
文字识别方法全面整理
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来自 | 知乎 作者 | 白裳
链接 | https://zhuanlan.zhihu.com/p/65707543
本文仅供交流,如有侵权,请联系删除。
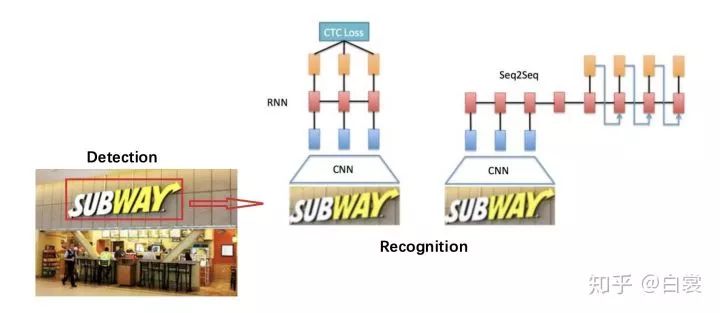

EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/...
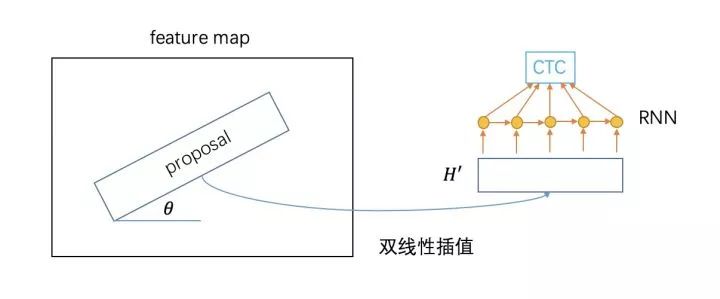
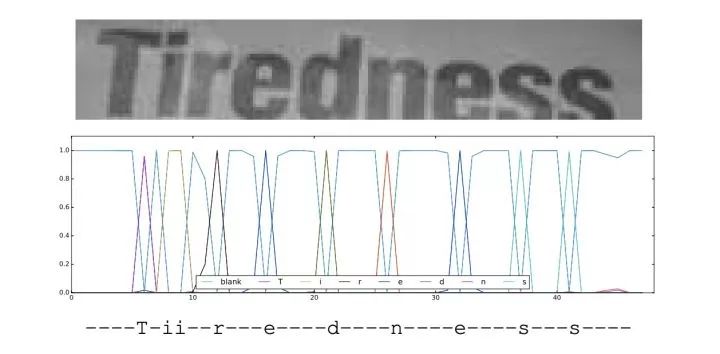
CRNN:CNN+RNN+CTC 一文读懂CRNN+CTC文字识别
https://zhuanlan.zhihu.com/p/43534801
CNN+Seq2Seq+Attention Seq2Seq+Attention原理介绍 https://zhuanlan.zhihu.com/p/51383402 对应OCR代码如下 https://github.com/bai-shang/crnn_seq2seq_ocr_pytorch
Robust Scene Text Recognition with Automatic Rectification. CVPR2016.
arxiv.org/abs/1603.03915
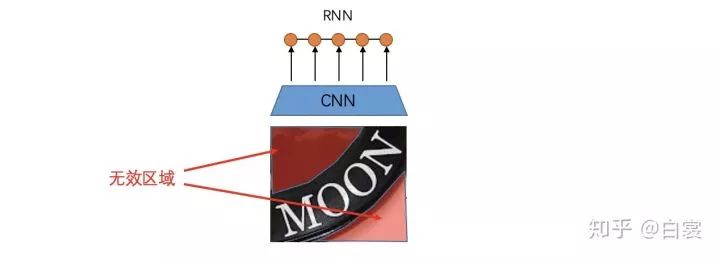
Scene Text Recognition from Two-Dimensional Perspective. AAAI2018.
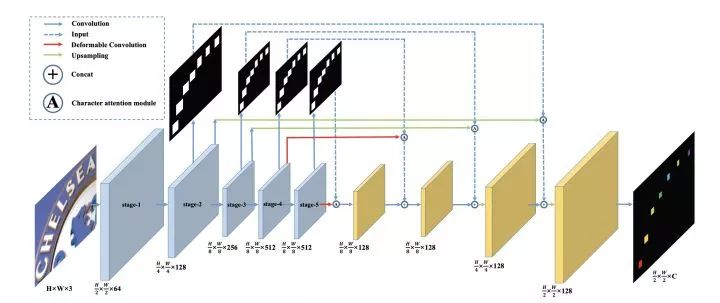


SqueezedText: A Real-time Scene Text Recognition by Binary Convolutional Encoderdecoder Network. AAAI2018.
https://ren-fengbo.lab.asu.edu/sites/default/files/16354-77074-1-pb.pdf
Handwriting Recognition in Low-resource Scripts using Adversarial Learning. CVPR2019.
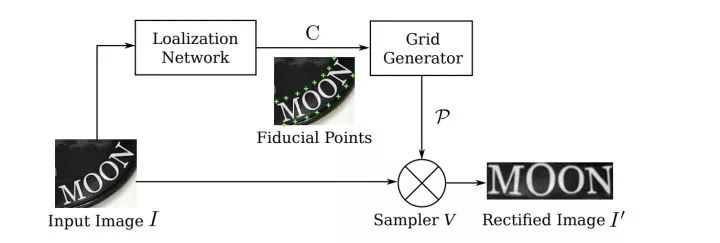
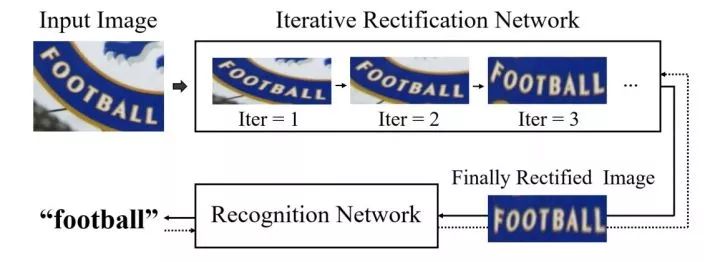
arxiv.org/pdf/1811.01396.pdfESIR: End-to-end Scene Text Recognition via Iterative Image Rectification. CVPR2019.
http:openaccess.thecvf.com/content_CVPR_2019/papers/Zhan_ESIR_End-To-End_Scene_Text_Recognition_via_Iterative_Image_Rectification_CVPR_2019_paper.pdf
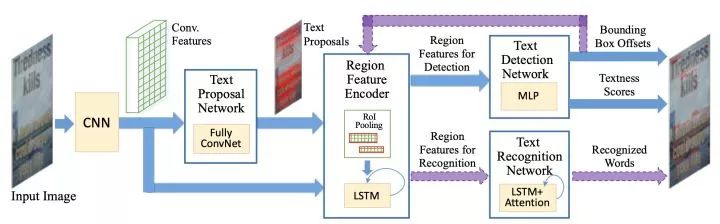
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks. ICCV2017. http:openaccess.thecvf.com/content_ICCV_2017/papers/Li_Towards_End-To-End_Text_ICCV_2017_paper.pdf
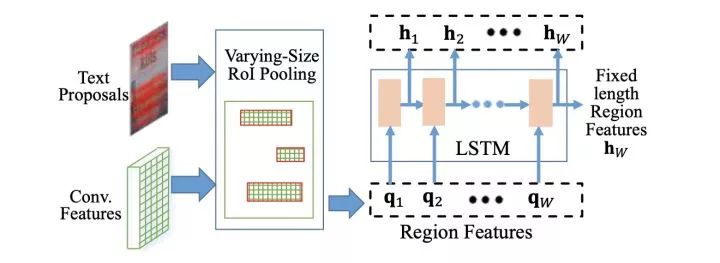

Deep TextSpotter: An End-to-End Trainable Scene Text Localization and Recognition Framework. ICCV2017. http:openaccess.thecvf.com/content_ICCV_2017/papers/Busta_Deep_TextSpotter_An_ICCV_2017_paper.pdf
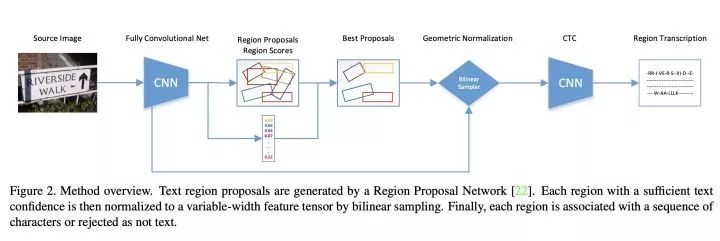
Attention-based Extraction of Structured Information from Street View Imagery. ICDAR2017.
arxiv.org/abs/1704.03549
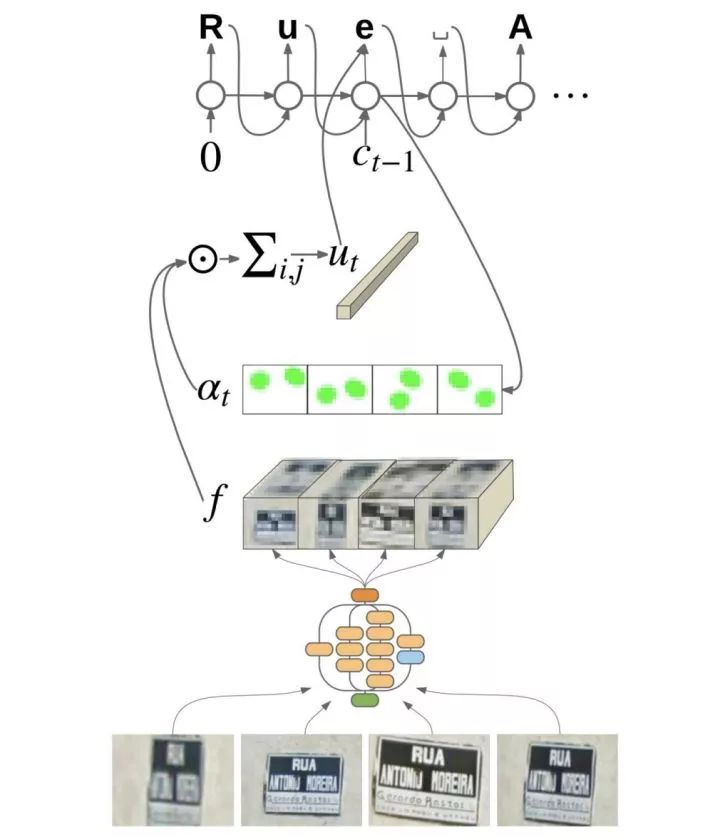
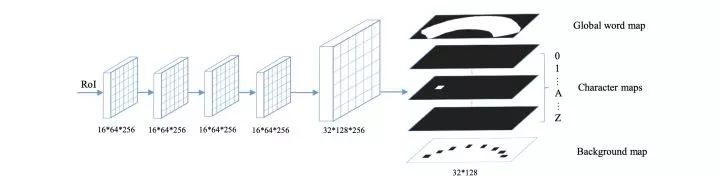
利用CNN提取不同视角的图片的特征,并将特征concat为一个大的特征矩阵 计算图片中文的spatial attention , 越大该区域为文字区域的概率越大 通过 抽取 中文字区域特征 ,并送入后续RNN进行识别
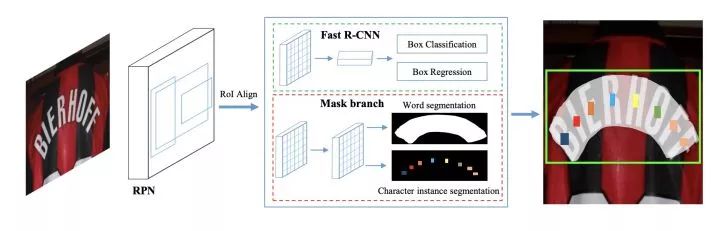
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. ECCV2018.
arxiv.org/abs/1807.02242
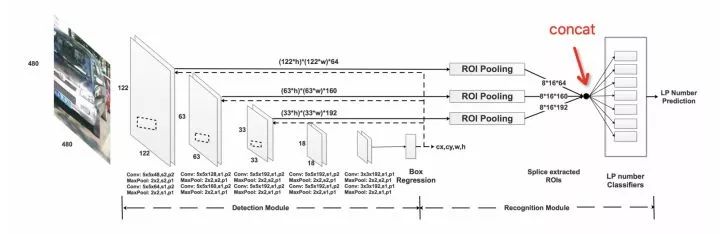
Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline. ECCV2018. http:openaccess.thecvf.com/content_ECCV_2018/papers/Zhenbo_Xu_Towards_End-to-End_License_ECCV_2018_paper.pdf

利用Box Regression layer层预测车牌位置 ; 检测出来 确定位置后,采集对应不同尺度的特征图进行ROI Pooling; 把不同尺度特征拼接在一起,进行识别。
在这里特别感谢一下所有开放数据集的研究人员!数据才是cv第一生产力!
An end-to-end TextSpotter with Explicit Alignment and Attention. CVPR2018. http:openaccess.thecvf.com/content_cvpr_2018/papers/He_An_End-to-End_TextSpotter_CVPR_2018_paper.pdf
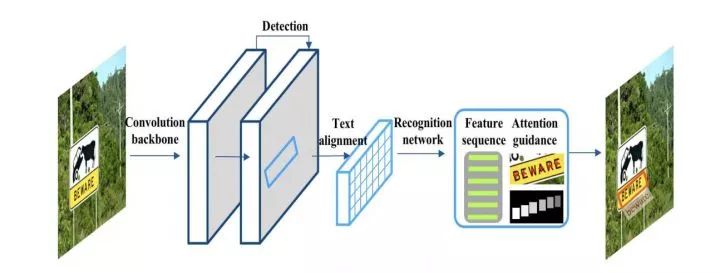
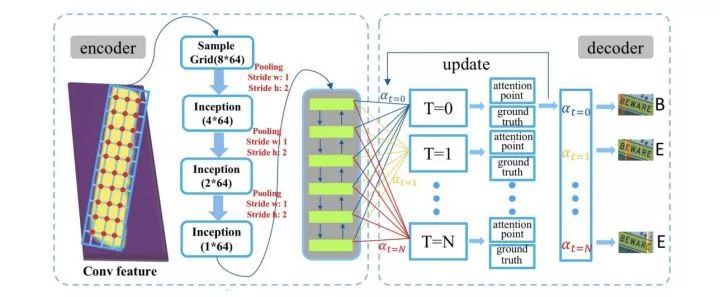

FOTS: Fast Oriented Text Spotting with a Unified Network. CVPR2018. arxiv.org/abs/1801.01671

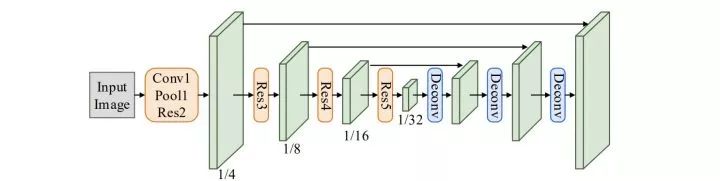

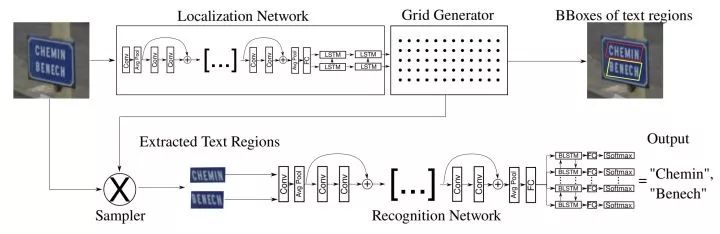
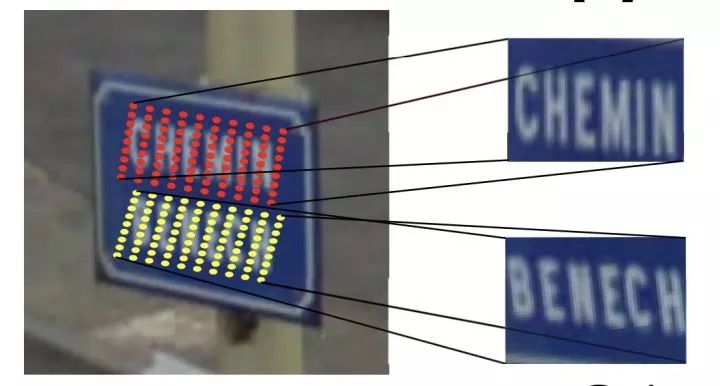
SEE: Towards Semi-Supervised End-to-End Scene Text Recognition. AAAI2018.
arxiv.org/abs/1712.05404
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论