
C++并发编程(C++11到C++17)


为什么要并发编程
并发与并行
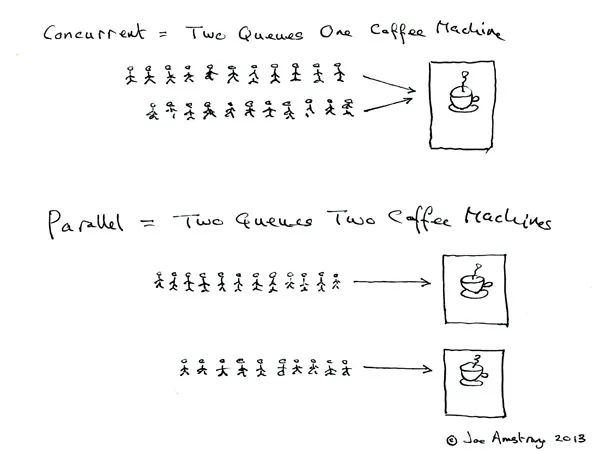
并发:如果多个队列可以交替使用某台咖啡机,则这一行为就是并发的。 并行:如果存在多台咖啡机可以被多个队列交替使用,则就是并行。
进程与线程
进程(英语:process),是指计算机中已运行的程序。进程为曾经是分时系统的基本运作单位。在面向进程设计的系统(如早期的UNIX,Linux 2.4及更早的版本)中,进程是程序的基本执行实体; 线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 -- 维基百科


并发系统的性能
C++与并发编程
相较而言,Java自JDK 1.0就包含了多线程模型。
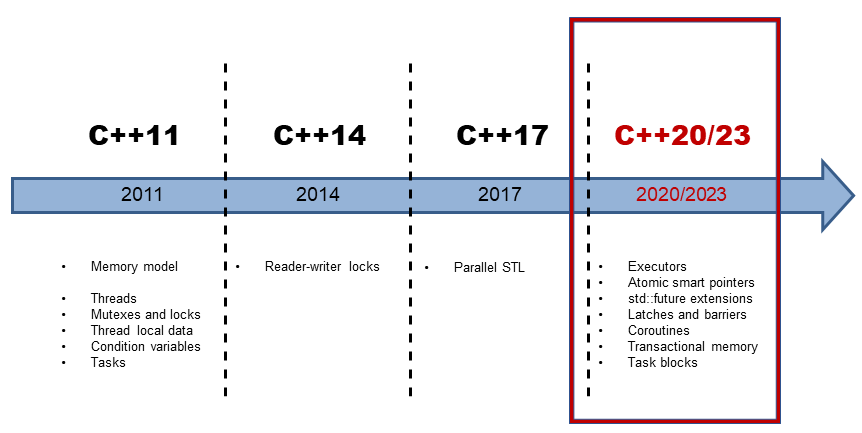
编译器与C++标准
GCC对于C++特性的支持请参见这里:C++ Standards Support in GCC。 Clang对于C++特性的支持请参见这里:C++ Support in Clang。
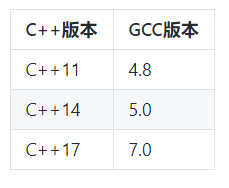
C++标准与相应的GCC版本要求如下:
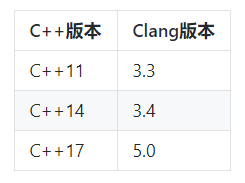
C++标准与相应的Clang版本要求如下:
g++ -std=c++17 your_file.cpp -o your_program
测试环境
git clone https://github.com/paulQuei/cpp-concurrency.git
具体编译器对于C++特性支持的情况请参见这里:C++ compiler support。
./make_all.sh
MacOS
rew install gccbrew insbtall tbbexport tbb_path=/usr/local/Cellar/tbb/2019_U8/./make_all.sh
brew upgrade gcc
Ubuntu
sudo add-apt-repository ppa:ubuntu-toolchain-r/testsudo apt-get updatesudo apt install gcc-9 g++-9
libtbb2_2019~U8-1_amd64.deb libtbb-dev_2019~U8-1_amd64.deb
sudo apt install ~/Downloads/libtbb2_2019~U8-1_amd64.debsudo apt install ~/Downloads/libtbb-dev_2019~U8-1_amd64.deb
线程
创建线程
// 01_hello_thread.cpp#include <iostream>#include <thread> // ①using namespace std; // ②void hello() { // ③cout << "Hello World from new thread." << endl;}int main() {thread t(hello); // ④t.join(); // ⑤return 0;}
为了使用多线程的接口,我们需要#include <thread>头文件。 为了简化声明,本文中的代码都将using namespace std;。 新建线程的入口是一个普通的函数,它并没有什么特别的地方。 创建线程的方式就是构造一个thread对象,并指定入口函数。与普通对象不一样的是,此时编译器便会为我们创建一个新的操作系统线程,并在新的线程中执行我们的入口函数。 关于join函数在下文中讲解。
// 02_lambda_thread.cpp#include <iostream>#include <thread>using namespace std;int main() {thread t([] {cout << "Hello World from lambda thread." << endl;});t.join();return 0;}
为了减少不必要的重复,若无必要,下文中的代码将不贴出include指令以及using声明。
// 03_thread_argument.cppvoid hello(string name) {cout << "Welcome to " << name << endl;}int main() {thread t(hello, "https://paul.pub");t.join();return 0;}
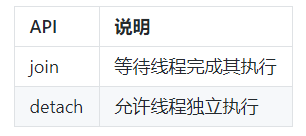
join与detach
主要API
请思考在上面的代码示例中,thread对象在何时会销毁。
join:调用此接口时,当前线程会一直阻塞,直到目标线程执行完成(当然,很可能目标线程在此处调用之前就已经执行完成了,不过这不要紧)。因此,如果目标线程的任务非常耗时,你就要考虑好是否需要在主线程上等待它了,因此这很可能会导致主线程卡住。 detach:detach是让目标线程成为守护线程(daemon threads)。一旦detach之后,目标线程将独立执行,即便其对应的thread对象销毁也不影响线程的执行。并且,你无法再与之通信。
管理当前线程
主要API
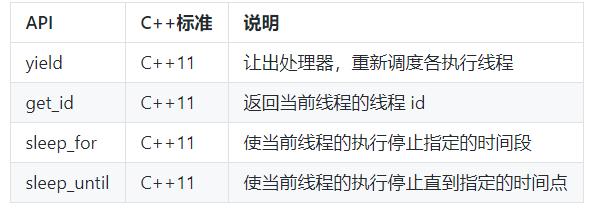
yield 通常用在自己的主要任务已经完成的时候,此时希望让出处理器给其他任务使用。 get_id 返回当前线程的id,可以以此来标识不同的线程。 sleep_for 是让当前线程停止一段时间。 sleep_until 和sleep_for类似,但是是以具体的时间点为参数。这两个API都以chrono API(由于篇幅所限,这里不展开这方面内容)为基础。
// 04_thread_self_manage.cppvoid print_time() {auto now = chrono::system_clock::now();auto in_time_t = chrono::system_clock::to_time_t(now);std::stringstream ss;ss << put_time(localtime(&in_time_t), "%Y-%m-%d %X");cout << "now is: " << ss.str() << endl;}void sleep_thread() {this_thread::sleep_for(chrono::seconds(3));cout << "[thread-" << this_thread::get_id() << "] is waking up" << endl;}void loop_thread() {for (int i = 0; i < 10; i++) {cout << "[thread-" << this_thread::get_id() << "] print: " << i << endl;}}int main() {print_time();thread t1(sleep_thread);thread t2(loop_thread);t1.join();t2.detach();print_time();return 0;}
now is: 2019-10-13 10:17:48[thread-0x70000cdda000] print: 0[thread-0x70000cdda000] print: 1[thread-0x70000cdda000] print: 2[thread-0x70000cdda000] print: 3[thread-0x70000cdda000] print: 4[thread-0x70000cdda000] print: 5[thread-0x70000cdda000] print: 6[thread-0x70000cdda000] print: 7[thread-0x70000cdda000] print: 8[thread-0x70000cdda000] print: 9[thread-0x70000cd57000] is waking upnow is: 2019-10-13 10:17:51
一次调用
主要API
// 05_call_once.cppvoid init() {cout << "Initialing..." << endl;// Do something...}void worker(once_flag* flag) {call_once(*flag, init);}int main() {once_flag flag;thread t1(worker, &flag);thread t2(worker, &flag);thread t3(worker, &flag);t1.join();t2.join();t3.join();return 0;}
请思考一下,为什么要在main函数中创建once_flag flag。如果是在worker函数中直接声明一个once_flag并使用行不行?为什么?
并发任务
// 06_naive_multithread.cppstatic const int MAX = 10e8; // ①static double sum = 0; // ②void worker(int min, int max) { // ③for (int i = min; i <= max; i++) {sum += sqrt(i);}}void serial_task(int min, int max) { // ④auto start_time = chrono::steady_clock::now();sum = 0;worker(0, MAX);auto end_time = chrono::steady_clock::now();auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();cout << "Serail task finish, " << ms << " ms consumed, Result: " << sum << endl;}
通过一个常量指定数据范围,这个是为了方便调整。 通过一个全局变量来存储结果。 通过一个任务函数来计算值。 统计任务的执行时间。
Serail task finish, 6406 ms consumed, Result: 2.10819e+13
// 06_naive_multithread.cppvoid concurrent_task(int min, int max) {auto start_time = chrono::steady_clock::now();unsigned concurrent_count = thread::hardware_concurrency(); // ①cout << "hardware_concurrency: " << concurrent_count << endl;vector<thread> threads;min = 0;sum = 0;for (int t = 0; t < concurrent_count; t++) { // ②int range = max / concurrent_count * (t + 1);threads.push_back(thread(worker, min, range)); // ③min = range + 1;}for (auto& t : threads) {t.join(); // ④}auto end_time = chrono::steady_clock::now();auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << sum << endl;}
thread::hardware_concurrency()可以获取到当前硬件支持多少个线程并行执行。 根据处理器的情况决定线程的数量。 对于每一个线程都通过worker函数来完成任务,并划分一部分数据给它处理。 等待每一个线程执行结束。
hardware_concurrency: 16Concurrent task finish, 6246 ms consumed, Result: 1.78162e+12
事实上,目前大部分CPU的缓存已经不只一层。
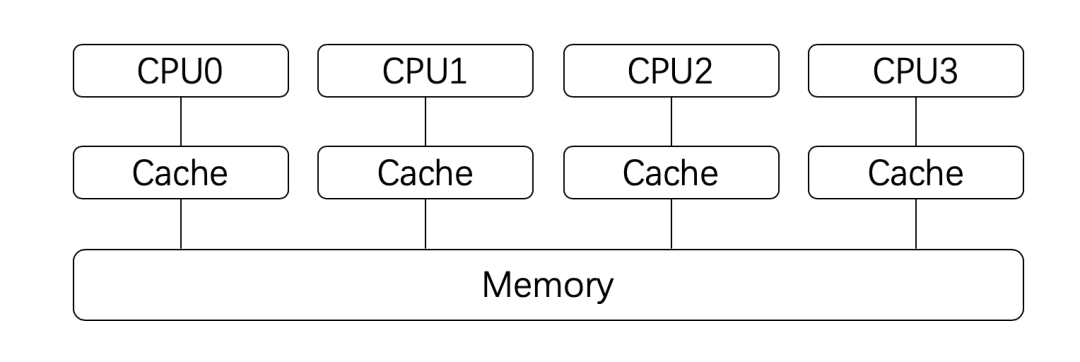
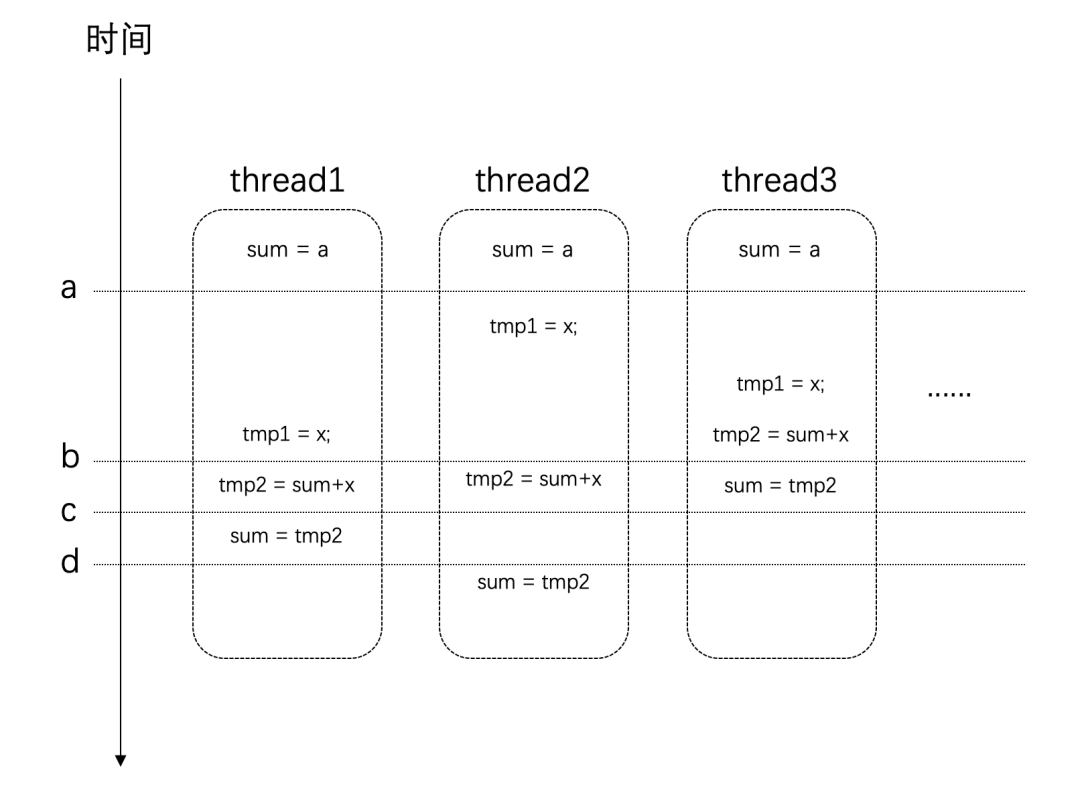
竞争条件与临界区
互斥体与锁
mutex
独立的对于划分给自己的数据的处理 对于处理结果的汇总
主要API
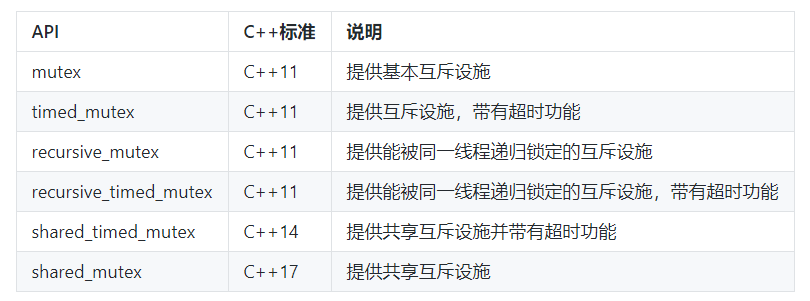
| lock|锁定互斥体,如果不可用,则阻塞 |
| try_lock |尝试锁定互斥体,如果不可用,直接返回 |
|unlock | 解锁互斥体|
超时: timed_mutex, recursive_timed_mutex, shared_timed_mutex 名称都带有timed,这意味着它们都支持超时功能。它们都提供了try_lock_for和try_lock_until方法,这两个方法分别可以指定超时的时间长度和时间点。如果在超时的时间范围内没有能获取到锁,则直接返回,不再继续等待。 可重入: recursive_mutex和recursive_timed_mutex的名称都带有recursive。可重入或者叫做可递归,是指在同一个线程中,同一把锁可以锁定多次。这就避免了一些不必要的死锁。 共享: shared_timed_mutex和shared_mutex提供了共享功能。对于这类互斥体,实际上是提供了两把锁:一把是共享锁,一把是互斥锁。一旦某个线程获取了互斥锁,任何其他线程都无法再获取互斥锁和共享锁;但是如果有某个线程获取到了共享锁,其他线程无法再获取到互斥锁,但是还有获取到共享锁。这里互斥锁的使用和其他的互斥体接口和功能一样。而共享锁可以同时被多个线程同时获取到(使用共享锁的接口见下面的表格)。共享锁通常用在读者写者模型上。
|lock_shared | 获取互斥体的共享锁,如果无法获取则阻塞 |
| try_lock_shared| 尝试获取共享锁,如果不可用,直接返回 |
| unlock_shared| 解锁共享锁 |
// 07_mutex_lock.cppstatic const int MAX = 10e8;static double sum = 0;static mutex exclusive;void concurrent_worker(int min, int max) {for (int i = min; i <= max; i++) {exclusive.lock(); // ①sum += sqrt(i);exclusive.unlock(); // ②}}void concurrent_task(int min, int max) {auto start_time = chrono::steady_clock::now();unsigned concurrent_count = thread::hardware_concurrency();cout << "hardware_concurrency: " << concurrent_count << endl;vector<thread> threads;min = 0;sum = 0;for (int t = 0; t < concurrent_count; t++) {int range = max / concurrent_count * (t + 1);threads.push_back(thread(concurrent_worker, min, range)); // ③min = range + 1;}for (int i = 0; i < threads.size(); i++) {threads[i].join();}auto end_time = chrono::steady_clock::now();auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << sum << endl;}
在访问共享数据之前加锁 访问完成之后解锁 在多线程中使用带锁的版本
hardware_concurrency: 16Concurrent task finish, 74232 ms consumed, Result: 2.10819e+13
// 08_improved_mutex_lock.cppvoid concurrent_worker(int min, int max) {double tmp_sum = 0;for (int i = min; i <= max; i++) {tmp_sum += sqrt(i); // ①}exclusive.lock(); // ②sum += tmp_sum;exclusive.unlock();}
通过一个局部变量保存当前线程的处理结果 在汇总总结过的时候进行锁保护
hardware_concurrency: 16Concurrent task finish, 451 ms consumed, Result: 2.10819e+13
In general, a lock should be held for only the minimum possible time needed to perform the required operations. --《C++ Concurrency in Action》
死锁

// 09_deadlock_bank_transfer.cppclass Account {public:Account(string name, double money): mName(name), mMoney(money) {};public:void changeMoney(double amount) {mMoney += amount;}string getName() {return mName;}double getMoney() {return mMoney;}mutex* getLock() {return &mMoneyLock;}private:string mName;double mMoney;mutex mMoneyLock;};
// 09_deadlock_bank_transfer.cppclass Bank {public:void addAccount(Account* account) {mAccounts.insert(account);}bool transferMoney(Account* accountA, Account* accountB, double amount) {lock_guard guardA(*accountA->getLock()); // ①lock_guard guardB(*accountB->getLock());if (amount > accountA->getMoney()) { // ②return false;}accountA->changeMoney(-amount); // ③accountB->changeMoney(amount);return true;}double totalMoney() const {double sum = 0;for (auto a : mAccounts) {sum += a->getMoney();}return sum;}private:set<Account*> mAccounts;};
为了保证线程安全,在修改每个账号之前,需要获取相应的锁。 判断转出账户金额是否足够,如果不够此次转账失败。 进行转账。
// 09_deadlock_bank_transfer.cppvoid randomTransfer(Bank* bank, Account* accountA, Account* accountB) {while(true) {double randomMoney = ((double)rand() / RAND_MAX) * 100;if (bank->transferMoney(accountA, accountB, randomMoney)) {cout << "Transfer " << randomMoney << " from " << accountA->getName()<< " to " << accountB->getName()<< ", Bank totalMoney: " << bank->totalMoney() << endl;} else {cout << "Transfer failed, "<< accountA->getName() << " has only $" << accountA->getMoney() << ", but "<< randomMoney << " required" << endl;}}}
// 09_deadlock_bank_transfer.cppint main() {Account a("Paul", 100);Account b("Moira", 100);Bank aBank;aBank.addAccount(&a);aBank.addAccount(&b);thread t1(randomTransfer, &aBank, &a, &b);thread t2(randomTransfer, &aBank, &b, &a);t1.join();t2.join();return 0;}
...Transfer 13.2901 from Paul to Moira, Bank totalMoney: 20042.6259 from Moira to Paul, Bank totalMoney: 200Transfer failed, Moira has only $34.7581, but 66.3208 requiredTransfer failed, Moira has only $34.7581, butTransfer 93.191 from 53.9176 requiredTransfer 60.6146 from Moira to Paul, Bank totalMoney: 200Transfer 49.7304 from Moira to Paul, Bank totalMoney: 200Paul to Moira, Bank totalMoney:Transfer failed, Moira has only $17.6041, but 18.1186 requiredTransfer failed, Moira has only $17.6041, but 18.893 requiredTransfer failed, Moira has only $17.6041, but 34.7078 requiredTransfer failed, Moira has only $17.6041, but 33.9569 requiredTransfer 12.7899 from 200Moira to Paul, Bank totalMoney: 200Transfer failed, Moira has only $63.9373, but 80.9038 requiredTransfer 50.933 from Moira to Paul, Bank totalMoney: 200Transfer failed, Moira has only $13.0043, but 30.2056 requiredTransfer failed, Moira has only $Transfer 59.123 from Paul to Moira, Bank totalMoney: 200Transfer 29.0486 from Paul to Moira, Bank totalMoney: 20013.0043, but 64.7307 required
// 10_improved_bank_transfer.cppmutex sCoutLock;void randomTransfer(Bank* bank, Account* accountA, Account* accountB) {while(true) {double randomMoney = ((double)rand() / RAND_MAX) * 100;if (bank->transferMoney(accountA, accountB, randomMoney)) {sCoutLock.lock();cout << "Transfer " << randomMoney << " from " << accountA->getName()<< " to " << accountB->getName()<< ", Bank totalMoney: " << bank->totalMoney() << endl;sCoutLock.unlock();} else {sCoutLock.lock();cout << "Transfer failed, "<< accountA->getName() << " has only " << accountA->getMoney() << ", but "<< randomMoney << " required" << endl;sCoutLock.unlock();}}}
请思考一下两处lock和unlock调用,并考虑为什么不在while(true)下面写一次整体的加锁和解锁。
通用锁定算法
主要API
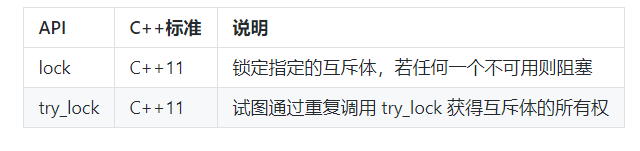
// 10_improved_bank_transfer.cppbool transferMoney(Account* accountA, Account* accountB, double amount) {lock(*accountA->getLock(), *accountB->getLock()); // ①lock_guard lockA(*accountA->getLock(), adopt_lock); // ②lock_guard lockB(*accountB->getLock(), adopt_lock); // ③if (amount > accountA->getMoney()) {return false;}accountA->changeMoney(-amount);accountB->changeMoney(amount);return true;}
这里通过lock函数来获取两把锁,标准库的实现会保证不会发生死锁。 lock_guard在下面我们还会详细介绍。这里只要知道它会在自身对象生命周期的范围内锁定互斥体即可。创建lock_guard的目的是为了在transferMoney结束的时候释放锁,lockB也是一样。但需要注意的是,这里传递了 adopt_lock表示:现在是已经获取到互斥体了的状态了,不用再次加锁(如果不加adopt_lock就是二次锁定了)。
...Transfer failed, Paul has only $1.76243, but 17.5974 requiredTransfer failed, Paul has only $1.76243, but 59.2104 requiredTransfer failed, Paul has only $1.76243, but 49.6379 requiredTransfer failed, Paul has only $1.76243, but 63.6373 requiredTransfer failed, Paul has only $1.76243, but 51.8742 requiredTransfer failed, Paul has only $1.76243, but 50.0081 requiredTransfer failed, Paul has only $1.76243, but 86.1041 requiredTransfer failed, Paul has only $1.76243, but 51.3278 requiredTransfer failed, Paul has only $1.76243, but 66.5754 requiredTransfer failed, Paul has only $1.76243, but 32.1867 requiredTransfer failed, Paul has only $1.76243, but 62.0039 requiredTransfer failed, Paul has only $1.76243, but 98.7819 requiredTransfer failed, Paul has only $1.76243, but 27.046 requiredTransfer failed, Paul has only $1.76243, but 62.9155 requiredTransfer 98.8478 from Moira to Paul, Bank totalMoney: 200Transfer 80.0722 from Moira to Paul, Bank totalMoney: 200Transfer 73.7035 from Moira to Paul, Bank totalMoney: 200Transfer 34.4476 from Moira to Paul, Bank totalMoney: 200Transfer failed, Moira has only $10.0142, but 61.3033 requiredTransfer failed, Moira has only $10.0142, but 24.5595 required...
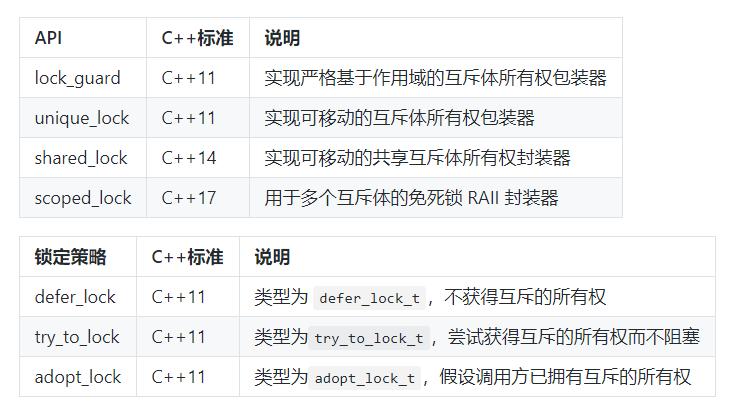
通用互斥管理
主要API
// https://en.cppreference.com/w/cpp/thread/lock_guardint g_i = 0;std::mutex g_i_mutex; // ①void safe_increment(){std::lock_guard<std::mutex> lock(g_i_mutex); // ②++g_i;std::cout << std::this_thread::get_id() << ": " << g_i << '\n';// ③}int main(){std::cout << "main: " << g_i << '\n';std::thread t1(safe_increment); // ④std::thread t2(safe_increment);t1.join();t2.join();std::cout << "main: " << g_i << '\n';}
全局的互斥体g_i_mutex用来保护全局变量g_i 这是一个设计为可以被多线程环境使用的方法。因此需要通过互斥体来进行保护。这里没有调用lock方法,而是直接使用lock_guard来锁定互斥体。 在方法结束的时候,局部变量std::lock_guard<std::mutex> lock会被销毁,它对互斥体的锁定也就解除了。 在多个线程中使用这个方法。
RAII
RAII保证资源可用于任何会访问该对象的函数。它亦保证所有资源在其控制对象的生存期结束时,以获取顺序的逆序释放。类似地,若资源获取失败(构造函数以异常退出),则为已构造完成的对象和基类子对象所获取的所有资源,会以初始化顺序的逆序释放。这有效地利用了语言特性以消除内存泄漏并保证异常安全。
将每个资源封装入一个类,其中: 构造函数请求资源,并建立所有类不变式,或在它无法完成时抛出异常, 析构函数释放资源并决不抛出异常; 始终经由 RAII 类的实例使用满足要求的资源,该资源 自身拥有自动存储期或临时生存期,或 具有与自动或临时对象的生存期绑定的生存期
lock(*accountA->getLock(), *accountB->getLock());lock_guard lockA(*accountA->getLock(), adopt_lock);lock_guard lockB(*accountB->getLock(), adopt_lock);
unique_lock lockA(*accountA->getLock(), defer_lock);unique_lock lockB(*accountB->getLock(), defer_lock);lock(*accountA->getLock(), *accountB->getLock());
scoped_lock lockAll(*accountA->getLock(), *accountB->getLock());
条件变量
| condition_variable | C++ 11 | 提供与 std::unique_lock 关联的条件变量 |
| condition_variable_any | C++ 11 |提供与任何锁类型关联的条件变量 |
| notify_all_at_thread_exit |C++ 11 | 安排到在此线程完全结束时对 notify_all 的调用 |
| cv_status | C++ 11 |列出条件变量上定时等待的可能结果 |
生产者和消费者共享一个工作区。这个区间的大小是有限的。 生产者总是产生数据放入工作区中,当工作区满了。它就停下来等消费者消费一部分数据,然后继续工作。 消费者总是从工作区中拿出数据使用。当工作区中的数据全部被消费空了之后,它也会停下来等待生产者往工作区中放入新的数据。
// 11_bank_transfer_wait_notify.cppclass Account {public:Account(string name, double money): mName(name), mMoney(money) {};public:void changeMoney(double amount) {unique_lock lock(mMoneyLock); // ②mConditionVar.wait(lock, [this, amount] { // ③return mMoney + amount > 0; // ④});mMoney += amount;mConditionVar.notify_all(); // ⑤}string getName() {return mName;}double getMoney() {return mMoney;}private:string mName;double mMoney;mutex mMoneyLock;condition_variable mConditionVar; // ①};
这里声明了一个条件变量,用来在多个线程之间协作。 这里使用的是unique_lock,这是为了与条件变量相配合。因为条件变量会解锁和重新锁定互斥体。 这里是比较重要的一个地方:通过条件变量进行等待。此时:会通过后面的lambda表达式判断条件是否满足。如果满足则继续;如果不满足,则此处会解锁互斥体,并让当前线程等待。解锁这一点非常重要,因为只有这样,才能让其他线程获取互斥体。 这里是条件变量等待的条件。如果你不熟悉lambda表达式,请自行网上学习,或者阅读我之前写的文章。 此处也很重要。当金额发生变动之后,我们需要通知所有在条件变量上等待的其他线程。此时所有调用wait线程都会再次唤醒,然后尝试获取锁(当然,只有一个能获取到)并再次判断条件是否满足。除了notify_all还有notify_one,它只通知一个等待的线程。wait和notify就构成了线程间互相协作的工具。
// 11_bank_transfer_wait_notify.cppvoid Bank::transferMoney(Account* accountA, Account* accountB, double amount) {accountA->changeMoney(-amount);accountB->changeMoney(amount);}
// 11_bank_transfer_wait_notify.cppmutex sCoutLock;void randomTransfer(Bank* bank, Account* accountA, Account* accountB) {while(true) {double randomMoney = ((double)rand() / RAND_MAX) * 100;{lock_guard guard(sCoutLock);cout << "Try to Transfer " << randomMoney<< " from " << accountA->getName() << "(" << accountA->getMoney()<< ") to " << accountB->getName() << "(" << accountB->getMoney()<< "), Bank totalMoney: " << bank->totalMoney() << endl;}bank->transferMoney(accountA, accountB, randomMoney);}}
...Try to Transfer 13.72 from Moira(10.9287) to Paul(189.071), Bank totalMoney: 200Try to Transfer 28.6579 from Paul(189.071) to Moira(10.9287), Bank totalMoney: 200Try to Transfer 91.8049 from Paul(160.413) to Moira(39.5866), Bank totalMoney: 200Try to Transfer 5.56383 from Paul(82.3285) to Moira(117.672), Bank totalMoney: 200Try to Transfer 11.3594 from Paul(76.7646) to Moira(123.235), Bank totalMoney: 200Try to Transfer 16.9557 from Paul(65.4053) to Moira(134.595), Bank totalMoney: 200Try to Transfer 74.998 from Paul(48.4495) to Moira(151.55), Bank totalMoney: 200Try to Transfer 65.3005 from Moira(151.55) to Paul(48.4495), Bank totalMoney: 200Try to Transfer 90.6084 from Moira(86.25) to Paul(113.75), Bank totalMoney: 125.002Try to Transfer 99.6425 from Moira(70.6395) to Paul(129.36), Bank totalMoney: 200Try to Transfer 55.2091 from Paul(129.36) to Moira(70.6395), Bank totalMoney: 200Try to Transfer 92.259 from Paul(74.1513) to Moira(125.849), Bank totalMoney: 200...
future
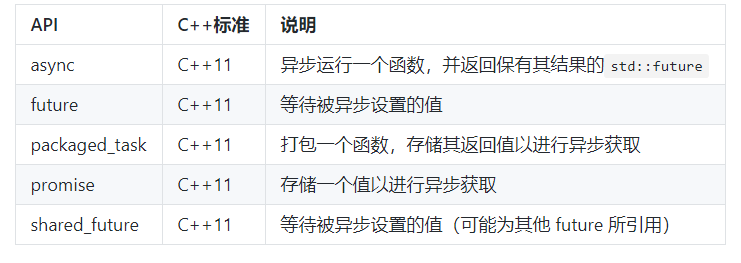
async
// 12_async_task.cppstatic const int MAX = 10e8;static double sum = 0;void worker(int min, int max) {for (int i = min; i <= max; i++) {sum += sqrt(i);}}int main() {sum = 0;auto f1 = async(worker, 0, MAX);cout << "Async task triggered" << endl;f1.wait();cout << "Async task finish, result: " << sum << endl << endl;}
这里以异步的方式启动了任务。它会返回一个future对象。future用来存储异步任务的执行结果,关于future我们在后面packaged_task的例子中再详细说明。在这个例子中我们仅仅用它来等待任务执行完成。 此处是等待异步任务执行完成。
async:运行新线程,以异步执行任务。 deferred:调用方线程上第一次请求其结果时才执行任务,即惰性求值。
// 12_async_task.cppint main() {double result = 0;cout << "Async task with lambda triggered, thread: " << this_thread::get_id() << endl;auto f2 = async(launch::async, [&result]() {cout << "Lambda task in thread: " << this_thread::get_id() << endl;for (int i = 0; i <= MAX; i++) {result += sqrt(i);}});f2.wait();cout << "Async task with lambda finish, result: " << result << endl << endl;return 0;}
Async task with lambda triggered, thread: 0x11290d5c0Lambda task in thread: 0x700007aa1000Async task with lambda finish, result: 2.10819e+13
// 12_async_task.cppclass Worker {public:Worker(int min, int max): mMin(min), mMax(max) {} // ①double work() { // ②mResult = 0;for (int i = mMin; i <= mMax; i++) {mResult += sqrt(i);}return mResult;}double getResult() {return mResult;}private:int mMin;int mMax;double mResult;};int main() {Worker w(0, MAX);cout << "Task in class triggered" << endl;auto f3 = async(&Worker::work, &w); // ③f3.wait();cout << "Task in class finish, result: " << w.getResult() << endl << endl;return 0;}
这里通过一个类来描述任务。这个类是对前面提到的任务的封装。它包含了任务的输入参数,和输出结果。 work函数是任务的主体逻辑。 通过async执行任务:这里指定了具体的任务函数以及相应的对象。请注意这里是&w,因此传递的是对象的指针。如果不写&将传入w对象的临时复制。
packaged_task
如果你了解设计模式,你应该会知道命令模式。
// 13_packaged_task.cppdouble concurrent_worker(int min, int max) {double sum = 0;for (int i = min; i <= max; i++) {sum += sqrt(i);}return sum;}double concurrent_task(int min, int max) {vector<future<double>> results; // ①unsigned concurrent_count = thread::hardware_concurrency();min = 0;for (int i = 0; i < concurrent_count; i++) { // ②packaged_task<double(int, int)> task(concurrent_worker); // ③results.push_back(task.get_future()); // ④int range = max / concurrent_count * (i + 1);thread t(std::move(task), min, range); // ⑤t.detach();min = range + 1;}cout << "threads create finish" << endl;double sum = 0;for (auto& r : results) {sum += r.get(); ⑥}return sum;}int main() {auto start_time = chrono::steady_clock::now();double r = concurrent_task(0, MAX);auto end_time = chrono::steady_clock::now();auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << r << endl;return 0;}
首先创建一个集合来存储future对象。我们将用它来获取任务的结果。 同样的,根据CPU的情况来创建线程的数量。 将任务包装成packaged_task。请注意,由于concurrent_worker被包装成了任务,我们无法直接获取它的return值。而是要通过future对象来获取。 获取任务关联的future对象,并将其存入集合中。 通过一个新的线程来执行任务,并传入需要的参数。 通过future集合,逐个获取每个任务的计算结果,将其累加。这里r.get()获取到的就是每个任务中concurrent_worker的返回值。

promise与future
// 14_promise_future.cppdouble concurrent_worker(int min, int max) {double sum = 0;for (int i = min; i <= max; i++) {sum += sqrt(i);}return sum;}void concurrent_task(int min, int max, promise<double>* result) { // ①vector<future<double>> results;unsigned concurrent_count = thread::hardware_concurrency();min = 0;for (int i = 0; i < concurrent_count; i++) {packaged_task<double(int, int)> task(concurrent_worker);results.push_back(task.get_future());int range = max / concurrent_count * (i + 1);thread t(std::move(task), min, range);t.detach();min = range + 1;}cout << "threads create finish" << endl;double sum = 0;for (auto& r : results) {sum += r.get();}result->set_value(sum); // ②cout << "concurrent_task finish" << endl;}int main() {auto start_time = chrono::steady_clock::now();promise<double> sum; // ③concurrent_task(0, MAX, &sum);auto end_time = chrono::steady_clock::now();auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();cout << "Concurrent task finish, " << ms << " ms consumed." << endl;cout << "Result: " << sum.get_future().get() << endl; // ④return 0;}
concurrent_task不再直接返回计算结果,而是增加了一个promise对象来存放结果。 在任务计算完成之后,将总结过设置到promise对象上。一旦这里调用了set_value,其相关联的future对象就会就绪。 这里是在main中创建一个promoise来存放结果,并以指针的形式传递进concurrent_task中。 通过sum.get_future().get()来获取结果。第2点中已经说了:一旦调用了set_value,其相关联的future对象就会就绪。

// 15_parallel_algorithm.cppvoid generateRandomData(vector<double>& collection, int size) {random_device rd;mt19937 mt(rd());uniform_real_distribution<double> dist(1.0, 100.0);for (int i = 0; i < size; i++) {collection.push_back(dist(mt));}}int main() {vector<double> collection;generateRandomData(collection, 10e6); // ①vector<double> copy1(collection); // ②vector<double> copy2(collection);vector<double> copy3(collection);auto time1 = chrono::steady_clock::now(); // ③sort(execution::seq, copy1.begin(), copy1.end()); // ④auto time2 = chrono::steady_clock::now();auto duration = chrono::duration_cast<chrono::milliseconds>(time2 - time1).count();cout << "Sequenced sort consuming " << duration << "ms." << endl; // ⑤auto time3 = chrono::steady_clock::now();sort(execution::par, copy2.begin(),copy2.end()); // ⑥auto time4 = chrono::steady_clock::now();duration = chrono::duration_cast<chrono::milliseconds>(time4 - time3).count();cout << "Parallel sort consuming " << duration << "ms." << endl;auto time5 = chrono::steady_clock::now();sort(execution::par_unseq, copy2.begin(),copy2.end()); // ⑦auto time6 = chrono::steady_clock::now();duration = chrono::duration_cast<chrono::milliseconds>(time6 - time5).count();cout << "Parallel unsequenced sort consuming " << duration << "ms." << endl;}
通过一个函数生成1000,000个随机数。
将数据拷贝3份,以备使用。
接下来将通过三个不同的parallel_policy参数来调用同样的sort算法。每次调用记录开始和结束的时间。
第一次调用使用std::execution::seq参数。
输出本次测试所使用的时间。
第二次调用使用std::execution::par参数。
第三次调用使用std::execution::par_unseq参数。
Sequenced sort consuming 4464ms.Parallel sort consuming 459ms.Parallel unsequenced sort consuming 168ms.

关注公众号👇,一起优(niu)秀(bi)!
评论