弹幕的技术方案肯定是两个平台用一套,但需要考虑跨不同设备和屏幕的情况。
所以,对于这个问题,我通过画布的概念来解决通用性的问题。画布并不区分屏幕大小和比例的概念,只是单纯的用来展示弹幕,并不处理其他业务逻辑,通过一个Render类来控制画布的渲染。对于不同设备上的差异,例如iPad字体大一些,iPhone字体小一些这种情况,通过config类来进行控制,画布内部不做判断。
小屏上画布会根据比例少展示一些,大屏上则多展示一些。字体变大画布也会根据比例和左右间距进行控制,保证展示比例是对的,并且在屏幕宽高发生改变后,自动适应新的尺寸,不会出现弹幕衔接断开的问题,例如iPad上大小屏切换。外部在使用时,只需要传入一个frame即可,不需要关注画布内部的调整。
弹幕轨道

从屏幕上来看,可以看到弹幕一般都是一行一行的。为了方便对弹幕视图进行管理,以及后续的扩展工作,我对弹幕设计了“轨道”的概念。每一行都是一个轨道,对弹幕进行横向的管理,这一行包括速度、末端弹幕、高度等参数,这些参数适用于这一行的所有弹幕。轨道是一个虚拟的概念,并没有对应的视图。
轨道有对应的类来实现,类中会包含一个数组,数组中有这一行所有的弹幕。这个思路有点像玩过的一款游戏-节奏大师,里面也有音乐轨道的概念,每个轨道上对应不同速度和颜色的音符,音符数量也是不固定的,根据节奏来决定。
轨道还有一个好处在于,对于不同速度的弹幕比较好控制。例如腾讯视频的弹幕其实是不同速度的,但是你仔细观察的话,可以发现他们的弹幕是“奇偶行不同速”,也就是奇数行一个速度,偶数行一个速度,让人从感官上来觉得所有弹幕的速度都不一样。如果通过轨道的方式就很好实现,不同的轨道根据当前所在行数,对发出的弹幕设置不同的速度即可。

有时候看视频过程中会从右侧出现一条活动弹幕,可能是视频中的梗,也可能是类似于广告的互动。但是活动弹幕出现时一般是单行清屏的,也就是和普通弹幕是互斥的,展示活动弹幕的时候前后没有普通弹幕。这种通过轨道的方式也比较好实现,每条弹幕都对应一个时间段,根据活动弹幕的时间和速度,将活动弹幕展示的前后时间,将这段时间轨道暂时关闭,只保留活动弹幕即可。
轮询
每条弹幕都对应着一个展示时间,所以需要每隔一段时间就找一下有没有需要展示的弹幕。我设计的方案是通过轮询,来驱动弹幕展示。
通过CADisplayLink来进行轮训,将frameInterval设置为60,即每秒轮询一次。在轮询的回调中查找有没有要展示的弹幕,有的话就从上到下查找每条轨道,某条轨道有位置可以展示的话就交给这条轨道展示,如果所有轨道都有正在展示的弹幕,则将此条弹幕丢弃。是否有位置是根据屏幕最右侧,最后一条弹幕是否已经展示完全,并且后面有空余位置来决定的。
对于取数据的部分,数据和视图的逻辑是分离的,相互之间并没有耦合关系。取数据时只是从一个很小的字典中,根据时间取出所用的弹幕数据,并转化为model。字典的数据很少,最多十秒的数据,而且这里并不会接触到读数据库的操作,也没有网络请求的逻辑,这些都是独立的逻辑,后面会讲到。
弹幕视图
经常看视频的同学应该会知道,弹幕的展示形式有很多,有带明星头像的、有带点赞数的、带矩形背景色的,很多种展示形态。为了更好的对视图进行组织,所以我采用的就是很普通的UIView的展示形式,并没有为了性能去做很复杂的渲染操作。
用UIView的好处主要就是方便做布局和子视图管理,但在屏幕上做动画时,是对CALayer进行渲染的。也就是说UIView就是用来做视图组织,并不会直接参与渲染,这也符合苹果的设计理念。
复用池

弹幕是一个高频使用的控件,所以不能一直频繁创建,以及添加和移除视图,会对性能有影响。所以就像很多同学设计的模块一样,我也引入了缓存池的概念,我这里叫复用池。
弹幕复用池和UITableView的复用池类似,离开屏幕的弹幕会被放在复用池中等待复用,下次直接从复用池中取而不重新创建。弹幕视图做的工作就是接收新的model对象,并根据弹幕类型进行不同的视图布局。
并且弹幕只会在创建时被addSubview一次,当弹幕离开屏幕不会被从父视图移除,这样弹幕从复用池中取出时也不需要被addSubview。当动画执行完成后,弹幕就直接留在动画结束的位置,下次做动画时弹幕会自动回到fromValue的位置。实际上视图结构就如上图所示,灰色区域就是可视区域。
系统弹幕

在视频刚开始时会有引导信息,比如引导用户发弹幕,或者提示弹幕有多少条,这个我们叫做系统弹幕。系统弹幕一般是展示到屏幕中间时,才开始展示后续弹幕。但是要精确的计算到弹幕到达屏幕中间,然后再展示后续弹幕,这种的采用清除前后特定时间段的弹幕就不太精确,所以我们采用的是另一套实现方案。
系统弹幕的实现是通过一个更高精度的CADisplayLink进行轮询检测,也就是把frameInterval设置的更小,我这里设置的是10,也就是每秒检测六次。但是进行检测时不能直接用CALayer进行判断,需要使用presentationLayer也就是屏幕上正在展示的layer进行检测,通过这个layer获取到的frame和屏幕上显示的才是一致的。
这里简单介绍一下CALayer的结构,我们都知道UIView是对CALayer的一层封装,实际上屏幕上的显示都是通过layer来实现的,而layer本身也分为以下三层,并有不同的功能。
presentationLayer,其本身是当前帧的一个拷贝,每次获取都是一个新的对象,和动画过程中屏幕上显示的位置是一样的。 modelLayer,表示 layer动画完成后的真实值,如果打印一下modelLayer和layer的话,发现二者其实是一个对象。renderLayer,渲染帧,应用程序会根据视图层级,构成由 layer组成的渲染树,renderLayer就代表layer在渲染树中的对象。
炫彩弹幕
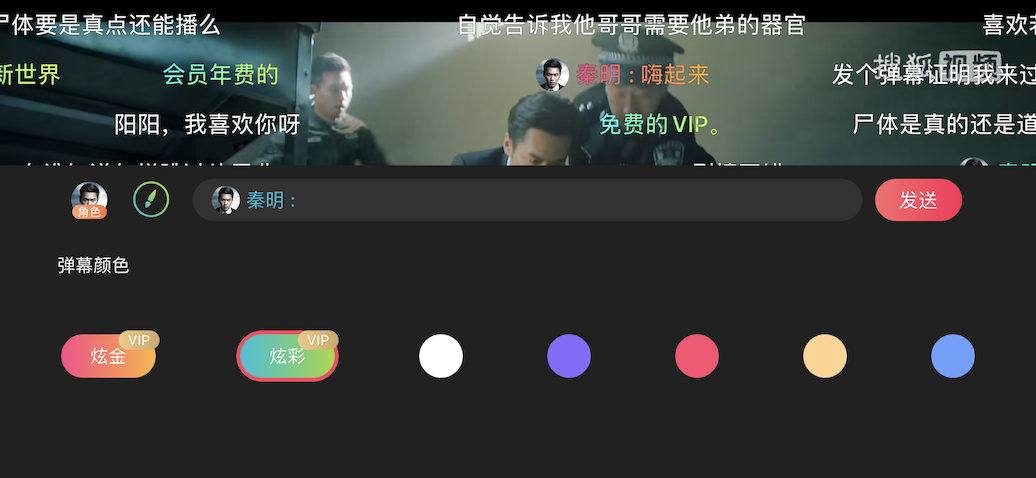
在播放弹幕的过程中,我们可以看到有渐变颜色的弹幕,我们叫做“炫彩弹幕”。这种弹幕有一个很明显的特征,就是其颜色是渐变的。这时候要考虑性能的问题,因为播放高清视频时本身性能消耗就很大,在弹幕量比较大的情况下,会造成更多的性能消耗,所以减少性能消耗就是很重要的,渐变弹幕可能会使性能消耗加剧。
对于渐变文字,一般都是通过mask的方式实现,下面放一个CAGradientLayer做渐变,上面盖一个文字的layer。但是这种会触发离屏渲染,会导致性能下降,并不能用这种方案。经过我们的尝试,决定用设置渐变文字颜色的方式解决。
CGFloat scale = [UIScreen mainScreen].scale;
UIGraphicsBeginImageContextWithOptions(imageSize, NO, scale);
CGContextRef context = UIGraphicsGetCurrentContext();
CGContextSaveGState(context);
CGColorSpaceRef colorSpace = CGColorGetColorSpace([[colors lastObject] CGColor]);
CGGradientRef gradient = CGGradientCreateWithColors(colorSpace, (CFArrayRef)ar, NULL);
CGPoint start = CGPointMake(0.0, 0.0);
CGPoint end = CGPointMake(imageSize.width, 0.0);
CGContextDrawLinearGradient(context, gradient, start, end, kCGGradientDrawsBeforeStartLocation | kCGGradientDrawsAfterEndLocation);
UIImage *image = UIGraphicsGetImageFromCurrentImageContext();
CGGradientRelease(gradient);
CGContextRestoreGState(context);
UIGraphicsEndImageContext();
实现方式就是先开辟一个上下文,用来进行图片绘制,随后对上下文进行一个渐变的绘制,最后获取到一个UIImage,并将图片赋值给UILabel的textColor即可。
从离屏检测来看,并未发生离屏渲染,fps也始终保持在一个很高的水平。
暂停和开始
弹幕是随视频播放和暂停的,所以需要对弹幕提供暂停和继续的支持,对于这块我采用的CAMediaTiming协议来处理,可以通过此协议对动画的过程进行控制。
代码中加0.05是为了避免弹幕在暂停时导致的回跳,所以加上一个时间差。具体原因是因为通过convertTime:fromLayer:方法计算得到的时间,和屏幕上弹幕的位置依然存在一个微弱的时间差,而导致渲染时视图位置发生回跳,这个0.05是一个实践得来的经验值。
- (void)pauseAnimation {
// 增加判断条件,避免重复调用
if (self.layer.speed == 0.f) {
return;
}
CFTimeInterval pausedTime = [self.layer convertTime:CACurrentMediaTime() fromLayer:nil];
self.layer.speed = 0.f;
self.layer.timeOffset = pausedTime + 0.05f;
}
- (void)resumeAnimation {
// 增加判断条件,避免重复调用
if (self.layer.speed == 1.f) {
return;
}
CFTimeInterval pausedTime = self.layer.timeOffset;
self.layer.speed = 1.0;
self.layer.timeOffset = 0.0;
self.layer.beginTime = 0.0;
CFTimeInterval timeSincePause = [self.layer convertTime:CACurrentMediaTime() fromLayer:nil] - pausedTime;
self.layer.beginTime = timeSincePause;
}
CAMediaTiming协议是用来对动画过程控制的一个协议,例如通过CoreAnimation创建的动画,CALayer遵守了这个协议。这样如果需要对动画进行控制的话,不需要引用一个CABasicAnimation对象,然后再修改动画属性这种方式对动画流程进行控制,只需要直接对layer的属性进行修改即可。
下面是CAMediaTiming协议中一些关键的属性,在上文中也用到了其中的部分属性。
beginTime,动画开始时间,可以控制动画延迟展示。一般是一个绝对时间,为了保证准确性,最好先对当前 layer进行一个转换,延迟展示在后面加对应的时间即可。duration,动画结束时间。 speed,动画执行速度,默认是1。动画最终执行时间= duration/speed,也就是duration是3秒,speed是2,最终动画执行时间是1.5秒。timeOffset,控制动画进程,主要用来结合 speed来对动画进行暂停和开始。repeatCount,重复执行次数,和 repeatDuration互斥。repeatDuration,重复执行时间,如果时间不是 duration的倍数,最后一次的动画会执行不完整。autoreverses,动画反转,在动画执行完成后,是否按照原先的过程反向执行一次。此属性会对 duration有一个叠加效果,如果duration是1s,autoreverses设置为YES后时间就是2s。fillMode,如果想要动画在开始时,就停留在 fromValue的位置,就可以设置为kCAFillModeBackwards。如果想要动画结束时停留在toValue的位置,就设置为kCAFillModeForwards,如果两种都要就设置为kCAFillModeBoth,默认是kCAFillModeRemoved,即动画结束后移除。
+
发送弹幕
插入弹幕
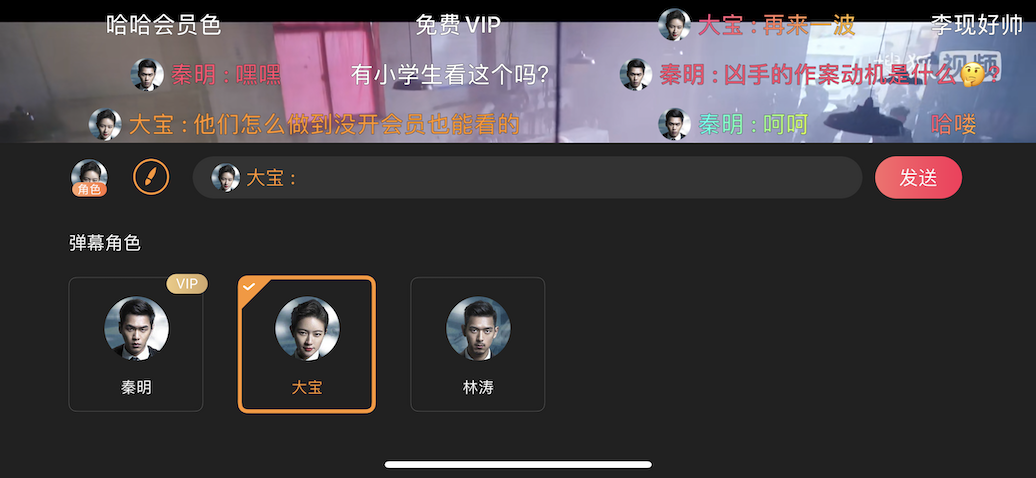
现在弹幕一般都会结合剧中主角,以及各种文字颜色让你去选择,通过这些功能也可以带来一部分付费用户。当发送一条弹幕时,会从上到下查找轨道,查找轨道时是通过presentationLayer来进行frame的判断,如果layer的最右边不在屏幕外,并且距离右侧屏幕还有一定空隙,项目中写的是10pt,则表示有空位可以插入下一条弹幕,这条弹幕会被放在这条轨道上。
如果当前轨道没有空位置,则从上到下逐条查找轨道,直到找到有空位的轨道。如果当前屏幕上弹幕较多,所有轨道都没有空位,则这一条弹幕会被抛弃。
如果是自己发的弹幕,这个是必须要展示出来的,因为用户发的弹幕要在界面上给用户一个反馈。对于自己发的弹幕,会有一个插队操作,优先级比其他弹幕都要高。自己发的弹幕并不入本地数据库,只是进行一个网络请求传给服务器,以及在界面上进行展示。
选择角色
在上面的图片中可以看到,文本之前会有角色和角色名,这些都是独立于输入文字之外的。用户如果删除完输入的文字之后,再点击删除要把角色也一起删除掉。输入框页面构成是一个UITextField,左边的角色头像和角色名是一个自定义View,被当做textField的leftView来展示。如果删除的话就是将leftView置nil即可。
问题在于,如果使用UIControlEventEditingChanged的事件,只能获取到文本发生变化时的内容,如果输入框的文字已经被删完,而角色是一个leftView,但由于文本已经为空,则无法再获取到删除事件,也就不能把角色删除掉。
对于这个问题,我们找到了下面的协议来实现。UITextField遵守UITextInput协议,但UITextInput协议继承自UIKeyInput协议,所以也就拥有下面两个方法。下面两个方法分别在插入文字,以及点击删除按钮时调用,即使文本已经为空,依然可以收到deleteBackward的回调。在这个回调里就可以判断文本是否为空,如果为空则删除角色即可。
@protocol UIKeyInput <UITextInputTraits>
@property(nonatomic, readonly) BOOL hasText;
- (void)insertText:(NSString *)text;
- (void)deleteBackward;
@end
+
弹幕设置
参数调整

弹幕一般都不是一种形态,很多参数都是可以调整的,对于iPhone和iPad两个平台参数还不一样,调整范围也不一样。这些参数肯定是不能放在业务代码里进行判断的,这样各种判断条件散落在项目中,会导致代码耦合严重。
对于这个问题,我们的实现方式是通过BarrageConfig来区分不同平台,将两个平台的数值差异都放在这个类中。业务部分直接读取属性即可,不需要做任何判断,包括退出进程的持久化也在内部完成,这样就可以让业务部分使用无感知,也保证了各个类中的数值统一。
当有任何参数的改动,都可以对BarrageConfig进行修改,然后调用Render的layoutBarrageSubviews进行渲染即可。因为调整参数之后,屏幕上已经显示的弹幕也需要跟着变,而且变得过程中还是在动画执行过程中,动画执行不能断掉,所以对动画的处理就很重要。这部分处理起来比较复杂,就不详细讲了。
点赞

弹幕还会有点赞和长按的功能,点赞一般是点击屏幕然后出现一个选择视图,点击点赞后有一个动画效果。长按就是选中一个弹幕,识别到手势长按之后,右侧出现一个举报页面。
这两个手势我用tap和longPress两个手势来处理,并给longPress设置了一个0.2s的识别时间,将这两种手势的识别交给系统去做,这样也比较省事。
这两个手势都加到Render上,而不是每个弹幕视图对应一个手势,这样管理起来也比较简单。这样在手势识别时,就需要先找到手势触摸点,再根据触摸点查找对应的弹幕视图,查找的时候依然通过presentationLayer来查找区域,而不能用视图做查找。
- (void)singleTapHandle:(UITapGestureRecognizer *)tapGestureRecognizer {
CGPoint touchLocation = [tapGestureRecognizer locationInView:self.barrageRender];
__block BOOL barrageLiked = NO;
weakifyself;
[self enumerateObjectsUsingBlock:^(SVBarrageItemLabelView *itemLabel, NSUInteger index, BOOL *stop) {
strongifyself;
if ([itemLabel.layer.presentationLayer hitTest:touchLocation] && barrageLiked == NO) {
barrageLiked = YES;
[self likeAction:itemLabel withTouchLocation:touchLocation];
*stop = YES;
}
}];
}
+
弹幕广告
广告
对于这么好的一个展示位置,广告部门必然不会放过。在视频播放过程中,会根据金主爸爸投放要求,在指定的时间展示一个广告弹幕,并且这个弹幕的形态还是不固定的。也就是说大小、动画形式都不能确定,而且这条弹幕还要在最上层展示。
对于这个问题,我们采用的方案是,给广告专门留了一个视图,视图层级高于Render,在初始化广告SDK的时候传给SDK,这样就把广告弹幕的控制交给SDK,我们不做处理。
图层管理
播放器上存在很多图层,播控、弹幕Render、广告之类的,看得到的和看不到的有很多。对于这个问题,播放器创建了一个继承自NSObject的视图管理器,这个视图管理器可以对视图进行分层管理。
播放器上的视图,都需要调用指定的方法,将自己加到对应的图层上,移除也需要调用对应的方法。当需要调整前后顺序时,修改定义的枚举即可。
+
数据分离
前面一直说的都是视图的部分,没有涉及数据的部分,这是因为UI和数据其实是解耦和的,二者并没有强耦合,所以可以单独拿出来讲。数据部分的设计,类似于播放器的local server方案,将请求数据到本地,和从本地读取数据做了一个拆分。
请求数据
弹幕数据量比较大,肯定是不能一次都请求下来的,这样很容易造成请求失败的情况。所以这块采取的是五分钟一个分片数据,在当前的五分钟弹幕快播完的前十秒,开始请求下一个时间段的弹幕。如果拖动进度条,则拖动完成后开始请求新位置的弹幕。在每次请求前都会查一下库,数据是否已存在。
请求数据由业务部分驱动,请求数据后并不会直接拿来使用,而是存入本地数据库,这部分比较像服务器往本地写ts分片的操作。数据库存储的部分,推荐使用WCDB,弹幕这块主要都是批量数据处理,而WCDB对于批量数据的处理,性能高于FMDB。
取数据
取数据同样由业务层驱动,为了减少频繁进行数据库读写,每隔十秒钟进行一次数据库批量读取,并转换为model返回给上层。弹幕模块在内存中维护了一个字典,字典以时间为key,数组为value,因为同一时间可能会有多条弹幕。
从数据库批量获取的数据会被保存到字典中,上层业务层在使用数据时,都是通过字典来获取数据,这样也实现了数据层和业务层的一个解耦和。上层业务层每隔一秒从字典中读取一次数据,并通过数据找到合适的轨道,将数据传给合适的轨道来处理。
+
弹幕防挡探索

现在很多视频网站都上线了弹幕防遮挡方案,对于视频中的人物,弹幕会在其下方展示,而不会遮挡住人物。还有的应用针对弹幕遮挡进行了新的探索,即成为付费会员后,可以选择只有自己喜欢的爱豆不被遮挡,其他人依然被遮挡。
语义分割
根据业务场景我们分析,首先需要把人像部分分割出来,获取到人像的位置之后才能做后续的操作。所以人像分割的部分采取语义分割的方式实现,提前对视频关键帧进行标注,这个工作量是很庞大的,所以需要一个专门的标注团队去完成。根据标注后的模型,通过机器学习的方式,让计算机可以准确的识别出人的位置,并导出多边形路径。
这里面还涉及一个问题,就是近景识别和远景识别的问题,机器进行识别时只需要识别近景人物,远景人物并不需要进行识别,否则弹幕展示效果会受到很大影响。语义分割可以通过Google的Mask_RCNN来实现。
客户端实现方案
客户端的实现方案是通过人像的多边形路径,对原视频抠出人像并导出一个新的视频。在播放的时候实际上是前后两个播放器在播放,弹幕夹在两个播放器中间来实现的。并且前面的人像层需要做边缘虚化,让弹幕的过渡显得自然些,否则会太突兀。
这种方案的过渡效果会好一些。因为对每一帧视频进行切割的时候,每一帧并不能保证相邻帧切割的边缘相差都不大,也就是相邻近的帧边缘不能保证很好的衔接,这样就容易出现视频连续性的问题。前后两个播放器叠加的方案,两个层的视频内容实际上是衔接很紧密的,把弹幕层去掉你根本看不出来这是两层播放器,所以连续性的问题就不明显了。
前端实现方案
前端的实现方案是服务端将多边形路径放在一个svg文件中,并将文件下发给前端,前端通过css的mask‑image遮罩实现的。通过遮罩把人像部分抠出来,人像之外依然是黑色区域,黑色是可显示区域,和iOS的mask属性类似。
B站是最开始做弹幕防挡的,现在B站已经不局限于真人弹幕防挡了,现在很多番剧中的动漫人物也支持弹幕防挡。可以看下面的视频感受一下。
B站番剧弹幕防挡视频链接:https://www.bilibili.com/video/BV1Db411C7hJ
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
面试题】即可获取