
SpringCloud Alibaba之Seata分布式事务
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
分布式事务基础
A:原子性(Atomicity),一个事务中的所有操作,要么全部完成,要么全部不完成
C:一致性(Consistency),在一个事务执行之前和执行之后数据库都必须处于一致性状态
I:隔离性(Isolation),在并发环境中,当不同的事务同时操作相同的数据时,事务之间互不影响
D:持久性(Durability),指的是只要事务成功结束,它对数据库所做的更新就必须永久地保存下来
分布式事务
分布式事务的场景
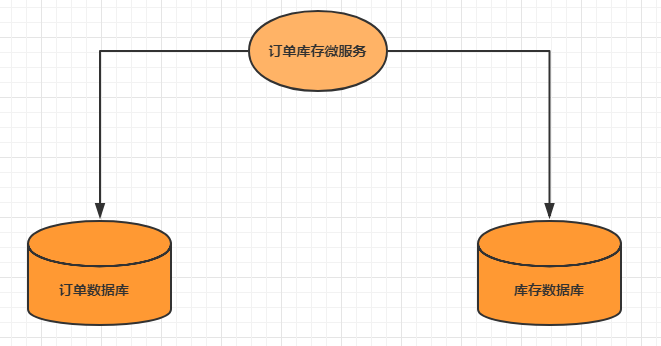
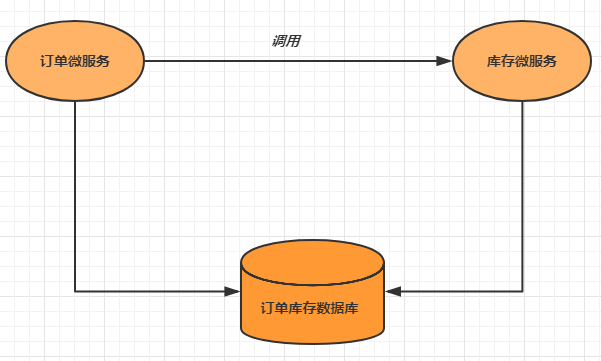
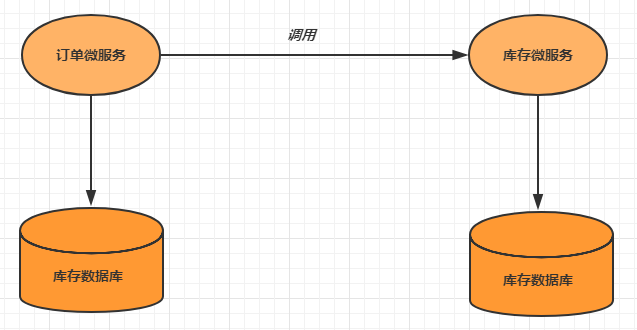
分布式事务解决方案
AP: Application 应用系统 (微服务)
TM: Transaction Manager 事务管理器 (全局事务管理)
RM: Resource Manager 资源管理器 (数据库)
阶段一: 表决阶段,所有参与者都将本事务执行预提交,并将能否成功的信息反馈发给协调者。
阶段二: 执行阶段,协调者根据所有参与者的反馈,通知所有参与者,步调一致地执行提交或者回滚。
提高了数据一致性的概率,实现成本较低
单点问题: 事务协调者宕机
同步阻塞: 延迟了提交时间,加长了资源阻塞时间
数据不一致: 提交第二阶段,依然存在commit结果未知的情况,有可能导致数据不一致
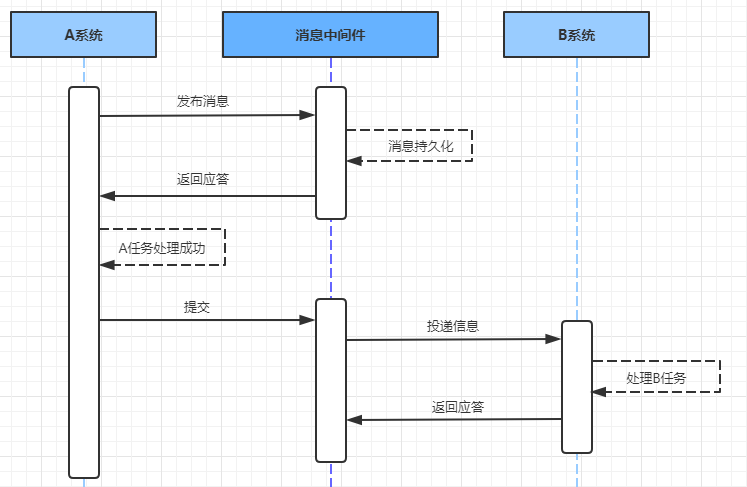
在系统A处理任务A前,首先向消息中间件发送一条消息
消息中间件收到后将该条消息持久化,但并不投递。持久化成功后,向A回复一个确认应答
系统A收到确认应答后,则可以开始处理任务A
任务A处理完成后,向消息中间件发送Commit或者Rollback请求。该请求发送完成后,对系统A而言,该事务的处理过程就结束了
如果消息中间件收到Commit,则向B系统投递消息;如果收到Rollback,则直接丢弃消息。但是如果消息中间件收不到Commit和Rollback指令,那么就要依靠"超时询问机制"。
如果消息中间件收到确认应答后便认为该事务处理完毕
如果消息中间件在等待确认应答超时之后就会重新投递,直到下游消费者返回消费成功响应为止。
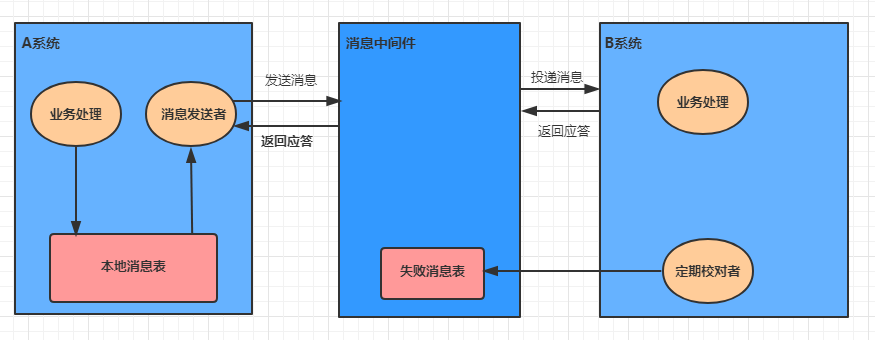
处理业务的同一事务中,向本地消息表中写入一条记录
准备专门的消息发送者不断地发送本地消息表中的消息到消息中间件,如果发送失败则重试
消息中间件收到消息后负责将该消息同步投递给相应的下游系统,并触发下游系统的任务执行
当下游系统处理成功后,向消息中间件反馈确认应答,消息中间件便可以将该条消息删除,从而该事务完成
对于投递失败的消息,利用重试机制进行重试,对于重试失败的,写入错误消息表
消息中间件需要提供失败消息的查询接口,下游系统会定期查询失败消息,并将其消费
优点: 一种非常经典的实现,实现了最终一致性。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
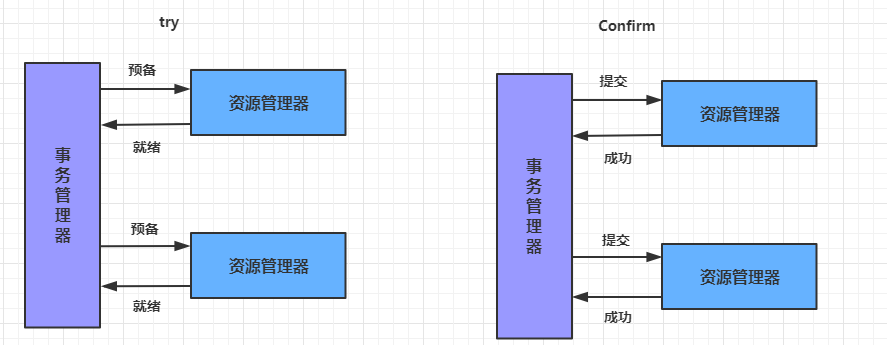
Try: 尝试待执行的业务:这个过程并未执行业务,只是完成所有业务的一致性检查,并预留好执行所需的全部资源
Confifirm: 确认执行业务:确认执行业务操作,不做任何业务检查, 只使用Try阶段预留的业务资源。通常情况下,采用TCC则认为 Confifirm阶段是不会出错的。即:只要Try成功,Confifirm一定成功。若Confifirm阶段真的出错了,需引入重试机制或人工处理。
Cancel: 取消待执行的业务:取消Try阶段预留的业务资源。通常情况下,采用TCC则认为Cancel阶段也是一定成功的。若Cancel阶段真的出错了,需引入重试机制或人工处理
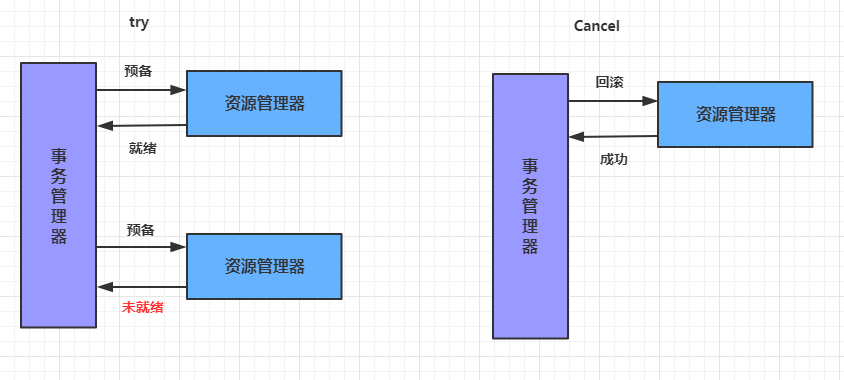
XA是资源层面的分布式事务,强一致性,在两阶段提交的整个过程中,一直会持有资源的锁。
TCC是业务层面的分布式事务,最终一致性,不会一直持有资源的锁。
优点:把数据库层的二阶段提交上提到了应用层来实现,规避了数据库层的2PC性能低下问题。
缺点:TCC的Try、Confifirm和Cancel操作功能需业务提供,开发成本高。
Seata介绍
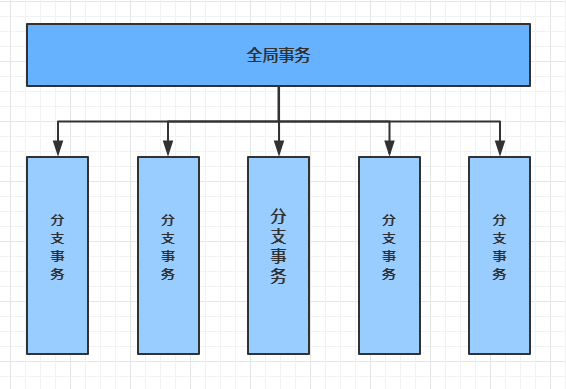
TC:Transaction Coordinator 事务协调器,管理全局的分支事务的状态,用于全局性事务的提交和回滚。
TM:Transaction Manager 事务管理器,用于开启、提交或者回滚全局事务。
RM:Resource Manager 资源管理器,用于分支事务上的资源管理,向TC注册分支事务,上报分支事务的状态,接受TC的命令来提交或者回滚分支事务。
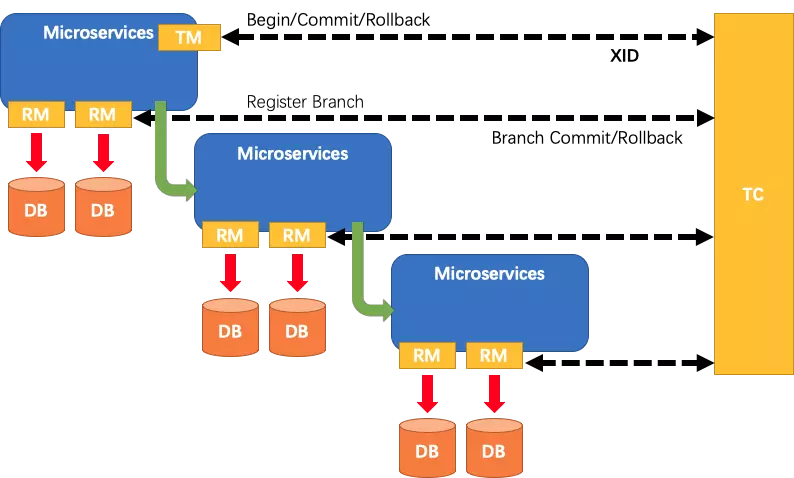
A服务的TM向TC申请开启一个全局事务,TC就会创建一个全局事务并返回一个唯一的XID
A服务的RM向TC注册分支事务,并及其纳入XID对应全局事务的管辖
A服务执行分支事务,向数据库做操作
A服务开始远程调用B服务,此时XID会在微服务的调用链上传播
B服务的RM向TC注册分支事务,并将其纳入XID对应的全局事务的管辖
B服务执行分支事务,向数据库做操作
全局事务调用链处理完毕,TM根据有无异常向TC发起全局事务的提交或者回滚
TC协调其管辖之下的所有分支事务, 决定是否回滚
架构层次方面,传统2PC方案的 RM 实际上是在数据库层,RM本质上就是数据库自身,通过XA协议实现,而 Seata的RM是以jar包的形式作为中间件层部署在应用程序这一侧的。
两阶段提交方面,传统2PC无论第二阶段的决议是commit还是rollback,事务性资源的锁都要保持到Phase2完成才释放。而Seata的做法是在Phase1 就将本地事务提交,这样就可以省去Phase2持锁的时间,整体提高效率
Seata实现分布式事务控制
@RestController
@Slf4j
public class OrderController5 {
@Autowired
private OrderServiceImpl5 orderService;
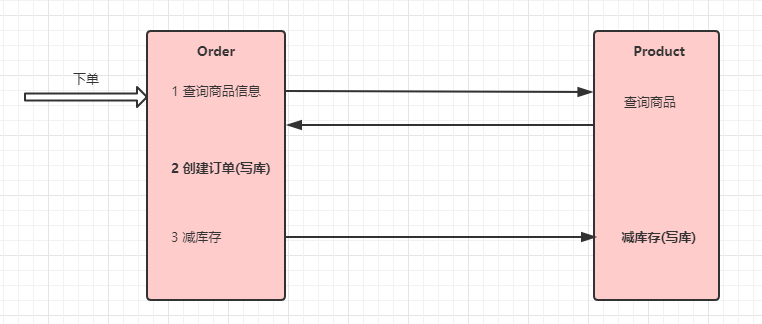
//下单
@RequestMapping("/order/prod/{pid}")
public Order order(@PathVariable("pid") Integer pid) {
log.info("接收到{}号商品的下单请求,接下来调用商品微服务查询此商品信息", pid);
return orderService.createOrder(pid);
}
}
@Service
@Slf4j
public class OrderServiceImpl5{
@Autowired
private OrderDao orderDao;
@Autowired
private ProductService productService;
@Autowired
private RocketMQTemplate rocketMQTemplate;
@GlobalTransactional
public Order createOrder(Integer pid) {
//1 调用商品微服务,查询商品信息
Product product = productService.findByPid(pid);
log.info("查询到{}号商品的信息,内容是:{}", pid, JSON.toJSONString(product));
//2 下单(创建订单)
Order order = new Order();
order.setUid(1);
order.setUsername("测试用户");
order.setPid(pid);
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
orderDao.save(order);
log.info("创建订单成功,订单信息为{}", JSON.toJSONString(order));
//3 扣库存
productService.reduceInventory(pid, order.getNumber());
//4 向mq中投递一个下单成功的消息
rocketMQTemplate.convertAndSend("order-topic", order);
return order;
}
}
@FeignClient(value = "service-product")
public interface ProductService {
//减库存
@RequestMapping("/product/reduceInventory")
void reduceInventory(@RequestParam("pid") Integer pid, @RequestParam("num")
int num);
}
//减少库存
@RequestMapping("/product/reduceInventory")
public void reduceInventory(Integer pid, int num) {
productService.reduceInventory(pid, num);
}
@Override
public void reduceInventory(Integer pid, int num) {
Product product = productDao.findById(pid).get();
product.setStock(product.getStock() - num);
//减库存
productDao.save(product);
}
@Override
public void reduceInventory(Integer pid, Integer number) {
Product product = productDao.findById(pid).get();
if (product.getStock() < number) {
throw new RuntimeException("库存不足");
}
int i = 1 / 0;
product.setStock(product.getStock() - number);
productDao.save(product);
}
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
service.vgroup_mapping.service-product=default
service.vgroup_mapping.service-order=default
\# 初始化seata 的nacos配置
\# 注意: 这里要保证nacos是已经正常运行的
cd conf
nacos-config.sh 127.0.0.1
cd bin
seata-server.bat -p 9000 -m file
CREATE TABLE `undo_log`
(
`id` BIGiNT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGiNT(20) NOT NULL,
`xid` VARcHAR(100) NOT NULL,
`context` VARcHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` iNT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARcHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Primary
@Bean
public DataSourceProxy dataSource(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
spring:
application:
name: service-product
cloud:
nacos:
config:
server-addr: localhost:8848 # nacos的服务端地址
namespace: public
group: SEATA_GROUP
alibaba:
seata:
tx-service-group: ${
spring.application.name
}
@GlobalTransactional//全局事务控制
public Order createOrder(Integer pid) {}
seata运行流程分析
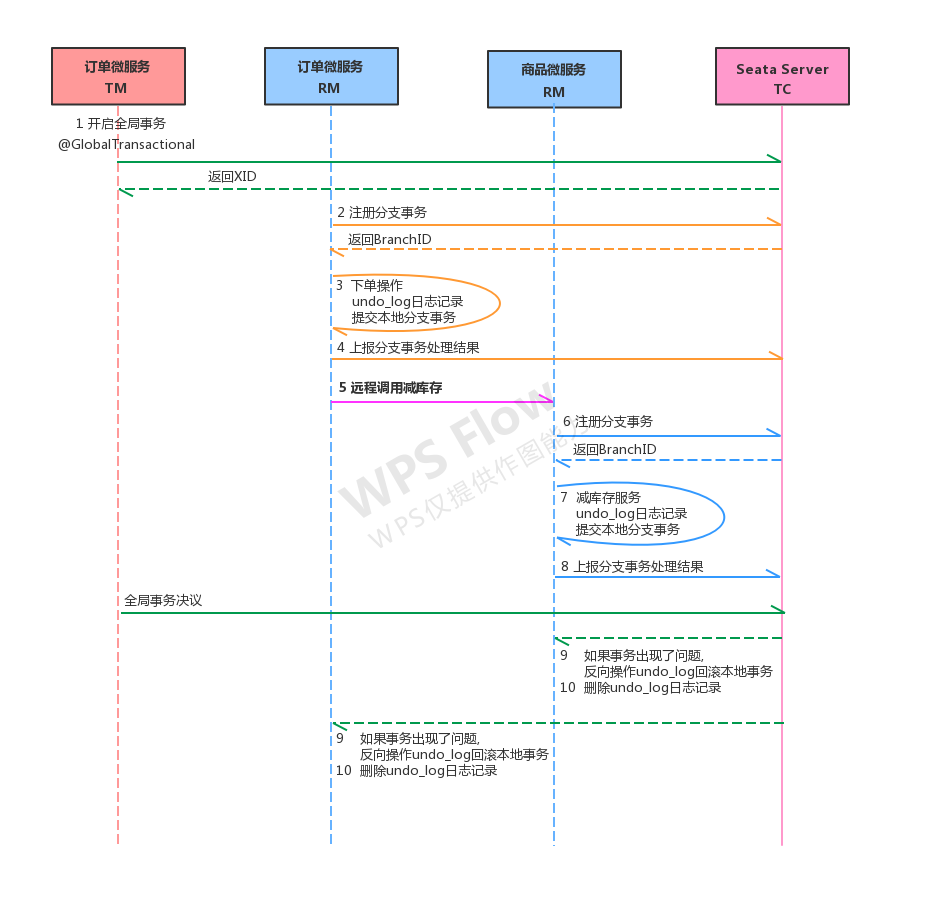
每个RM使用DataSourceProxy连接数据库,其目的是使用ConnectionProxy,使用数据源和数据连接代理的目的就是在第一阶段将undo_log和业务数据放在一个本地事务提交,这样就保存了只要有业务操作就一定有undo_log。
在第一阶段undo_log中存放了数据修改前和修改后的值,为事务回滚作好准备,所以第一阶段完成就已经将分支事务提交,也就释放了锁资源。
TM开启全局事务开始,将XID全局事务id放在事务上下文中,通过feign调用也将XID传入下游分支事务,每个分支事务将自己的Branch ID分支事务ID与XID关联。
第二阶段全局事务提交,TC会通知各各分支参与者提交分支事务,在第一阶段就已经提交了分支事务,这里各各参与者只需要删除undo_log即可,并且可以异步执行,第二阶段很快可以完成。
第二阶段全局事务回滚,TC会通知各各分支参与者回滚分支事务,通过 XID 和 Branch ID 找到相应的回滚日志,通过回滚日志生成反向的 SQL 并执行,以完成分支事务回滚到之前的状态,如果回滚失败则会重试回滚操作
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:
https://blog.csdn.net/python8989/article/details/113666402
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 