
GPU制霸AI数据中心市场


1.1. GPU 架构
GPU 架构特点。GPU 架构特点与其需要处理的任务相关,其处理和显示的计算机图形本质上都是二维数据矩阵。计算机图形显示的基本单元是像素点,众多像素点构成各种线段、平面和形状,通常我们说的 320*215 的显示屏是指像素点行数是 320个,列数是 215 个,构成一个 320*215 的矩阵,布满整个屏幕。由于图像信息都是以这种矩阵像素点形式存储和呈现的,因此处理图片的 GPU 需要以矩阵形式存在的基本处理单元,来分块处理这些矩阵数据。

GPU 与 CPU 区别。从 GPU 与 CPU 架构对比图可以看出,CPU 的逻辑运算单元(ALU)较少,控制器(control)占比较大;GPU 的逻辑运算单元(ALU)小而多,控制器功能简单,缓存(cache)也较少。GPU 的众多逻辑运算单元呈矩阵排列,可以并行处理数量众多但较为简单的处理任务,图像运算处理就可以进行这样的拆解。GPU 单个运算单元处理(ALU)能力弱于 CPU,但是数量众多的运算单元可以同时工作,当面对高强度并行计算时,其性能要优于 CPU。
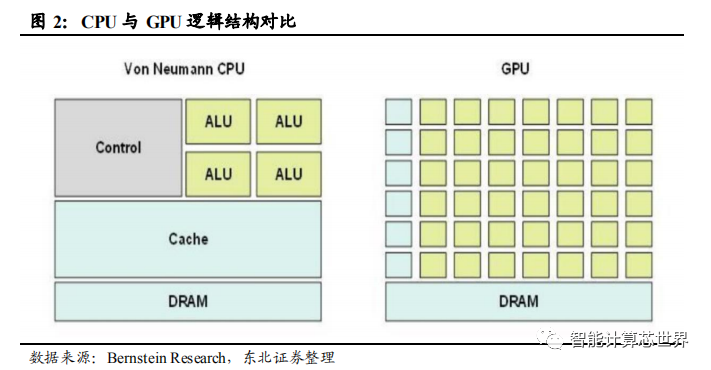
以英伟达 Maxwell 架构的 GM200 处理器说明 GPU 的内部结构。该处理器由 4 个图形处理集群(GPC)和 16 个流处理集群(SMM)组成。每个流处理集群又由 4个调度器组成,每个调度器控制着 32 个逻辑计算内核(core),这些计算内核就是实现逻辑运算的基本单元。相对于 CPU 的“多核”,GPU 算得上是“众核”。

GPU 处理流程。在电脑中,GPU 被集成在显卡中进行图形处理。整个计算机运行时,CPU 将图形处理任务交给 GPU 进行处理。GPU 从 CPU 获得指令后,把大规模、无结构化的图像数据分解成许多独立的块,分配给各个流处理集群(SMM)。每个流处理集群再次把数据分解,分配给调度器,调度器将任务放入自身所控制的 32个计算内核(core)中完成最终的数据处理任务。如果将一个 core 的运算过程记为一个线程,那么该显卡就有 32*4*16=2048 个线程同时进行。而当前英特尔最强大的酷睿 X 系列处理器顶配也只能做到 18 核、36 线程。这些任务单一、数量众多同时进行的线程可以大大缩短计算机运算时间,这即是 GPU 在图形处理方面的优势所在。
GPU“众核”使其在并行处理占优势。从 GPU 与 CPU 架构来看,GPU 处理核心数量众多,主要用来快速处理图像像素矩阵和显示控制。当前,GPU 也被用作图形以外的数据处理,其架构决定了其适合于数据之间关联性不高,可分块处理的大规模并行计算。打个比方直观地解释一下 GPU 和 CPU 的区别,如果将 CPU 比作一个从加减乘除到微积分样样精通的博士生,那么 GPU 就是数以千计的小学生。如果任务是几千道十以内的加减法题目,当然还是小学生们每人一道题所耗费的时间较短。计算机图形处理这一领域需要多线程并行化处理,为了迎合这一需求,GPU 在图形处理及通用并行化计算方面取得了快速发展。
GPU 主要处理高度可并行的任务,具有更高的运算电路密度、更密集的处理内核,更高的时钟频率。GPU 具有很高的浮点运算能力。以英伟达专为游戏玩家设计的 GEFORCE GTX 1080 Ti 显卡为例,其核心数达 3584 个,时钟频率达 1582MHz,显存速率达 11Gbps。具有超强性能的通用 A.I 加速卡—Tesla P100,能够为 HPC 和超大规模工作负载提供每秒超过 20 万亿次的 FP16 浮点运算性能,最大功耗为 300W。

GPU 向通用计算方向发展。GPU 在并行计算、浮点以及矩阵运算方面的强大性能,使其获得了需要大量并行计算的深度学习等高性能运算市场的青睐。与传统的 CPU服务器相比,采用 GPU 加速的服务器在达到相同计算精度条件下,可将训练速度提高 5~10 倍。
早在2011 年,谷歌大脑项目(Google Brain)通过观看 You Tube 上的电影学会了识别猫脸。识别过程(推理阶段)需要用到 2000 颗服务器 CPU。随后在英伟达与斯坦福大学的合作项目中,将 GPU 用于深度学习,经测试 12 颗 GPU 的性能与谷歌 2000颗服务器 CPU 的性能相当。
2015 年在 ImageNet 1000 挑战中,微软亚洲研究院视觉神经组采用 GPU 为其冠军系统(基于深度卷积神经网络(CNN)的计算机视觉系统)加速。该系统首次超越了人类对图形识别和分辨的能力,识图错误率 4.94%,低于人眼的 5.1%。
GPU 耗能较大。集成在游戏 PC 中,用于图形处理的 GEFORCE GTX 1080 Ti 显卡功耗达到了 250W,专用于 A.I 数据中心的 Tesla 系列加速卡功率也基本都在 300W左右。用于 PC 的英特尔酷睿 i 系列 CPU 功耗一般在 50-70W 之间;用于服务器端的英特尔 Xeon E 系列 CPU 功耗也只在 90-130W 之间。配备英伟达 GEFORCE GTX 1080 Ti游戏显卡的 PC 机功率一般为 600W,显卡占据整个系统能耗的 42%,而 CPU只占系统的 10%左右。而在数据中心中,至少支持 4 片 GPU,高性能 HPC 可以支持多达 16 片 GPU。若搭载 4 片 GPU,光是 GPU 加速器的功率就达到了 1,200W;16 片则要 4,800W,这相当于 3.2 个家用两匹空调同时工作,功率非常大。
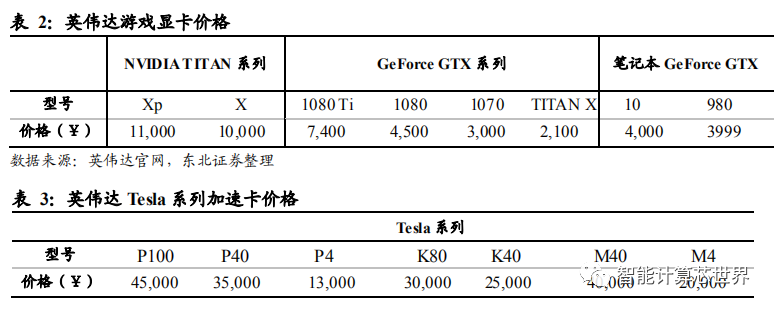
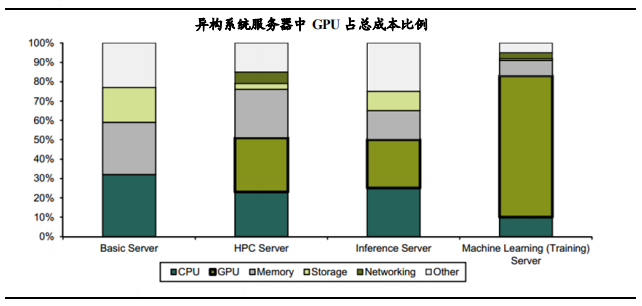
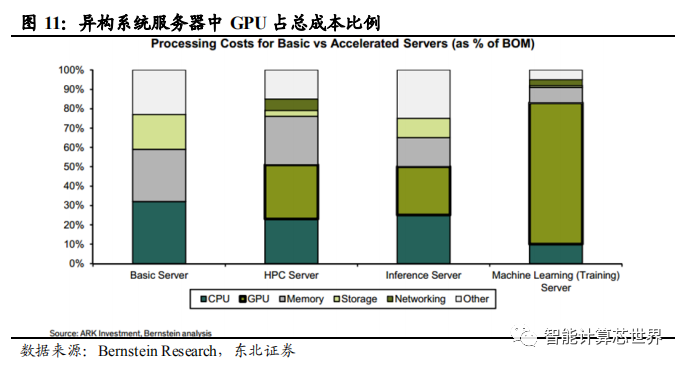
GPU 价格昂贵。从英伟达用于游戏 PC 的 GPU 显卡价格表上可以看出,当前国内市场上还在出售的游戏显卡价格从 2 千元到 1 万元不等。这还是以京东商城上低配版的最低价格计算。新推出的显卡基本在 5 千到 1 万左右,价格较为昂贵。英伟达应用于 A.I 数据中心和超级计算的特斯拉(Tesla)系列计算卡价格都在万元以上。在数据中心中,GPU 加速卡不止一个,其在数据中心中成本所占比重较高。
GPU 的早期发展史,即是计算图形学的发展史。早期 GPU 的出现主要是为了加速图形绘制,减轻 CPU 的工作量。这个时代被称为“固定功能架构((fixed function architecture)”时代,时间是 1995-2000 年。这一时期 GPU 的计算模式是流式计算,流水线上的各个功能模块单元分别固定、硬件化各自需要实现的功能,各功能模块单元实现对输入数据的相同流式操作,完成批量处理任务。
GPU 的分离渲染架构时代。进入 20 世纪后,GPU 着力提高图形渲染能力,加强图形处理的灵活性和表现力。这一时期称为“分离渲染架构(separated shader architecture)”时代,时间为 2001-2005 年。这一时代实现了渲染器的可编程化,主要变化是:用可编程顶点渲染器替换了变换与光照相关固定单元;用可编程像素渲染器替代了纹理采样等相关固定单元。但是这两个可编程渲染器不能相互通用,因此称之为可分离渲染器架构。
GPU 的统一渲染架构时代。为进一步增强 GPU 渲染的调度灵活性,从 2006 年至今,GPU 开始提供几何渲染程序,部署统一调度的渲染硬件。这一时代,称之为“统一渲染架构(unified shader architecture)”时代。这一时期的 GPU 对指令、纹理、精度等方面的处理进一步改善,图形渲染技术达到前所未有的高度,成为许多专业媒体工作站专用的高性能图形处理器。同时,这一阶段,GPU 在整数、单/双精度浮点运算等方面的能力也进一步提升,统一调度、可编程性提高,使得 GPU 向通用化方向发展。
PC 端 GPU 芯片市场行业集中程度高,由三大巨头公司垄断。英伟达主要生产独立显卡,专门针对游戏 PC 和专业图形工作站这样具有大量图形处理需求的客户。英特尔和 AMD 作为 CPU 厂商,主攻集成显卡,为 PC 提供基本的图形处理需求。因此在总的 PC 端 GPU 市场,英特尔占据较大优势。在独立显卡市场上,英伟达具有优势,占据了市场绝大多数份额,剩下的小部分独显市场份额被 AMD 瓜分。
当前的 A.I 可以划分为两个阶段:学习阶段和推理阶段。前者是通过对训练数据进行学习,形成经验的过程,为 A.I 独立解决问题做准备。后者是利用学习阶段学习到的经验解决 A.I 遇到的实时、变化的问题的过程。学习过程比推理过程更为复杂,对处理能力要求更高。学习部分是驱动 A.I 增加处理能力需求的主要因素,训练类神经网络需要对海量信息进行处理运算,学习阶段的一般做法是将训练负载切割成许多同时执行的工作任务,因此能够进行浮点运算及并行运算的处理器是学习阶段的主要需求。
学习阶段主要在数据中心完成,对处理器的运算性能要求较高。由于学习阶段是在数据中心中对海量数据进行离线处理,所以学习阶段对 A.I 芯片的运算性能要求较高,对芯片功耗、价格不敏感。
推理阶段多用于消费前端,更看重处理器的性能功耗比及成本。在推理阶段,神经网络只需将输入数据带入已经训练好的算法中,得到与之映射的输出结果。一般发 生在应用前端,是对已经训练好的模型进行实时应用。其运算能力要求没有学习阶段强,但是要求处理器能适用前端环境。因此推理阶段更为注重的是处理器的性能功耗比和价格。
GPU 性能高、功耗大、价格高,适用于学习阶段(数据中心)。GPU 在并行计算、浮点以及矩阵运算方面具有强大的性能,但是其功耗较大、价格较高。但这些对于数据中心来说都不是太大问题。数据中心作为 A.I 深度学习高性能计算平台,快速完成对海量数据的多层次、多迭代模型分析处理才是关键。目前采用 GPU 加速的服务器已经可将训练速度提高 5~10 倍,这对于 A.I 研发人员来说可以加快其成果转化速度。从 2011 年,人工智能研究人员首次使用英伟达 GPU 为深度学习加速后,GPU 在 A.I 领域发挥的巨大作用逐渐被人认识。越来越多的数据中心采用 GPU 加速方案来提速深度学习,GPU 也开始向通用 GPU 方向发展。
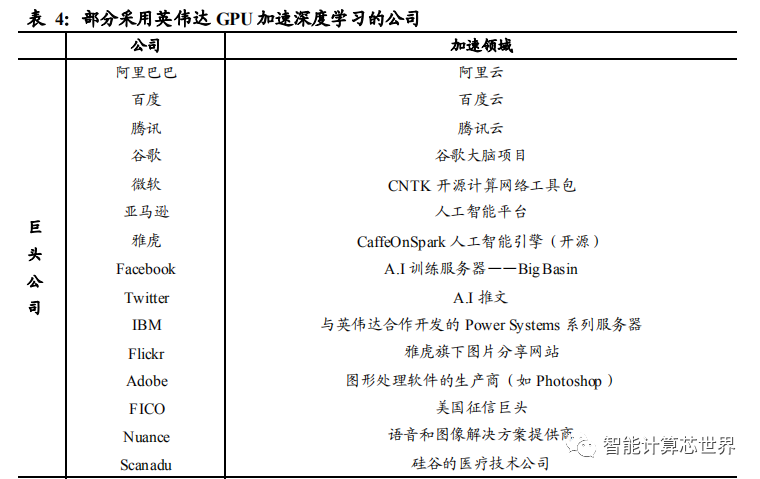
随着人工智能的不断渗透,GPU 被越来越多地应用到数据中心提供深度学习并行计算加速。从 2011 年首次被应用到 A.I,经过几年发展,GPU 通用性越来越强,并行计算能力越来越高,已经将深度学习训练时间从数周缩短到几天。几乎所有互联网巨头都在依靠强大的 GPU 加速深度学习应用,处理复杂的算法及海量的数据, 提高人工智能运行速度和执行效果。
微软发布的 CNTK(Computational Network Toolkit)开源深度学习神经网络工具包,就是基于英伟达 GPU 开发的。CNTK(Computational Network Toolkit,即计算网络工具包),是微软研究院开发的开源深度学习神经网络工具包,最多支持 8 个GPU 并行运算。
虽然一些其他芯片厂商也在研发基于 FPGA 或者 ASIC 的 A.I 芯片。但不得不承认GPU 广泛用于各种深度学习平台,已经成为了不可忽视的事实。GPU+CPU 异构架构成为面向 A.I 服务器的主流架构。随着计算复杂度的逐步提升,服务器采用的处理系统并未单纯的只有 GPU 或 GPU,而是由 CPU 和 GPU 组合而成的异构系统,两种处理器各取所长,密集的处理任务交给 GPU,复杂的逻辑运算交给 CPU,两种处理器协同工作,提升系统的运算速率。在 A.I 处理需求带动下,异构系统越来越普遍,GPU 的市场需求也会进一步的扩大。Bernstein Research 统计数据表明,随着 GPU+CPU 异构系统越来越多地应用到 A.I 领域,GPU 价格在数据中心成本占比越来越高。
GPU 的广泛使用使得传统 GPU 厂商受益。随着 GPU 在数据中心的广泛使用,GPU龙头厂商获益,数据显示, 自从 2011 年 GPU 应用于人工智能领域以来,英伟达作为最有竞争力的 GPU 厂商,成为芯片市场的宠儿。
图形处理厂商向 A.I 厂商转型。GPU 概念的首次提出,还是在 1999 年英伟达发布其 GeForce 256 图形处理芯片时。GPU 的出现减轻了 CPU 的工作负载,减少了图形显示任务对 CPU 的依赖,使得计算机图形处理能力得到快速提升。公司在独立显卡领域一直占据着绝对的竞争优势。随着 GPU 通用计算能力被发掘,英伟达在数据中心市场获益。看到 A.I 广阔的应用前景后,公司也从之前的图形处理公司开始转型成 A.I 创业公司。
英伟达继续在 A.I 数据中心端、云端发力,研发各个平台的 GPU 加速解决方案。英伟达开发的 NVIDIA DGX-1 人工智能超级计算机,是世界上首台专为深度学习和人工智能加速分析而打造的系统,性能堪比 250 台传统服务器,将神经网络训练时间从原来的几个月缩短到了几天。Tesla V100 GPU 研发投入高达 30亿美元,是当前英伟达产品中性能最强大的加速卡,单个计算单元比上一代同架构计算卡快了 12 倍。HGX-1 云服务器配备了 8 块 Tesla V100 GPU,适用于公有云、深度学习、图形渲染、CUDA 计算等。目前,国内外已有众多云服务商宣布将使用Tesla V100 GPU 或搭载了该产品的云服务器,国外有亚马逊 AWS 云、微软 Azure云等,国内有阿里云、百度云、腾讯云等。另外,英伟达还推出了 Nvidia GPU Cloud,该产品为用户提供云端硬件和软件接口,用户可通过接口快速构建、训练和部署神经网络模型。
GPU 在 A.I 数据中心领域对 A.I 专用芯片的技术突袭防御性较强。相比于由图形处理器演进而来的 GPU,当前许多公司基于 FPGA、ASIC 从事 A.I 专用芯片研发,以挑战 GPU 在 A.I 领域的霸主地位,我们认为 GPU 在 A.I 数据中心领域对 A.I 专用芯片的防御性较强。GPU 的性能特点与 A.I 数据中心对处理器的需求非常契合,并且在长时间的发展中已经形成了完整的生态,相比较而言,无论是 FPGA、还是 ASIC路线 A.I 专用芯片,都尚处于发展阶段,而要成功打造一款通用芯片,时间的积淀非常重要。
GPU 具有较为完整的技术生态。高运算性能硬件、驱动支撑、API 接口、通用计算引擎/算法库、较为成熟的开发环境都为应用 GPU 的深度学习开发者提供了足够友好、易用的工具环境。开发者可以迅速获取到深度学习加速算力,降低了深度学习模型从研发到训练加速的整体开发周期。
驱动程序,独立显卡厂商不仅提供高性能硬件,也一直提供配套驱动来支持其 GPU调用计算资源。早期图形处理、游戏业务的优势地位使得英伟达一直在 GPU 驱动下了不少功夫,公司总部大多数员工都是从事驱动程序的研发工作。
从图形接口 API 来看,不同的独立显卡厂商提供不同的图形标准 API,而不同的API 接口适应于不同的计算系统,如 OpenGL标准支持 Unix系统的服务器计算平台,Direct3D 支持 windows 系统的 PC。英伟达推出的 CUDA (Compute Unified Device Architecture)通用并行计算平台,是为利用 GPU 并行运算能力开发的计算平台。可以让开发人员用 C 语言编写的程序在其处理器上高速运行,大大提升了通用 GPU的易用性。
算法库,CUDA 包括了大量的 GPU 加速库和基于 C 语言的编程工具,开发者可以在熟悉的编程环境下便捷地调用加速库。CUDA 提供的算法库可以让应用程序像调用库函数一样简单实现一些深度学习算法。CUDA 开发人员的数量在 5 年里增长了14 倍,超过 60 万人,CUDA SDK 的下载量达到 180 万。众多 CUDA 开发人员对于维持英伟达 GPU 客户黏性非常重要。
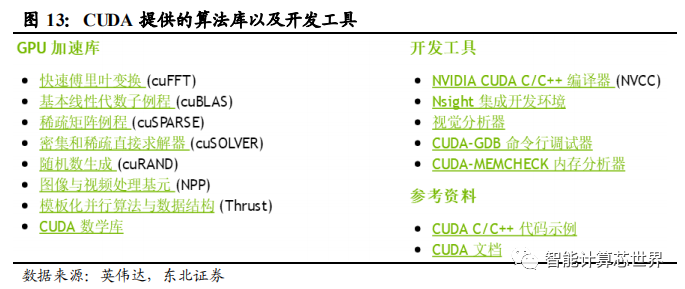
GPU 完整的技术生态,吸引了大量 AI 企业采用 GPU 进行人工智能加速,建立了良好的行业生态。英伟达与科研机构开展合作项目,深入了解科研领域需要的运算问题,为其提供专业的超级计算加速解决方案。
GPU 的高运算性能使其迅速占领 AI 数据中心市场,完备的生态环境可帮助其维持霸主地位。从上图可以看出,GPU 的浮点运算能力一直保持着直线上升。英伟达在 2017 年 GPU 技术大会上发布的全新一代人工智能 GPU 芯片—Tesla V100 能够达到 15Tflops 的单精度浮点性能,7.5Tflops 的双精度浮点性能,可以满足当前AI 深度学习的运算能力。GPU 持续提升的运算能力是其维持在 AI 数据中心这一运算密集型应用场景中霸主地位的根本,而面对众多新兴 AI 芯片的挑战,GPU已经建立起的完备的生态环境可帮助其提高防御能力。
GPU 的生态环境有利于其将在训练学习领域(AI 数据中心)建立的优势延续至推理应用领域(前端电子产品)。当前 GPU 已经占据了 AI 数据中心市场,学习阶段处理器需求已经被 GPU 占领。未来随着 AI 行业应用的逐渐落地,推理阶段处理器需求将持续放量。从学习到推理阶段,算法部署的平滑、便捷性是需要考虑的重要问题。如果从数据中心、云端到前端应用,整个产品线都采用英伟达的CUDA计算平台,可以极大地减少算法跨平台的难度,实现平滑过渡,省去了变更运行环境所需的协同工作。
相比较而言,无论是 FPGA、还是 ASIC,都尚处于发展阶段。目前有一些公司基于 FPGA 技术路线或 ASIC 技术路线开发的 A.I 专用芯片,是为满足自身的需求而进行的个性化开发。典型的就是谷歌的 TPU,公司并没有计划将其做成一款通用芯 片推向市场。有些公司也在基于 FPGA 或 ASIC 开发通用的 AI 专用芯片,但是都未达到 GPU 的成熟程度。一款芯片要做的具有通用性,性能稳定优异,需要较长时间的应用、优化、验证。但是不可否认的是,长期来看,GPU 能耗高、价格贵等问题也给 AI 专用芯片留下了机会。
GPU 的 AI 数据中心市场将继续保持高速增长。目前,AI 数据中心(A.I 数据中心只是 GPU 的全部数据中心市场的一部分,GPU应用于数据中心也有可能进行 AI 以外的超级计算)尚处于早期发展阶段,主要是互联网巨头在 AI 深度学习研发阶段部署的 AI 数据中心,随着 AI 纵深发展, A.I数据中心需求会继续保持高速增长,GPU在数据中心的市场规模会进一步爆发。
1、行业深度报告:GPU研究框架
2、信创产业研究框架
3、ARM行业研究框架
4、CPU研究框架
5、国产CPU研究框架
6、行业深度报告:GPU研究框架
1、2020信创发展研究报告
2、中国信创产业发展白皮书(2021)
3、信创研究框架
4、云计算行业:新基建和信创云计算进阶
5、深度研究:云计算与信创产业持续快速发展
6、深度:信创产业系列专题(总篇)
7、计算机行业研究:信创和鲲鹏计算产业链
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
