
Presto介绍及常用查询优化方法总结
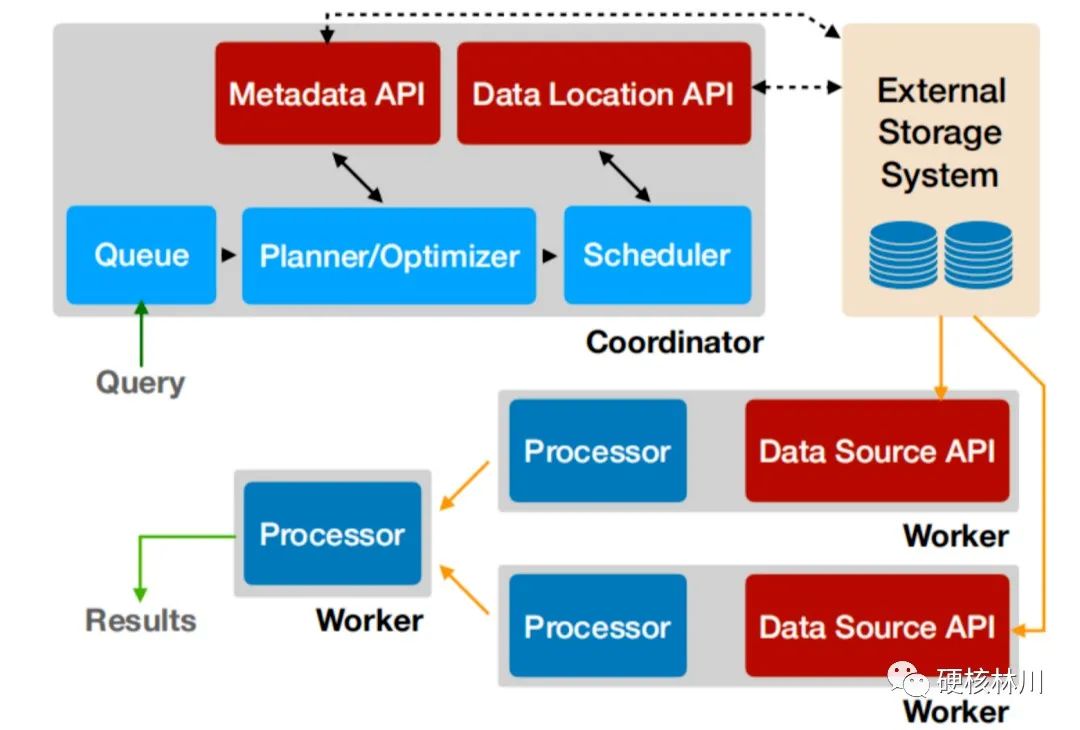
完全基于内存的并行计算 流水线 本地化计算 动态编译执行计划 小心使用内存和数据结构 GC控制 无容错
[GOOD]: SELECT GROUP BY uid, gender[BAD]: SELECT GROUP BY gender, uid
[GOOD]SELECT ...FROM accessWHERE regexp_like(method, 'GET|POST|PUT|DELETE')[BAD]SELECT ...FROM accessWHEREmethod LIKE '%GET%' ORmethod LIKE '%POST%' ORmethod LIKE '%PUT%' ORmethod LIKE '%DELETE%'
set session distributed_join = 'true'SELECT ...FROMlarge_table1join large_table2on large_table1.id = large_table2.id
SELECT ...FROMt1JOIN t2ON t1.a1 = t2.a1 ORt1.a2 = t2.a2改为SELECT ...FROMt1JOIN t2ON t1.a1 = t2.a1unionSELECT ...FROMt1JOIN t2ON t1.a2 = t2.a2
WITH tmp AS (SELECT DISTINCT a1, a2FROM t2)SELECT ...FROM t1JOIN tmpON t1.a1 = tmp.a1unionSELECT ...FROM t1JOIN tmpON t1.a2 = tmp.a2;

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
评论