
SpringBoot + Elasticsearch7.6实现简单查询及高亮分词查询
Java技术前线
共 2474字,需浏览 5分钟
·
2022-02-20 00:21
点击关注公众号,Java干货及时送达👇

前言
该文章需要提前准备好Elasticsearch7.6以及ik分词器的环境,如果还没准备好的可以看看
https://blog.csdn.net/weixin_44102992/article/details/107954129
集成环境准备
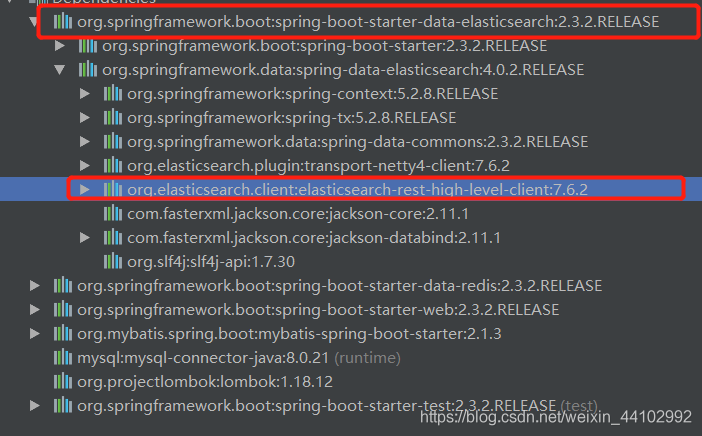
1.导入spring-data-elasticsearch依赖
版本需要与Elasticsearch一致,还需要注意自己的springboot版本是否支持
本文springboot为2.3,依赖也为2.3,elasticsearch为7.6.2
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-elasticsearchartifactId>
<version>${version}.RELEASEversion>
dependency>
2.elasticsearch配置文件
因为原来的配置不支持了
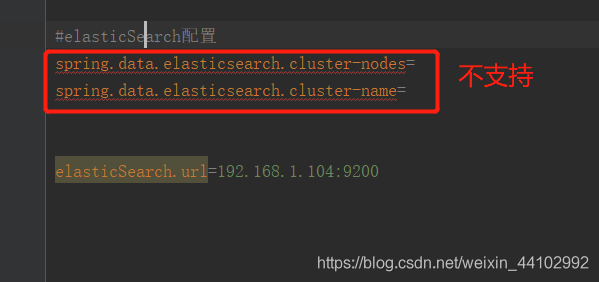
配置文件如下:
@Configuration
public class EsConf {
@Value("${elasticSearch.url}")
private String edUrl;
//localhost:9200 写在配置文件中就可以了
@Bean
RestHighLevelClient client() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(edUrl)//elasticsearch地址
.build();
return RestClients.create(clientConfiguration).rest();
}
}
3.实体类准备
关于实体类中的几个注解,不清楚的可以去查看文档,这里不过多介绍了
@Data
@Document(indexName = "user")//索引名称 建议与实体类一致
public class User {
@Id
private Integer id;
@Field(type = FieldType.Auto)//自动检测类型
private Integer age;
@Field(type = FieldType.Keyword)//手动设置为keyword 但同时也就不能分词
private String name;
@Field(type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_max_word")//设置为text 可以分词
private String info;
}
4.Elasticsearch Service准备
ElasticsearchRepository<,>第一个就是所准备的实体类,第二个是id的类型
继承完这个会提供最基本的增删改查方法,也可以自己定义一些,自己定义的方法命名需要符合规则,并不需要自己去实现
public interface EsUserService extends ElasticsearchRepository<User,Integer> {
//根据name查询
List findByName(String name) ;
//根据name和info查询
List findByNameAndInfo(String name,String info) ;
}
简单查询
这里直接使用假数据并没有连接数据库,还需要注意几个点:
elasticsearchTemplate需要采用ElasticsearchRestTemplate 原来的已经过时了 elasticsearch的mapping没有自动生成,这导致了我们在实体类中指定的分词器没有生效,所以我在导入数据的同时,手动导入了mapping LogAnnotation是我自定义的注解,大家可以直接去掉
controller如下:
@RestController
public class EsController {
@Autowired
private ElasticsearchRestTemplate elasticsearchTemplate;
@Autowired
private EsUserService esUserService;
private String[] names={"诸葛亮","曹操","李白","韩信","赵云","小乔","狄仁杰","李四","诸小明","王五"};
private String[] infos={"我来自中国的一个小乡村,地处湖南省","我来自中国的一个大城市,名叫上海,人们称作魔都"
,"我来自东北,家住大囤里,一口大碴子话"};
@LogAnnotation(requestRemark = "存数据")
@GetMapping("saveUser")
public ResultVO saveUser(){
//添加索引mapping 索引会自动创建但mapping自只用默认的这会导致分词器不生效 所以这里我们手动导入mapping
elasticsearchTemplate.putMapping(User.class);
Random random = new Random();
List users = new ArrayList<>();
for (int i=0;i<20;i++){
User user = new User();
user.setId(i);
user.setName(names[random.nextInt(9)]);
user.setAge(random.nextInt(40)+i);
user.setInfo(infos[random.nextInt(2)]);
users.add(user);
}
Iterable users1 = esUserService.saveAll(users);
return new ResultVO(users1);
}
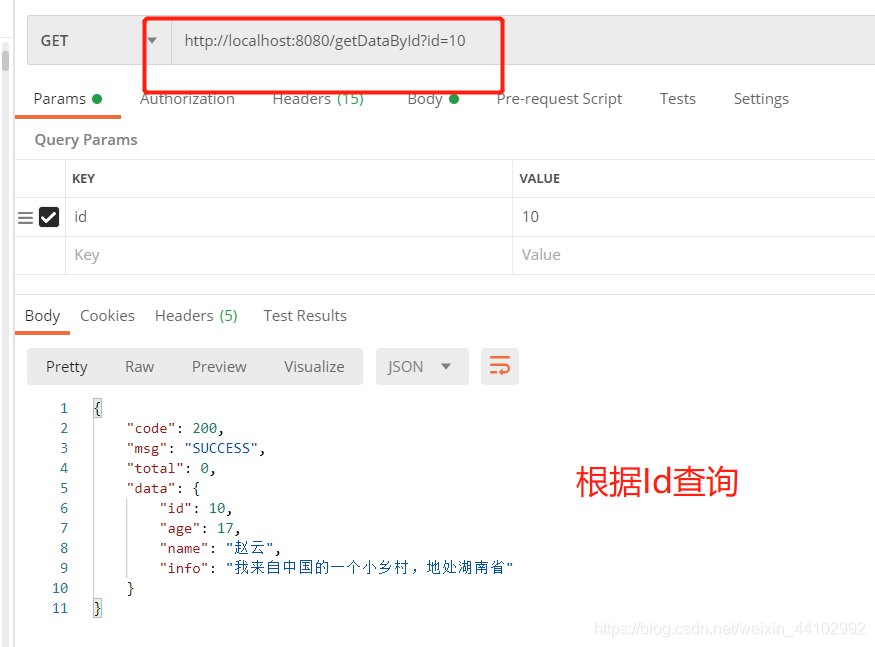
@LogAnnotation(requestRemark = "根据id查询数据")
@GetMapping("getDataById")
public ResultVO getDataById(Integer id){
return new ResultVO(esUserService.findById(id));
}
@LogAnnotation(requestRemark = "分页查询所有数据")
@GetMapping("getAllDataByPage")
public ResultVO getAllDataByPage(){
//本该传入page和size,这里为了方便就直接写死了
Pageable page = PageRequest.of(0,10, Sort.Direction.ASC,"id");
Page all = esUserService.findAll(page);
return new ResultVO(all.getContent());
}
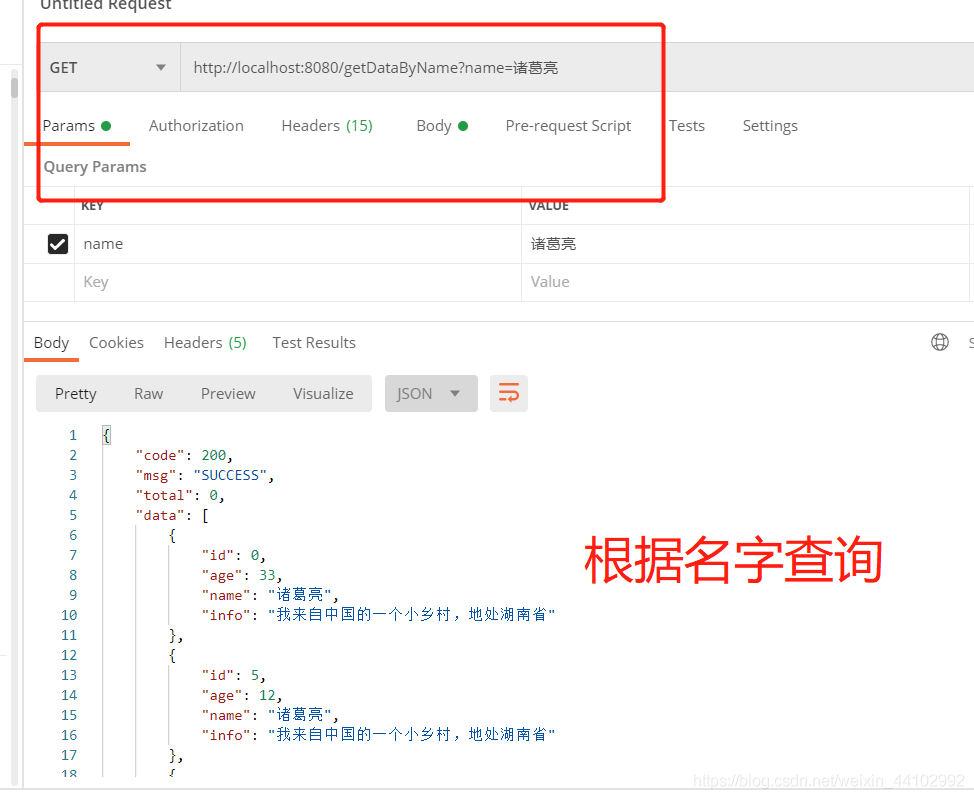
@LogAnnotation(requestRemark = "根据名字查询")
@GetMapping("getDataByName")
public ResultVO getDataByName(String name){
return new ResultVO(esUserService.findByName(name));
}
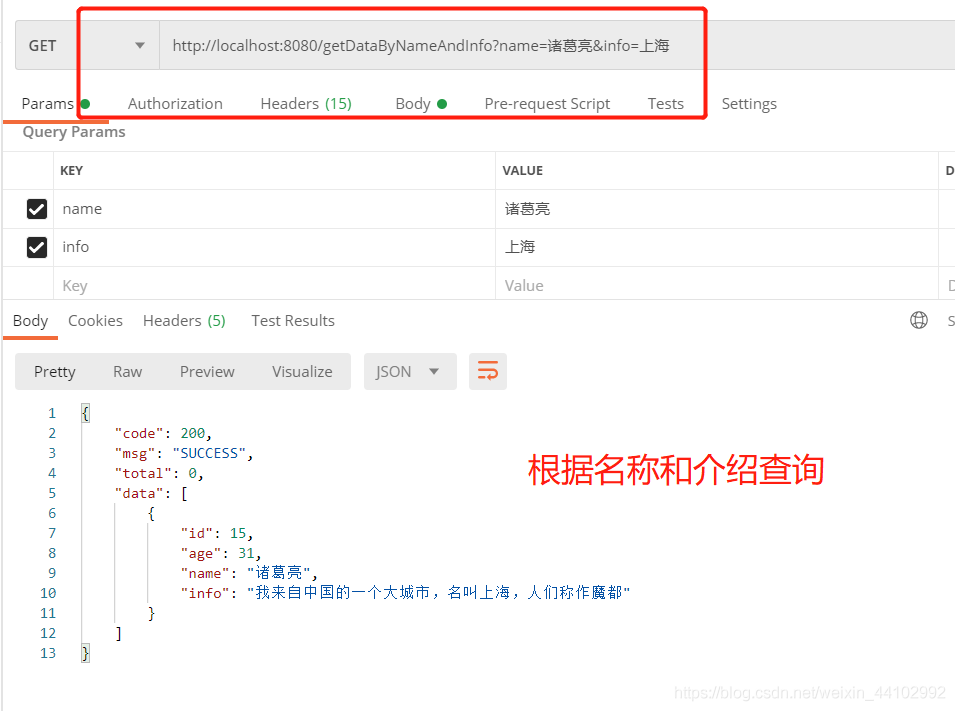
@LogAnnotation(requestRemark = "根据名字和介绍查询")
@GetMapping("getDataByNameAndInfo")
public ResultVO getDataByNameAndInfo(String name,String info){
//这里是查询两个字段取交集,即代表两个条件需要同时满足
return new ResultVO(esUserService.findByNameAndInfo(name,info));
}
}
测试结果:

分词高亮查询
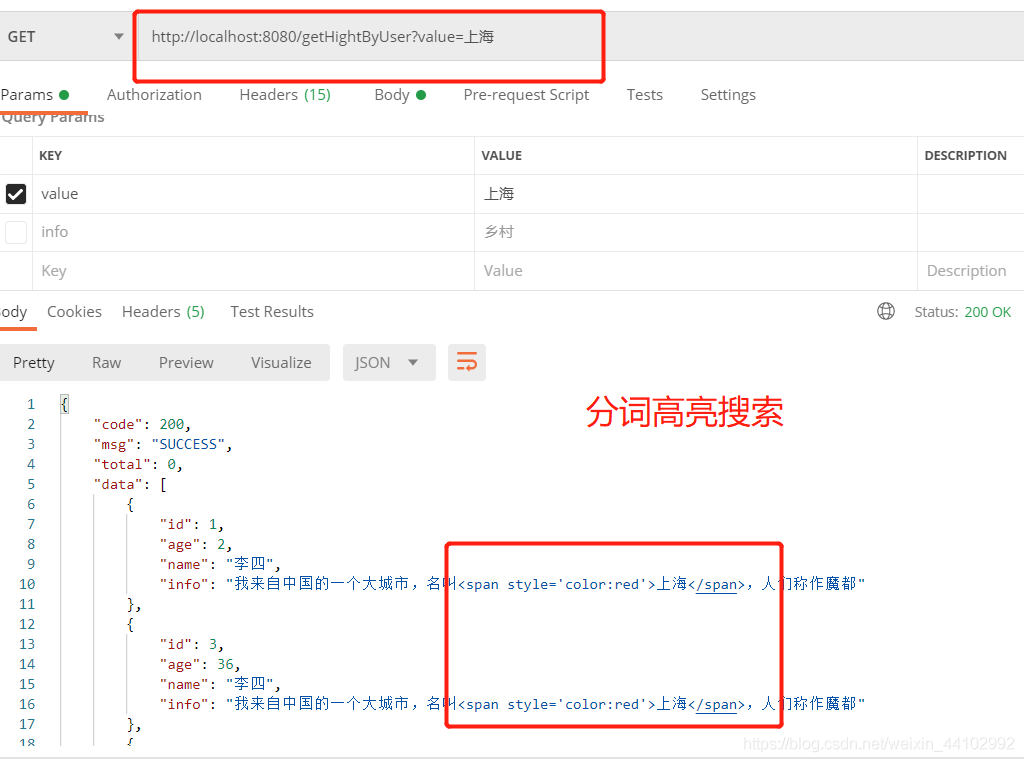
@LogAnnotation(requestRemark = "查询高亮显示")
@GetMapping("getHightByUser")
public ResultVO getHightByUser(String value){
//根据一个值查询多个字段 并高亮显示 这里的查询是取并集,即多个字段只需要有一个字段满足即可
//需要查询的字段
BoolQueryBuilder boolQueryBuilder= QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("info",value))
.should(QueryBuilders.matchQuery("name",value));
//构建高亮查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightFields(
new HighlightBuilder.Field("info")
,new HighlightBuilder.Field("name"))
.withHighlightBuilder(new HighlightBuilder().preTags("").postTags(""))
.build();
//查询
SearchHits search = elasticsearchTemplate.search(searchQuery, User.class);
//得到查询返回的内容
List> searchHits = search.getSearchHits();
//设置一个最后需要返回的实体类集合
List users = new ArrayList<>();
//遍历返回的内容进行处理
for(SearchHit searchHit:searchHits){
//高亮的内容
Map> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent().setName(highlightFields.get("name")==null ? searchHit.getContent().getName():highlightFields.get("name").get(0));
searchHit.getContent().setInfo(highlightFields.get("info")==null ? searchHit.getContent().getInfo():highlightFields.get("info").get(0));
//放到实体类中
users.add(searchHit.getContent());
}
return new ResultVO(users);
}
测试结果:
来源:blog.csdn.net/weixin_44102992/article/
details/108033164
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*

评论