
Semaphore 信号量限流,这东西真管用吗?
点蓝色「小黑十一点半」
👆关注楼下小黑哥😏
Hello,大家好,我是楼下小黑哥~
最近参与公司的服务治理项目,主要目的是为了保证生产服务高可用性,以及高稳定性。
为了更好的参与的这个项目,这段时间一直在充电学习这方面的相关知识,包括限流,熔断,服务降级等等。
那在学习限流的时候,看到网上很多文章中直接使用了JDK 中 Semaphore 实现了限流器。
虽然到达的限流的目的,但是实际上其还是存在很大缺陷。

那你如果没有经过完整测试,直接将这套限流方式照搬过来,发到了生产环境,那就等着背这口大锅吧。
好了,今天我们主要来聊聊 Semaphore ,文章主要内容如下图所示:
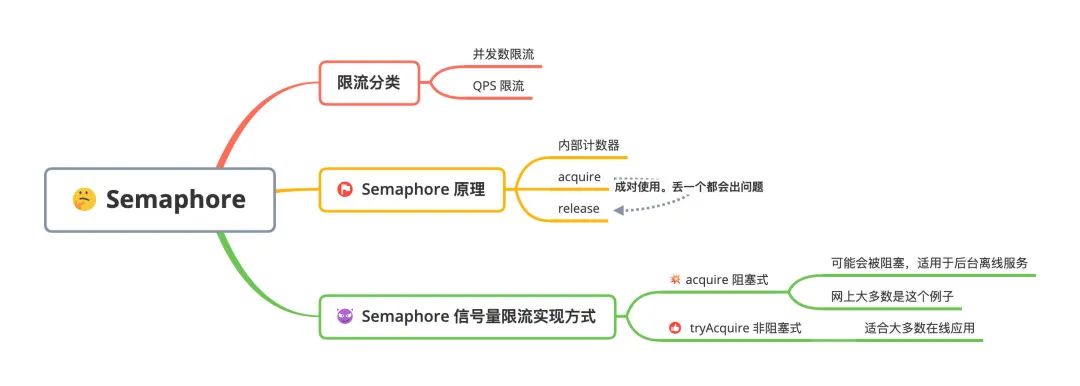
semaphore
限流的方式有很多,从类型上分类,一般可以分为两种:
并发数限流 QPS 限流
并发数限流就是限制同一时刻的最大并发请求数,而 QPS 限流指的是限制一段时间内请求数。
那我们今天的讲的 semaphore 限流其实属于第一类,通过限制并发数,到达限流的目的。
semaphore中文翻译为信号量,它其实是并发领域中一个重要编程模型,几乎所有支持并发编程的语言都支持信号量这个机制。
JDK 并发包下 Semaphore 类就是信号量的实现类,它的模型比较简单,如下图所示:
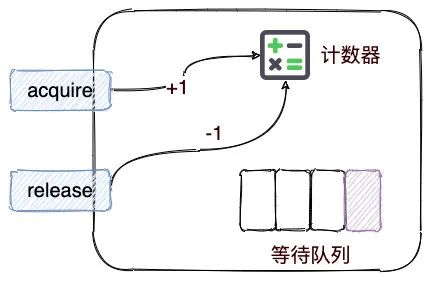
Semaphore 内部有一个计数器,我们使用的时候,需要提前初始化。
初始化之后,我们就可以调用 acquire方法,获取信号量,这时计数器将会减 1。如果此时计数器值小于 0,则会将当前线程阻塞,并且加入到等待队列,否则当前线程继续执行。
执行结束之后,调用 release方法,释放信号量,计数器将会加 1。那如果此时计数器值的小于或等于0,则会唤醒的等待队列一个线程,然后将其移出队列。
并发流量通过 Semaphore进行限流,只有拿到信号量才能继续执行,保证后端资源访问数总是在安全范围。
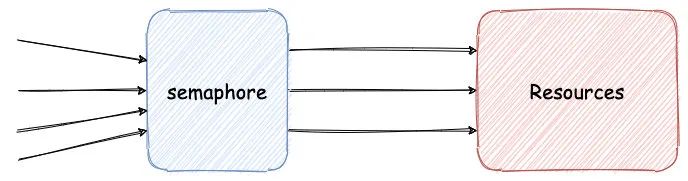
Semaphore 限流
Semaphore 限流常见使用方式
了解完 Semaphore 基本原理之后,我们就来实现一个限流器。
public class ConcurrencyLimit {
private Semaphore semaphore;
private ConcurrencyLimit() {
}
public static ConcurrencyLimit create(int permits) {
ConcurrencyLimit concurrencyLimit = new ConcurrencyLimit();
concurrencyLimit.semaphore = new Semaphore(permits);
return concurrencyLimit;
}
public void acquire() throws InterruptedException {
this.semaphore.acquire();
}
public void release() {
this.semaphore.release();
}
public boolean tryAcquire() {
return this.semaphore.tryAcquire();
}
}
限流器底层直接使用 Semaphore,我们写个例子实际测试一下:
ConcurrencyLimit limit = ConcurrencyLimit.create(5);
ExecutorService executorService = Executors.newCachedThreadPool(
new ThreadFactoryBuilder()
.setNameFormat("limit-%d")
.build());
for (int i = 0; i < 10; i++) {
executorService.execute(() -> {
try {
limit.acquire();
System.out.println(Thread.currentThread().getName() + " START");
// 模拟内部耗时
TimeUnit.MILLISECONDS.sleep(new Random().nextInt(500));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + " END");
limit.release();
}
});
}
碎碎念:这里要注意了,
Semaphore的acquire方法与release方法,一定要成对出现。如果调用
acquire,最后别忘了调用release,可能会导致程序发生假死等诡异的情况。
输出结果如下:
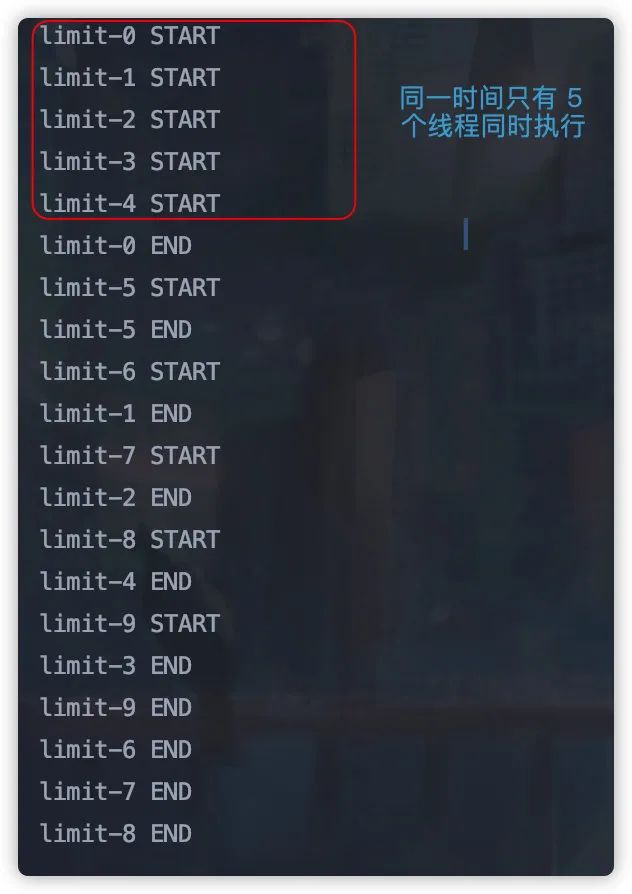
可以看到,同一时刻,最多只有 5 个线程开始执行任务,起到限流了目的。
其实随便搜下 Semaphore限流,可以看到实现方式跟上面差不多。
那这上面的限流实现真的没问题吗?
「可以说有,也可以说没有,这主要还是要看限流器使用场景。」
Semaphore 限流缺陷
如果我们换一个场景,将这个限流器用在一个 Web 服务,我们来看下高并发情况下会有什么问题。
@Slf4j
@Component
public class LimitInterceptor extends HandlerInterceptorAdapter {
ConcurrencyLimit concurrencyLimit;
public LimitInterceptor() {
this.concurrencyLimit = ConcurrencyLimit.create(10);
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
concurrencyLimit.acquire();
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
concurrencyLimit.release();
}
}
如上代码所示,我们在 SpringMVC 的拦截器中使用限流器。
任一请求执行的时候,首先将会经过 Interceptor拦截器中 preHandle 方法,在这里面我们调用获取信号量方法。
当请求逻辑完成之后,内部将会调用拦截器的 afterCompletion,我们在这里释放信号量。
在服务请求内,休眠 100ms,模拟内部接口耗时。
下面使用压测神器 「jmeter」 同时发起 500 个并发请求,模拟高并发的情况。
压测结果如下图所示:

从报表数据可以看到,虽然我们内部耗时仅仅只有 100 毫秒,但是接口平均请求耗时已经到达了 「2.4s」,P99 的耗时更是到达了 「4.4s」。
响应时间增长图如下所示:
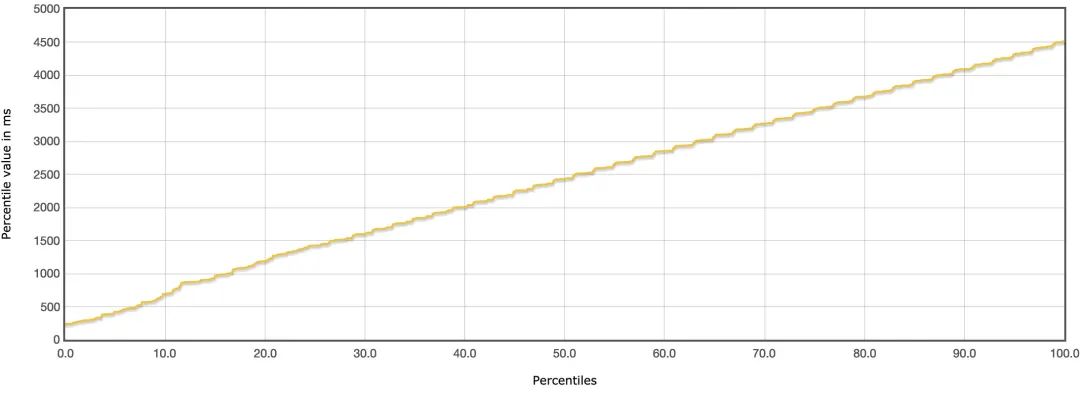
可以看到并发数越大,接口响应时间也越大。
如果这个限流器真的应用在生产环境,可能刚发布上线的时候,流量比较小,接口响应一切正常。
后面一旦碰到请求数变大,接口响应时间将会拉长,然后客户请求出现大规模的超时。
当压力继续增大,服务端可能就没办法再接受新的请求。
那为什么会这样?
主要是因为 Semaphore#acquire方法如果没有获取到信号量,是会阻塞线程的,然后线程进入等待队列。
默认情况下 Semaphore 使用不公平锁竞争,那在高并发请求下,线程竞争资源比较激烈,有的线程可能运气比较好,直接拿到信号量,那这部分请求接口耗时将会是正常。
但是有部分线程可能运气不佳,直接被阻塞,一直等到最后才能拿到信号量,才能执行。
优化 Semaphore 限流
我们目前使用的大多数服务,追求的就是一个「低延迟,高吞吐」,那这类服务到达限流线之后,就应该直接拒绝,响应响应错误信息,快速结束请求。
那 Semaphore 实际还提供另一个tryAcquire 方法,这个方法如果拿不到信号量,将会直接返回 false,比较符合这种场景。
下面优化一下上面的限流代码,主要修改一下拦截器内 preHandle 使用的方法。
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (!concurrencyLimit.tryAcquire()) {
response.getWriter().println("ERROR");
return false;
}
return true;
}
那通过这种方式,我们可以快速返回错误信息,不用让调用者一直等待。
再使用 jmeter 模拟高并发请求,结果如下:

可以看到这次响应时间就没有上一次那么夸张。
总结
一切抛开业务的架构设计都是耍流氓!
我们可以使用 Semaphore 快速实现一个限流器,不过使用过程一定注意使用场景,谨慎测试,切勿直接复制乱搬网上的代码。
那像大多数的互联网服务来讲,快速响应才是最重要的,所以限流一定不能使用 Semaphore#acquire阻塞式方法。
而像有些后台离线服务,不追求快速响应,只需要完成即可,那这类我们可以使用 Semaphore#acquire,将线程阻塞直到完成任务。
Dubbo 同步调用太慢,也许你可以试试异步处理