
不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍

新智元报道
新智元报道
来源:ICML 2021
编辑:LRS
【新智元导读】你能找到最优的深度学习模型吗?还是说你会「堆积木」?最近,伍斯特理工学院华人博士在ICML 2021上发表了一篇文章,提出一个新模型few-shot NAS,效率提升10倍,准确率提升20%!看来「调参侠」们又要紧张了!
神经网络模型经常被研究人员戏称为「堆积木」,通过将各个基础模型堆成更大的模型,更多的数据来取得更好的效果。

为了减轻人工构建模型的工作量,用AI技术来搜索最优“堆积木”方法就很有必要了。神经架构搜索 (NAS) 就是这样一种技术,在深度学习领域逐渐受到关注,随着研究的发展,NAS能够帮助研究人员快速搭建合适的深度学习模型。
Vanilla NAS 使用搜索算法来遍历探索搜索空间,并通过从头开始训练新的架构来评估它们的性能。暴力搜索和深度学习的通病就是需要更多的时间,例如完整搜索可能需要数千小时的 GPU 时间,导致在许多研究应用中计算成本非常高,无法实际应用。
另一种方法构建流程 one-shot NAS,使用一个预训练的超网络(supernet, supernetwork),从而大大降低计算成本。这个网络能够在搜索空间中估计神经结构的准确性,而不需要从头开始训练。然而,由于操作之间的协同适应,性能估计可能非常不准确,如果是不准确的预测会影响它的搜索过程,并导致很难找到合适的模型架构。
伍斯特理工学院和Facebook AI Research最近推出了一个全新的模型few-shot NAS,这个方法平衡了Vanilla NAS 和 one-shot NAS的时间消耗的计算损失,研究结果表明,从卷积神经网络到生成对抗性网络,它都能够有效地设计sota模型。
与one-shot NAS 相比,few-shot NAS 提高了体系结构评估的准确性,评估成本增加不大。大量的实验表明,少镜头 NAS 能够显著地改进各种单镜头方法,包括 NasBench-201和 NasBench1-shot-1中的4种基于梯度的方法和6种基于搜索的方法
文章已被ICML 2021录取为long oral。

这篇论文的第一作者是赵一阳,伍斯特理工学院(WPI)的一名博士生,导师是郭甜教授。他的本科是西安电子科技大学的电子与信息工程专业,并在美国东北大学获得计算机工程的硕士学位。主要研究兴趣是在日常生活和人工智能(AI)领域之间构建应用,通过使用自动机器学习(Auto-ML)使 AI (深度学习)模型的构建更容易,同时也对机器学习和高性能计算的应用感兴趣。

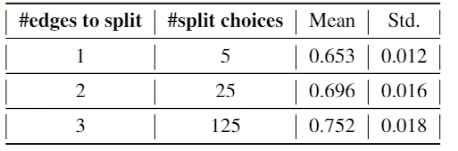
few-shot NAS 通过将搜索空间划分为不同的独立区域,然后使用多个子超网(sub-supernets)覆盖这些区域,从而提高了模型性能。
为了合理地划分搜索空间,研究人员选择利用原始超网的结构,分别挑选每个边缘连接来选择一种方法来划分搜索空间,这种方法与超网的构造方式相一致。
在设计 few-shot NAS时,研究人员主要面向这三个问题提出解决方案:
1、如何将one-shot 模型表示的搜索空间划分为子超网,以及在给定搜索时间预算的情况下如何选择子超网的数目?
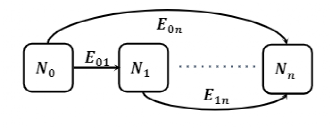
如下表所示,增加划分复合边(split compound edge)的数量会导致更高的秩相关性。给定相同数量的复合边进行划分,选择哪条复合边进行分割对低标准偏差所表示的秩相关性的影响可以忽略不计。因此,研究人员随机选择要分割的复合边,并关注要分割多少复合边。
在这项工作中,预先定义了一个训练时间预算T。如果超网和所有当前训练的子超网的训练总时间超过T,将停止划分以避免训练更多的子超网。一般来说,T是一次超网训练时间的两倍。
2、如何减少多个子超网的训练时间?
子超网的数目随着划分复合边的数目呈指数增长。直接训练所有产生的子超网在计算上很困难,而且也失去了one-shot NAS的优势。所以研究人员结合迁移学习技术来加速子超网的训练过程。
3、few-shot NAS如何与现有NAS算法集成?
基于梯度的算法需要运行在一个连续的搜索空间,可以从有向无环图(DAG)转换。基于梯度的算法将NAS视为一个联合优化问题,通过训练同时优化权重和架构分布参数,也就是说,基于梯度的算法是为one-shot NAS设计和使用的。
为了将基于梯度的算法用于few-shot NAS,首先训练超网直到收敛。然后按照第一个解决的问题那样将超网拆划分为几个子超网,并使用从父超网传输的权重和架构分布参数初始化这些子超网。
接下来训练这些子超网收敛并选择子超网Ω′ 所有子超网的验证损失最低。最后选择了最好的架构分布参数。
对于基于搜索的算法,需要一个候选结构的值函数来指导搜索。值函数可以是不可微的,通常由单次或单次函数提供。对于vanilla NAS,不必严格地训练这些模型架构来收敛,可以使用提前停止的方法来获得中间结果。基于搜索的算法从几个初始的模型架构开始,基于前一个采样的体系结构和搜索算法在搜索空间中对下一个体系结构进行采样,直到找到一个性能满意的体系结构。
为了研究使用多个超级网络是否能够同时利用 one-shot NAS 和Vanilla NAS 的优势,他们设计了一个包含近1296个网络的搜索空间。
首先,他们对网络进行训练,根据 CIFAR10数据集上的实际准确度对网络进行排名。然后利用6个、36个和216个子超网预测了1296个网络。最后,他们将预测的排名与实际排名进行了比较。结果证明,即使只增加几个子超网,排名也有显著提高。
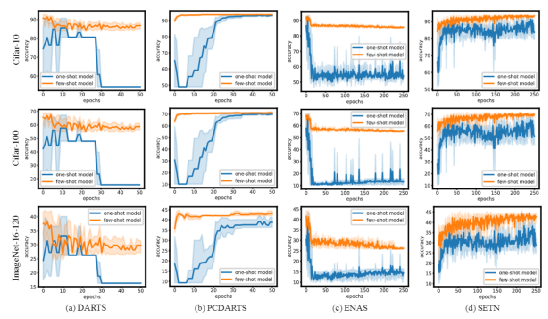
并且他们在真实世界的任务上测试了他们的想法,发现与one-shot NAS 相比,few-shot NAS 提高了模型架构评估的准确性。
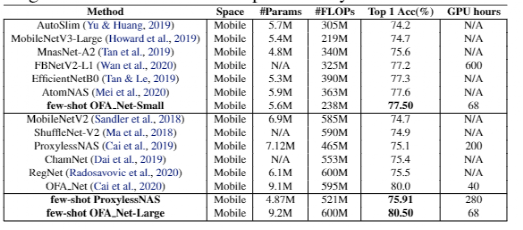
在 ImageNet 上,few-shot NAS 发现模型在600 MFLOPS 上达到近80.5% 的 top-1准确率,在238 MFLOPS 下达到77.5% 的 top-1准确率。
在 AutoGAN 中,few-shot NAS 的性能比以前的结果高出将近20% ,而在 CIFAR10中,它在不使用任何额外数据或传输学习的情况下达到了98.72% 的 top-1准确率。
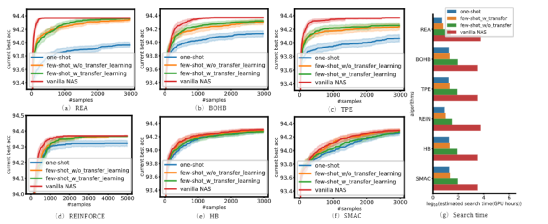
实验表明,few-shot NAS 可以显著地改进各种one-shot 方法,例如 NasBench-201和 NasBench1-shot-1中的四种基于梯度的方法和六种基于搜索的方法。
并且 few-shot NAS 相比one-shot NAS 能够极其有效地改善排名预测。此外,它还可以广泛适用于所有现有的 NAS 方法。当团队将这些场景作为具体的例子来展示时,他们开发的技术可以有广泛的应用,例如,当候选架构需要快速评估以寻找更好的架构时。
few-shot NAS 有助于设计准确和快速的模型。应用这种few-shot的方法可以提高使用超网络(如 AttentiveNAS 和 AlphaNet)的各种神经结构搜索算法的搜索效率。Facebook的研究团队希望他们的方法可以用在更广泛的场景中。
论文的通讯作者是导师郭甜,她是伍斯特理工学院计算机科学系的一名助理教授,也是 Cake Lab 的一名成员!她对设计系统机制和策略感兴趣,以处理新出现的应用程序在成本、性能和效率方面的平衡。具体来说,我参与过与云/边缘资源管理、大数据框架、深度学习推理、分布式训练、神经架构搜索和 AR/VR 相关的项目。最近的工作主要集中在改进深度学习的系统支持和深度学习在 AR/VR 中的实际应用。

第三作者是田渊栋,是Facebook AI Research (FAIR)的研究科学家和经理,主要研究兴趣是深度强化学习、表征学习和优化。他是 ELF OpenGo 项目的首席科学家和工程师。

参考资料:
https://www.reddit.com/r/MachineLearning/comments/op1ux8/r_facebook_ai_introduces_fewshot_nas_neural/
