
数据中台建设四步方法论:采、存、通、用
共 4759字,需浏览 10分钟
·
2021-01-01 00:07
看下我现在在做的事情,富力环贸港是富力集团旗下的一家子公司,我们搭建一个服装行业的产业互联网平台。
生产端我们有针对设计师和工厂的环贸快版打版平台,销售端我们有布局线上的B2B电商平台亿订,还有线下的实体环贸港,在华南广州我们布局了60万方的展贸综合体,还有包括华东、华中都有布局。
我们还有自建的物流平台包括富运通和富贸通来运输在我们平台销售的商品。
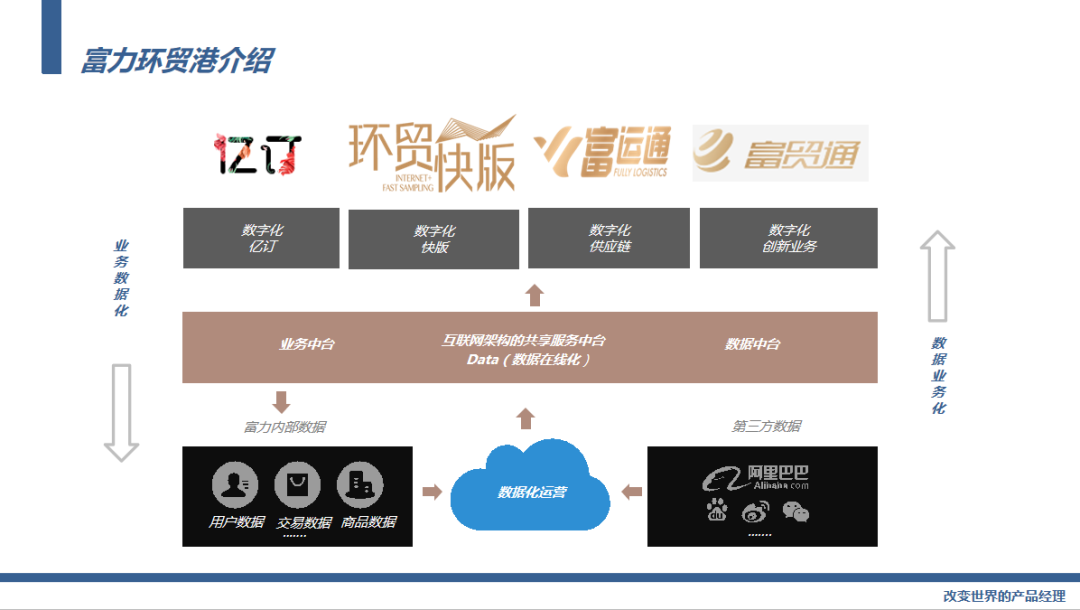
因为我们公司涉及到的产品线比较多,业务比较负载,另外从成本考虑,我们选择搭建了自己的双中台。
为什么从成本考虑呢?
今年疫情期间感触特别深,就今年疫情期间,我们新建了一个服务大客户的产品叫圆猿买手,我们只用了一个月左右的时间就完成了核心模块的搭建,这都是我们双中台发挥的力量,前期确实投入成本很大,但是到后期边际成本会非常低。
通过业务中台支持起我们的所有业务,通过数据中台帮助公司的产品线数据化运营,实现数据智能。
我有幸经历了富力环贸港双中台从0到1搭建的全过程。

我主要讲这几块内容,第一块我们一起来看几个我这几年经常被问到的典型问题。接下来我们按照数据处理的链路讲一下,从数据采集、到数据存储、数据打通、到数据应用我们是怎么做的。首先来看一下什么是中台:

在2015年年中的时候,马云去参观了一家芬兰的游戏公司,叫做Supercell。这家公司名字你也许不熟悉,但是他们开发的游戏你可能玩过比如《部落冲突》。这家公司一年光是利润就有15亿美金,不过员工人数非常少,只有不到200个人,而且公司里每一个开发游戏的小团队,都只有六七个人而已。
这么小规模的团队,怎么做成了这么大的业务呢?
其中一个原因是他们把游戏开发过程中,要用的一些通用的游戏素材和算法整理出来,把这些作为工具提供给所有的小团队。
同一套工具,可以支持好几个小团队研发游戏。这种管理方式,就是一个“中台”的模型。
那中台究竟应该怎么定义?
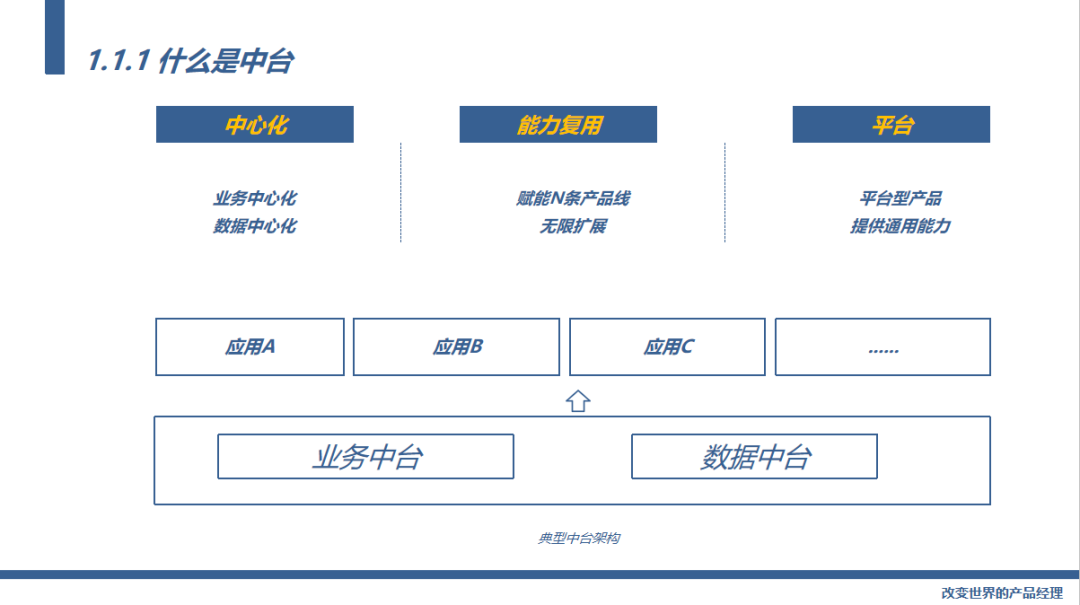
这是华仔给出的定义:中台就是中心化的能力复用平台。
“中”就是中心化,中台是公司的业务中心,也是数据中心,通过业务中台支持起公司内所有产品线的业务,通过数据中台帮助公司各条产品线做数据化的运营,实现数据智能。
“能力复用”无论是业务中台还是数据中台功能都应该可以复用,都能够支撑起公司的N条产品线,无限的拓展。
“台”是平台,中台是平台型产品,提供底层通用的能力。
中台一般来说包括:业务中台和数据中台。
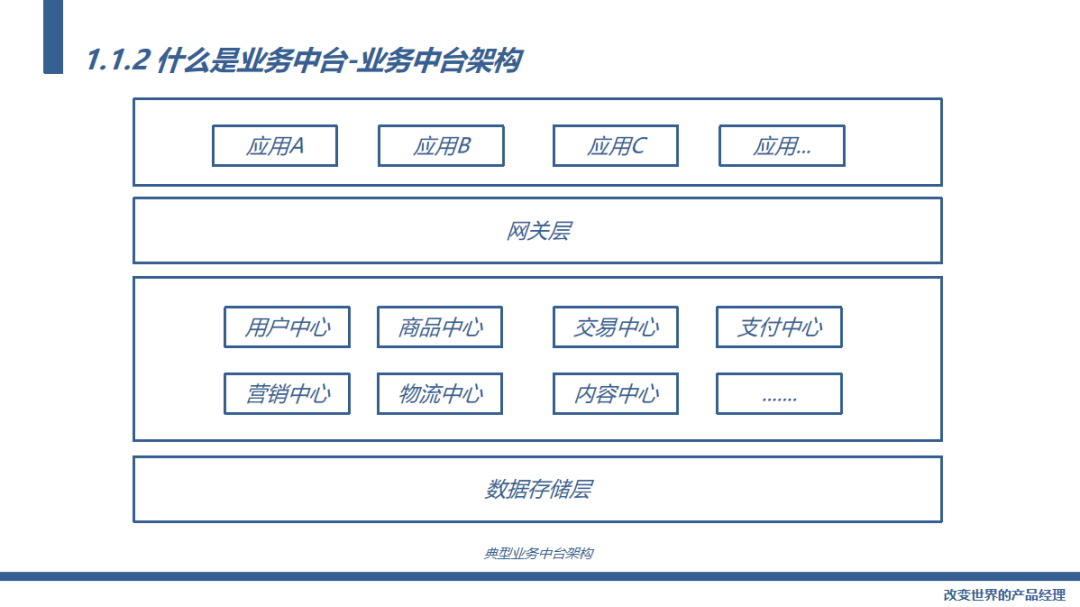
那接下来我们看一下业务中台,业务中台最重要的就是他的能力复用中心,比如这些用户、商品、支付的能力其实是任何互联网产品都需要的能力,传统的开发模式是每条产品线都要分别开发一套这些功能,有了业务中台,通过业务中台的能力中心就可以支撑起公司各个产品线的快速搭建。
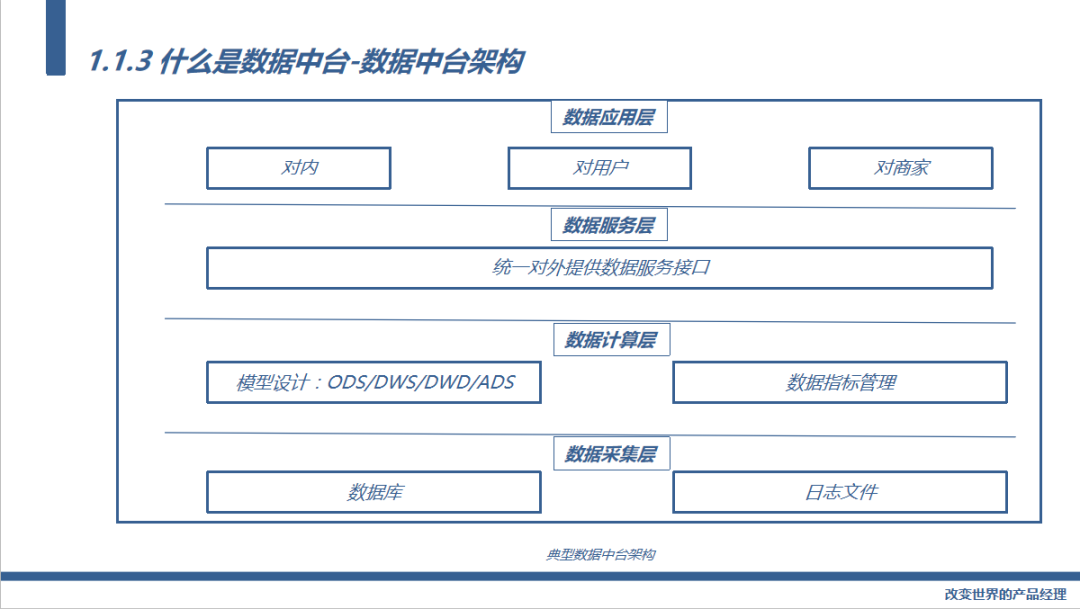
那什么是数据中台呢?按照数据处理的链路分为数据采集层、数据存储层、数据服务层、数据应用层。总结下来就4个字“采”、“存”、“通”、“用”
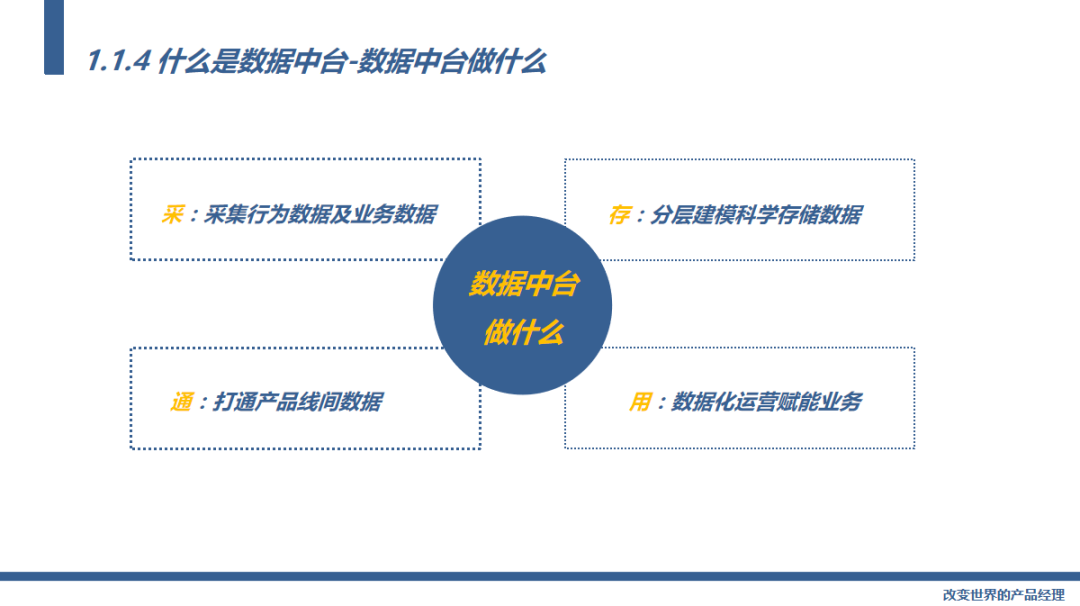
采集什么?采集用户的行为数据和业务数据。
存储什么?通过分层建模的方式将数据更加科学、有效的存储起来,形成数据资产。
怎么打通数据?一方面要打通用户的行为数据以及业务数据形成更加立体的用户画像,另外一方面要打通产品线之间的数据。
怎么应用?一方面要通过数据的手段帮助公司的内部实现产品线的数据化运营,帮助领导层决策,另外一方面也要帮助我们的用户和商家提供数据服务,通过数据帮助他们解决问题。

我们再来看一个比较关键的问题,数据中台的目标应该是什么?做产品第一个就是应该订目标,目标不同实现路径会很不一样。
这个人是阿里的曾鸣,曾经说过一句话:未来企业的核心竞争是网络协同+数据智能。
那这句话其实很残忍,反过来念就是未来如果你的公司没有数据智能+网络协同,你就没有竞争力。
什么是数据智能,数据智能的标志就是你的公司所有的决策应该交给机器而不是人工。
比如滴滴、美团、阿里本质上都是数据智能公司,背后都有一套非常强大算法帮助公司完成所有的业务。我们再来看2个比较典型的问题:

1. 业务中台和数据中台有什么关系?其实没有必然的联系,没有业务中台也是可以搭建数据中台的,但是如果已经搭建了业务中台,搭建数据中台会事半功倍,因为大部分的业务数据我们都可以从业务中台直接获取。
2. 什么公司适合搭建中台?华仔这里给一个简单粗暴的判断方法,你的公司至少是要有3条或者3条产品线以上,而且每个产品线之前都有很多复用的模块。创业公司是不适合搭建中台的,因为搭建中台前期还是要投入很大的成本。
接下来我们看一下数据采集模块,我们主要讲用户行为数据采集,也就是埋点数据的采集。
主要有这么几种方式:
1.与第三方公司合作(百度移动统计/友盟/腾讯移动分析等)
2.开源SDK自行埋点(神策/growing io等)
3.可视化埋点(友盟、growing io 等)
4.普通页面按钮可视化埋点,重要页面代码埋点(数据中台建议埋点方式)
每种方式都有优缺点,第一种的话开发成本比较低,但是这些平台采集的数据基本都是一些简单的流量相关的数据,很难和业务数据结合。
第二种的话还是有一定的开发成本,第三种简单的页面按钮是可以的,但是我们对于一些特殊的流程还是解决不了。
这些方式可能大家都尝试过,在这里我问一个问题,埋点的开发应该交给业务团队还是数据中台自己开发?
如果交给业务团队,其实就非常依赖他们,他们关注的更多的是业务功能的开发。
如果自己开发的话,对数据中台的前端要求就比较高,因为产品版本的迭代是比较快的,每次迭代都要检查我们之前的埋点还合不合理。
所以我个人推荐的方式是,可以用可视化埋点+代码埋点结合的方式,数据中台出埋点方案,规定哪些页面按钮要完成埋点。
让业务产品团队通过可视化埋点完成关键页面和按钮的埋点,需要采集的重要数据,数据中台出代码埋点的方案,让业务产品团队完成埋点。
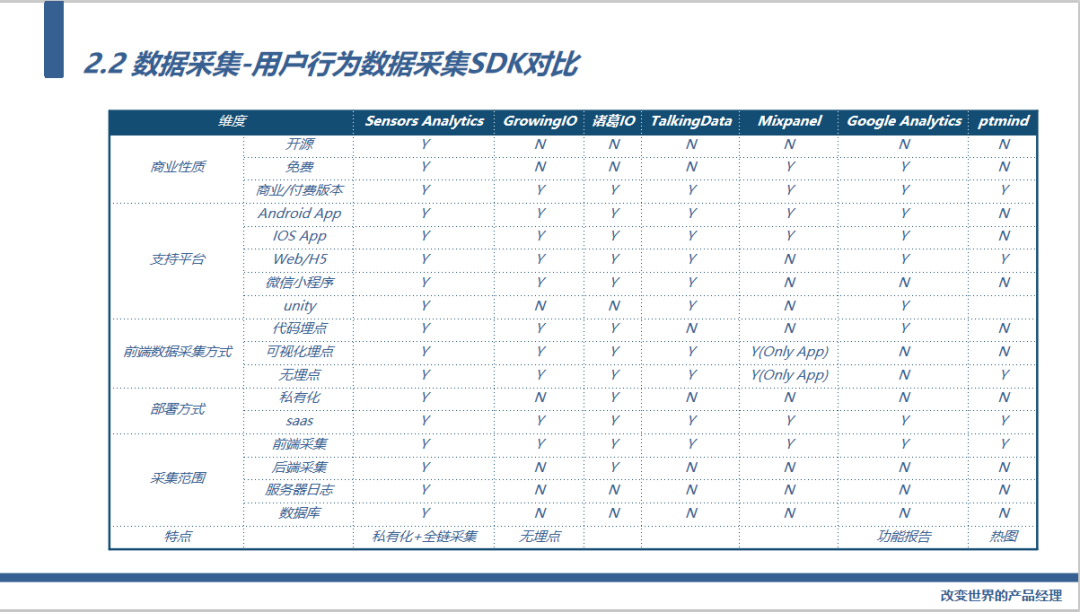
这是当时我们总结的几个主流公司埋点方案优劣的对比,会后可以看看。
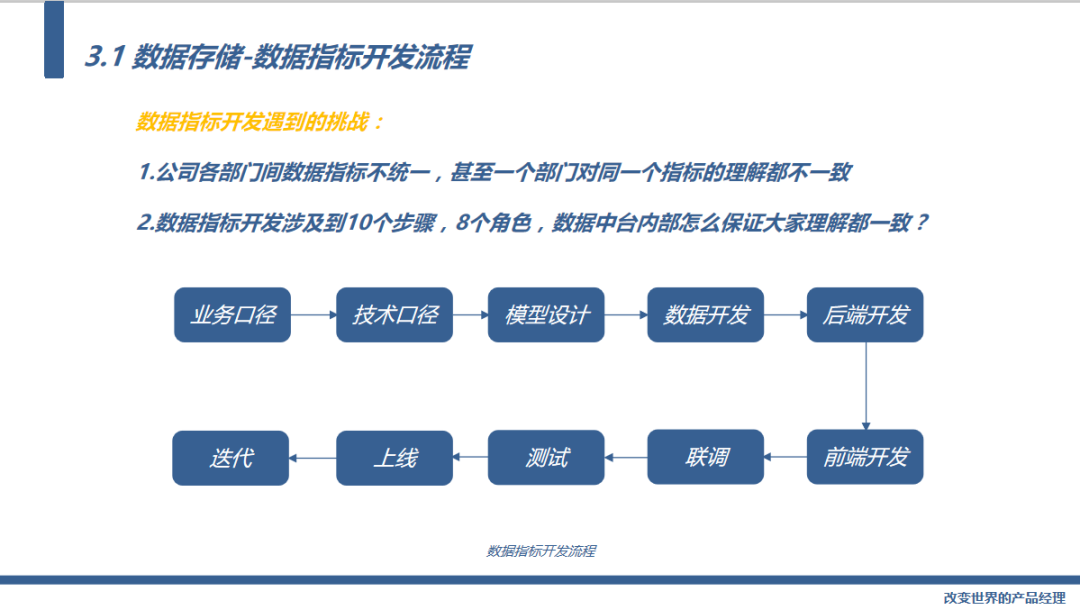
接下来我们看一下数据存储模块,当了解过公司的业务后,数据中台要做的的第一件事就是把公司的指标管理起来,当你梳理公司的指标时会遇到以下问题:
1.公司各部门间数据指标不统一,甚至一个部门对同一个指标的理解都不一致
2.数据指标开发涉及到10个步骤,8个角色,数据中台内部怎么保证大家理解都一致?
这个时候我们就需要一套统一的指标管理体系,把公司的数据指标管理起来。
比如我们要计算一个指标:最近一天通过微信支付的支付金额。
那首先它的业务板块是属于电商业务,支付金额是属于交易域,它的业务过程是支付,时间周期是最近一天,原子指标是支付金额,度量单位是金额,支付金额是通过订单的维度来计算等。
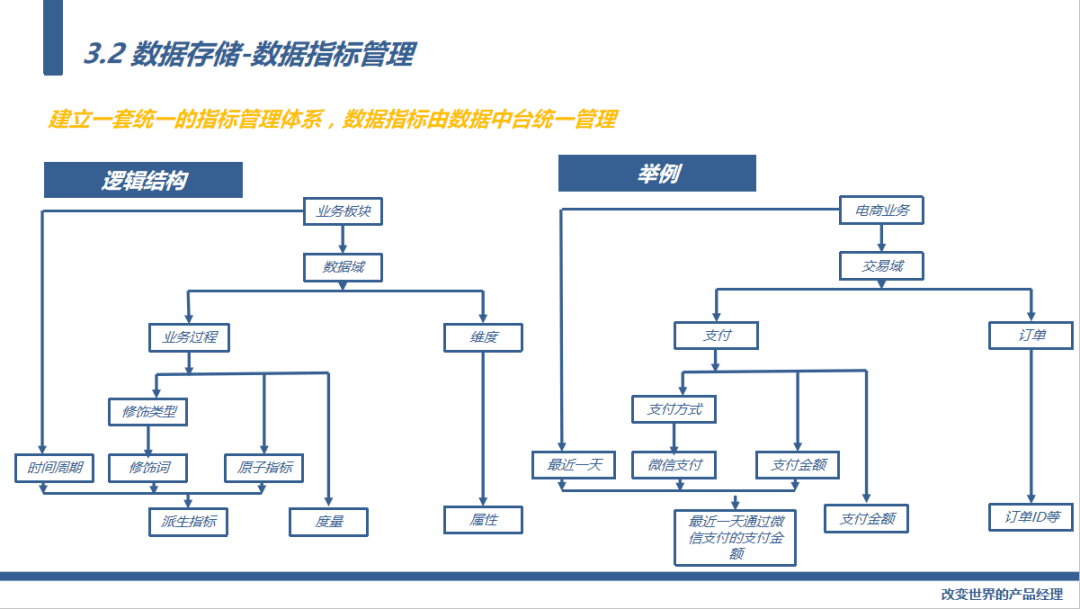
这样我们就把每个指标拆解的很细,接下来就是全公司都以这份拆解后的指标文件为标准,这样就不会出现歧义,因为大家理解的都一致,这样沟通效率就会是另外一个档次。
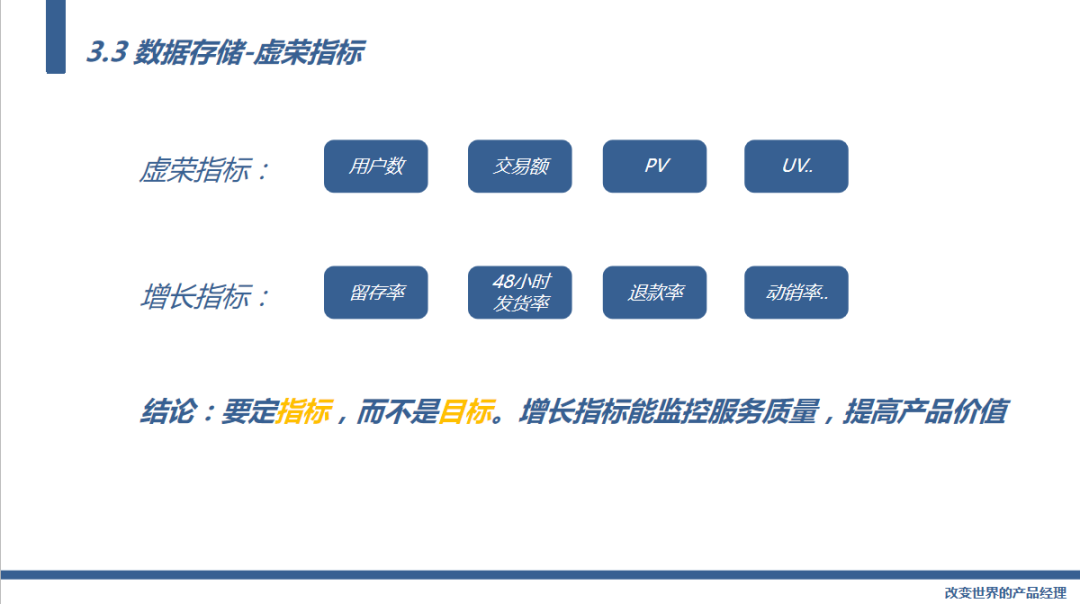
接下来我们谈一下虚荣指标,我们要定增长指标而不是目标,目标谁都能定。比如说这些指标用户数、交易额、PV、UV其实都是虚荣指标,只是起监控的作用。
而增长指标是能够帮我们发现问题,帮助我们采取行动的指标。
比如留存率,能够直接反馈出某类用户的黏性,比如电商产品的转化率能够直接帮助我们提高交易额,比如退款率能够反馈我们的服务质量,比如动销率能够反馈出我们选品的能力。
所以我们要定增长指标,而不是目标。
接下来我们看一下数据存储的数据模型设计,这就是数据中台的分层建模体系,数据从我们的ODS、到DWD/DWS、最后再到我们的ADS层做一层一层的汇总,这些概念大家可以看一下:
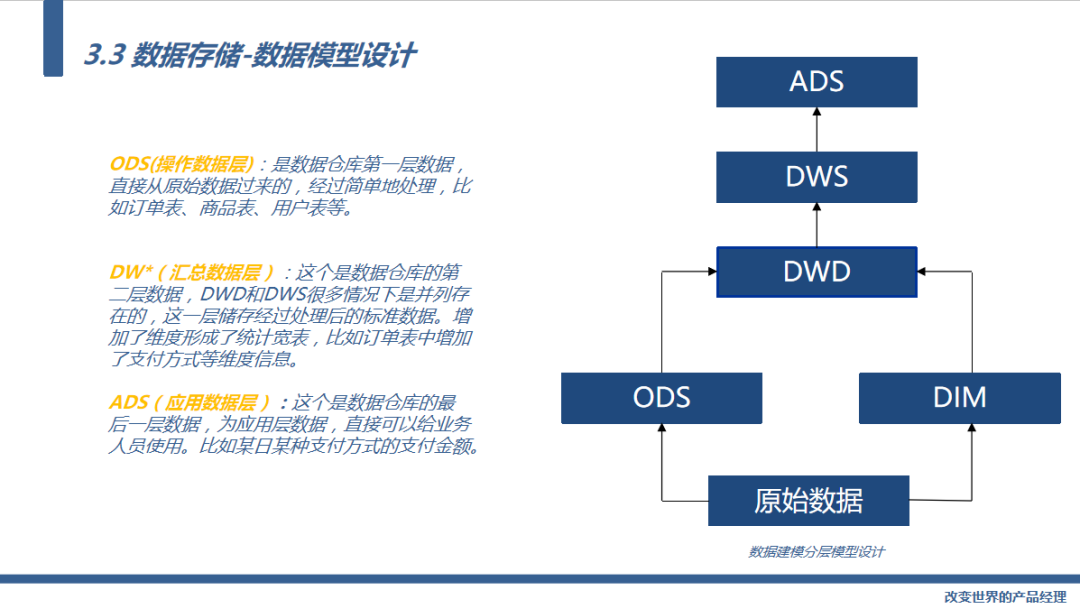
ODS(操作数据层):是数据仓库第一层数据,直接从原始数据过来的,经过简单地处理,比如订单表、商品表、用户表等。
DW*(汇总数据层):这个是数据仓库的第二层数据,DWD和DWS很多情况下是并列存在的,这一层储存经过处理后的标准数据。增加了维度形成了统计宽表,比如订单表中增加了支付方式等维度信息。
ADS(应用数据层):这个是数据仓库的最后一层数据,为应用层数据,直接可以给业务人员使用。比如某日某种支付方式的支付金额。
接下来我们看一个简单的例子,解释一下为什么要分层建模。
这是电商主路径要监测的一些核心指标,我们以访问用户数这个指标为案例看一下:
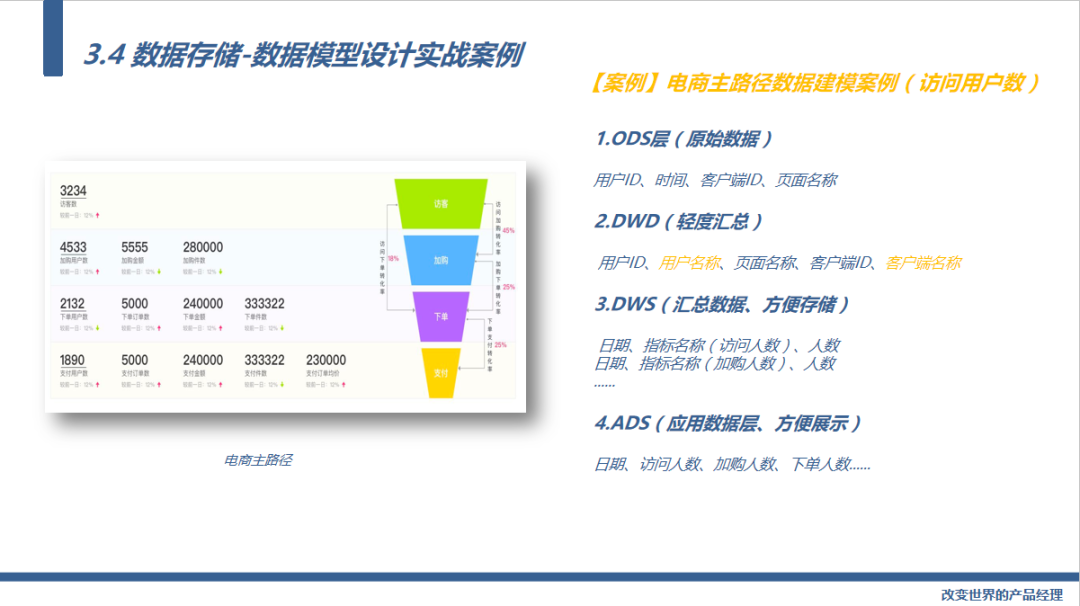
首先是ODS层,我们从埋点日志取数,关键信息就是什么人在什么时间用什么客户端访问了我们按个页面。
接下来就是DWD层,数据粒度是和ODS层一致的,只是加了一些维度,比如通过用户ID拿到用户姓名的字段,通过客户端ID拿到客户端姓名的字段。
接下来就是DWS层的数据,已经是汇总数据会记录某天某个指标的名称,指标的数据
最后是ADS层,数据就是页面要显示的数据,比如某天的访问人数、加购人数...等等。
那大家接下来可以想一下,我们这样分层建模比如某个指标的口径变了,要访问人数要剔除测试用户,那么我们ODS/DWD/ADS层的数据是不用变的,只用调整DWD到DWS层的计算逻辑,增加剔除测试用户的逻辑就可以了。整个应用是不用重新发布的,接口也不用动。
还有比如我们想新增一个维度,比如要统计某个客户端的流量数据,因为我们已经提前再DWD层预留了一些主要的维度,那么我们接下来再算这个指标会很快。
接下来我们看一下如何打通数据。首先是要打通用户行为数据以及用户的业务数据,我们通过一张宽表记录用户的基础信息(包括名称、用户类型等),用户的行为信息(地理位置、设备等信息),用户的业务信息也就是指标相关的数据。

接下来通过标签平台可以打通产品线之间的数,公司的所有产品线都统一用这么一套标签体系,无论这个用户是谁,他首先是一个人,这些基础的信息包括这人是谁,在哪里,用什么设备都可以自动化的记录。
接下来是产品线自己定义的个性化的业务标签,通过数据中台提供的标签管理功能完成自己产品线标签的个性化定义。
当公司所有的产品线都用这么一套标签体系的时候,数据就打通了,比如我们可以看到这个用户是不是用了我们的电商服务,又同时用了我们的物流服务,在各个产品线的表现怎么样,那这个数据对我们来说就是非常关键的数据。
我们已经有92类标签来自动化的标签化我们的用户。
接下来我们进入数据应用模块,首先来看一下用户分析,用户模块我们用的是经典的海盗模型,从用户的拉新到激活到留存到收入做全链条的监控。
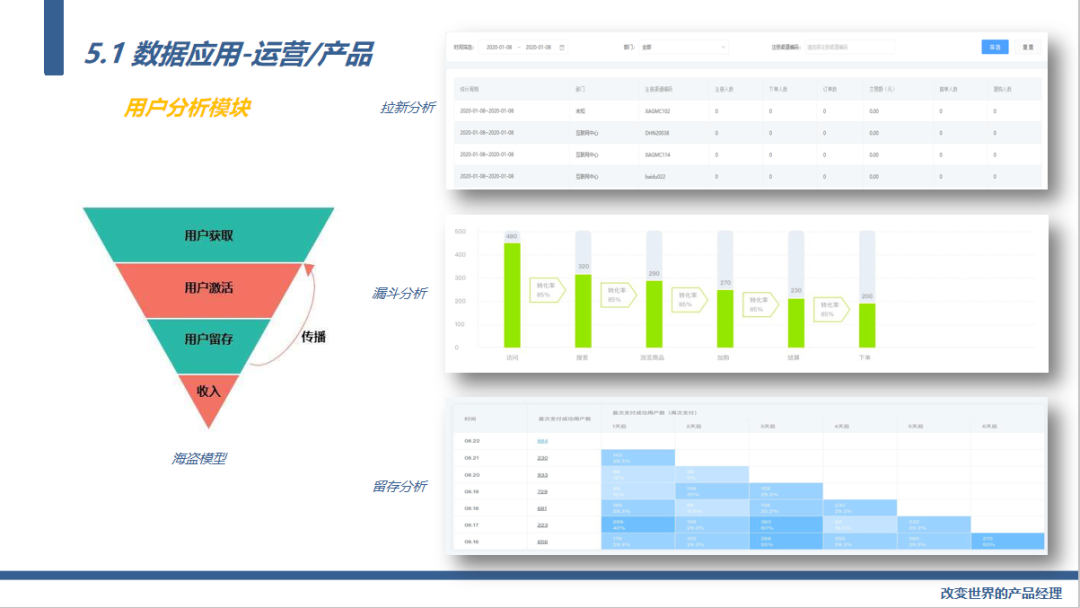
拉新模块我们可以检测到每个注册渠道某段时间内的注册人数、下单人数、首单/复购人数这些关键指标。
通过漏斗分析我们可以监测关键步骤的转化率,通过留存分析我们监测某类用户的访问以及购买留存率。
为什么我们用海盗模型做用户方面的分析,因为是通用的,几乎任何互联网产品都可以用到,现实情况也是这些基础的功能我们公司的每条产品线都在用。
接下来我们看一个典型的数据化运营的案例,订单来源分析。大家都知道互联网产品都是由一个一个的坑位组成,我们这个功能就是要分析我们的订单究竟是从那里产生的。
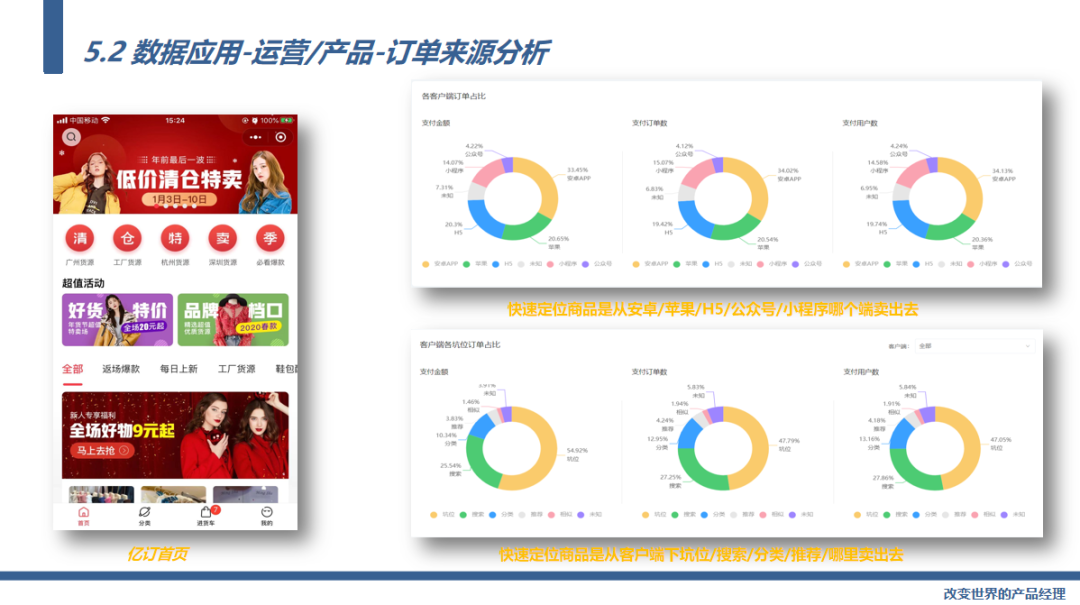
首先是那个端产生的订单,都可以自动化的输出。
接下来是更细的数据,这个订单是从搜索来的吗?那么用户的搜索关键字是什么?这个订单是从坑位来的吗?那么是从哪个坑位产生的订单,坑位的名称是什么?这个订单是从分类来的吗?那么用户点击的分类的名称是什么?
接下来我们看一个数据智能应用:自动化营销平台。
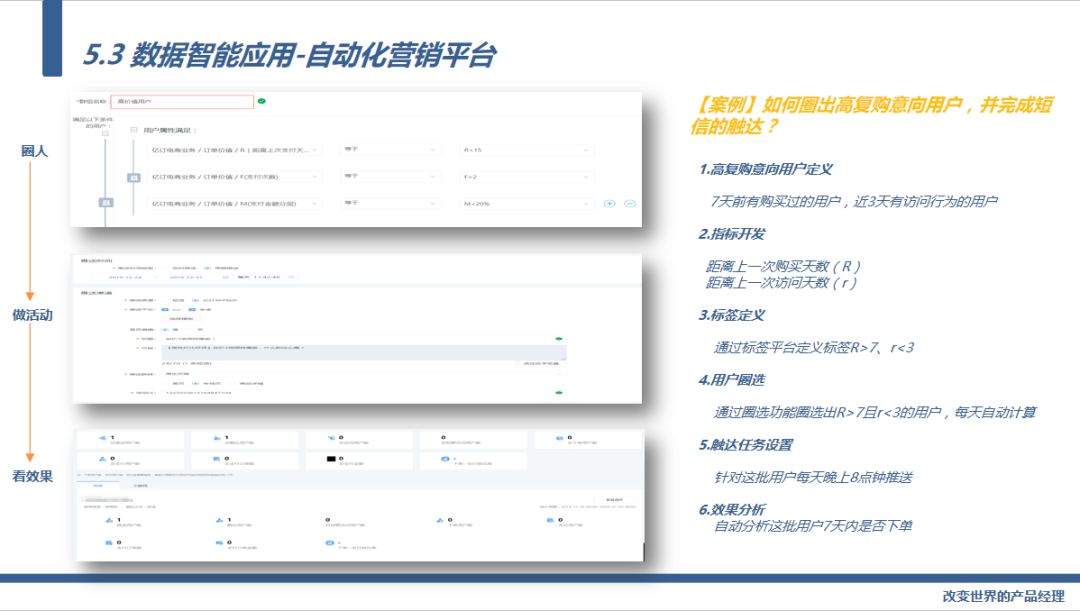
我看一个实战的案例:如何圈出高复购意向用户,并完成短信的触达?
首先是高复购意向用户定义:比如说是7天前有购买过的用户,近3天有访问行为的用户
要完成高复购意向用户人群的圈选首先要开发两个指标: 距离上一次购买天数(R)距离上一次访问天数(r),
接下来通过标签平台配置出2个标签:通过标签平台定义标签R>7、r<3
接下来通过圈选功能圈选出R>7且r<3的用户,设置为每天自动计算
接下来是触达任务设置:针对这批用户每天晚上8点钟推送短信
最后是效果分析:自动分析这批用户7天内是否下单等关键数据
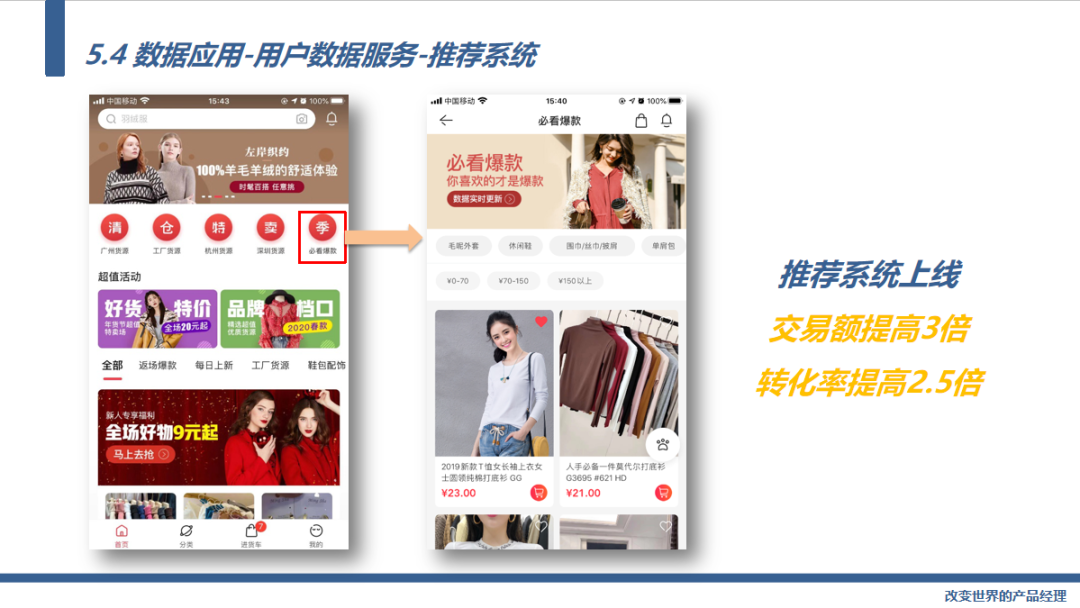
最后我们再看一个数据智能应用:推荐系统。
推荐系统是典型的数据智能应用,推荐系统上线后我们坑位的 交易额提高3倍,转化率提高2.5倍,而且完全不依赖人工组货,基于用户行为数据,通过算法自动化的给用户推荐感兴趣的商品。
我们用了实时与离线结合的推荐算法,具体可以看一下:
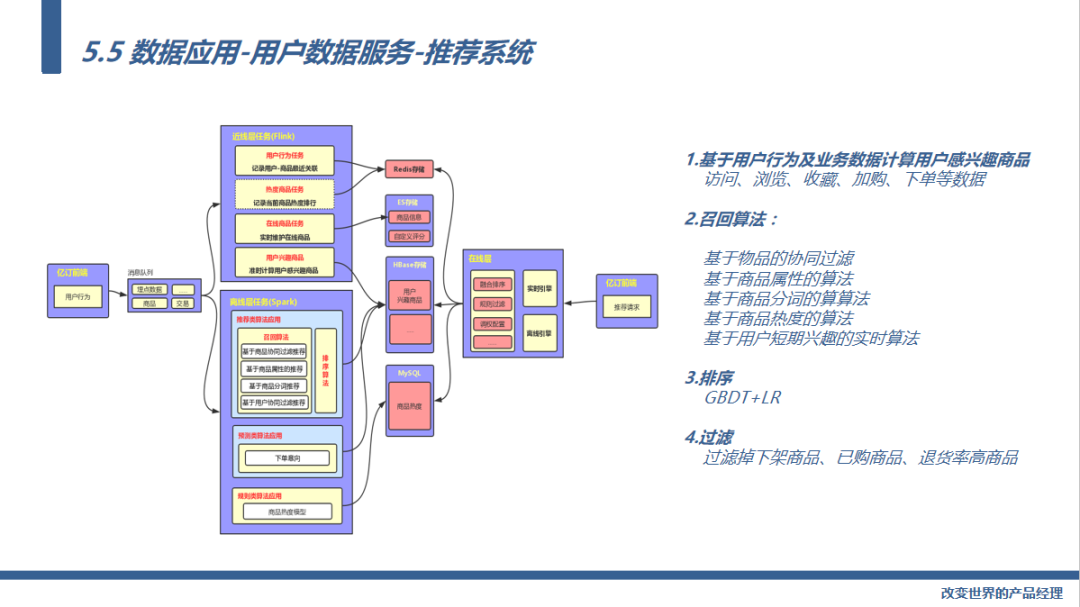
首先是用户行为数据的采集包括访问、浏览、收藏、加购、下单等数据,通过这些数据计算用户感兴趣的商品结果集。
离线召回算法我们用了基于物品的协同过滤算法、基于商品属性的算法、基于商品分词的算算法、基于商品热度的算法,通过SPARK完成离线召回结果集的计算
实时召回算法我们用了基于用户短期兴趣的实时算法,通过消息队列捕捉用户近几次的行为数据,通过Flink计算用户可能感兴趣的商品结果集。
排序算法用的是GBDT(梯度提成决策树)+LR(逻辑回归),通过统一的排序算法计算用户最终感兴趣的商品集合
会过滤掉下架商品、用户近期购买过的商品、退货率比较高的商品,将最终结果推荐给用户。
以上2个数据智能案例我们可以看出,数据智能引用讲运营人员从繁琐的工作中解放出来,他们可以专注策略的制定和测试,通过机器让策略自动化的执行,这样不仅大大降低了人力成本,而且无论是一个的策略还是推荐算法法都能自动化的产生交易额。