
如何写优雅的SQL原生语句?


本文中讲解的内容
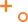
sql各语句执行顺序概览与讲解
项目实战中的一段sql说明讲解
sql语句中别名的使用
书写sql语句的注意事项
前言
上一篇讲Mysql基本架构时,以“sql查询语句在MySql架构中具体是怎么执行的?”进行了全面的讲解。知道了sql查询语句在MySql架构中的具体执行流程,但是为了能够更好更快的写出sql语句,我觉得非常有必要知道sql语句中各子句的执行顺序。看过上一篇文章的小伙伴应该都知道,sql语句最后各子句的执行应该是在执行器中完成的,存储引擎对执行器提供的数据读写接口。现在开始我们的学习
语句中各子句完整执行顺序概括(按照顺序号执行)
from (注:这里也包括from中的子语句)
join
on
where
group by(开始使用select中的别名,后面的语句中都可以使用)
avg,sum.... 等聚合函数
having
select
distinct
order by
limit
每个子句执行顺序分析
所有的 查询语句都是从from开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
1. from
form是一次查询语句的开端。
如果是一张表,会直接操作这张表;
如果这个from后面是一个子查询,会先执行子查询中的内容,子查询的结果也就是第一个虚拟表T1。(注意:子查询中的执行流程也是按照本篇文章讲的顺序哦)。
如果需要关联表,使用join,请看2,3
2. join
如果from后面是多张表,join关联,会首先对前两个表执行一个笛卡尔乘积,这时候就会生成第一个虚拟表T1(注意:这里会选择相对小的表作为基础表);
3. on
对虚表T1进行ON筛选,只有那些符合
4. where
对虚拟表T2进行WHERE条件过滤。只有符合
5.group by
group by 子句将中的唯一的值组合成为一组,得到虚拟表T4。如果应用了group by,那么后面的所有步骤都只能操作T4的列或者是执行6.聚合函数(count、sum、avg等)。(注意:原因在于分组后最终的结果集中只包含每个组中的一行。谨记,不然这里会出现很多问题,下面的代码误区会特别说。)
6. avg,sum.... 等聚合函数
聚合函数只是对分组的结果进行一些处理,拿到某些想要的聚合值,例如求和,统计数量等,并不生成虚拟表。
7. having
应用having筛选器,生成T5。HAVING子句主要和GROUP BY子句配合使用,having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
8. select
执行select操作,选择指定的列,插入到虚拟表T6中。
9. distinct
对T6中的记录进行去重。移除相同的行,产生虚拟表T7.(注意:事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。)
10. order by
应用order by子句。按照order_by_condition排序T7,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。
oder by的几点说明
因为order by返回值是游标,那么使用order by 子句查询不能应用于表表达式。
order by排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,
order by的两个参数 asc(升序排列) desc(降序排列)
11. limit
取出指定行的记录,产生虚拟表T9, 并将结果返回。
limit后面的参数可以是 一个limit m ,也可以是limit m n,表示从第m条到第n条数据。
(注意:很多开发人员喜欢使用该语句来解决分页问题。对于小数据,使用LIMIT子句没有任何问题,当数据量非常大的时候,使用LIMIT n, m是非常低效的。因为LIMIT的机制是每次都是从头开始扫描,如果需要从第60万行开始,读取3条数据,就需要先扫描定位到60万行,然后再进行读取,而扫描的过程是一个非常低效的过程。所以,对于大数据处理时,是非常有必要在应用层建立一定的缓存机制)
开发某需求写的一段sql
SELECT `userspk`.`avatar` AS `user_avatar`,
`a`.`user_id`,
`a`.`answer_record`,
MAX(`score`) AS `score`
FROM (select * from pkrecord order by score desc) as a
INNER JOIN `userspk` AS `userspk`
ON `a`.`user_id` = `userspk`.`user_id`
WHERE `a`.`status` = 1
AND `a`.`user_id` != 'm_6da5d9e0-4629-11e9-b5f7-694ced396953'
GROUP BY `user_id`
ORDER BY `a`.`score` DESC
LIMIT 9;
先简要说一下我要查询的内容:
想要查询pk记录表中分数最高的9个用户记录和他们的头像。
查询结果:

通过这段sql实际想一遍sql各字句的执行顺序
pk记录表的数据结构设计,每个用户每天每个馆下可能会有多条记录,所以需要进行分组,并且查询结果只想拿到每个分组内最高的那条记录。
这段sql的一些说明:
可能有些同学会认为子查询没有必要 直接查询pk记录表就可以,但是并不能拿到预期的结果,因为分组后的每个组结果是不进行排序的,而且max拿到的最高分数肯定是对应的该分组下最高分数,但是其它记录可能就不是最高分数对应的那条记录。所以子查询非常有必要,它能够对原始的数据首先进行排序,分数最高的那条就是第一条对应的第一条记录。
看一下代码和执行结果与带有子查询的进行比较,不带子查询的查询结果的确查到的最大分数与子查询的最大分数相同,但是根据id确认二者并不是同一条记录。看结果是不是就能理解我上面说的一段话
//不使用子查询
SELECT `userspk`.`avatar` AS `user_avatar`,
`pkrecord`.`user_id`,
`pkrecord`.`answer_record`,
`pkrecord`.`id`,
MAX(`score`) AS `score`
FROM pkrecord
INNER JOIN `userspk` AS `userspk`
ON `pkrecord`.`user_id` = `userspk`.`user_id`
WHERE `pkrecord`.`status` = 1
AND `pkrecord`.`user_id` != 'm_6da5d9e0-4629-11e9-b5f7-694ced396953'
GROUP BY `user_id`
ORDER BY `pkrecord`.`score` DESC
LIMIT 9;
查询结果:

2. 在子查询中对数据已经进行排序后,外层排序方式如果和子查询排序分数相同,都是分数倒序,外层的排序可以去掉,没有必要写两遍。
sql语句中的别名
别名在哪些情况使用
在 SQL 语句中,可以为表名称及字段(列)名称指定别名
表名称指定别名
同时查询两张表的数据的时候:未设置别名前:
SELECT article.title,article.content,user.username FROM article, user
WHERE article.aid=1 AND article.uid=user.uid
设置别名后:
SELECT a.title,a.content,u.username FROM article AS a, user AS u where a.aid=1 and a.uid=u.uid
好处:使用表别名查询,可以使 SQL 变得简洁而更易书写和阅读,尤其在 SQL 比较复杂的情况下
查询字段指定别名
查询一张表,直接对查询字段设置别名
SELECT username AS name,email FROM user
查询两张表
好处:字段别名一个明显的效果是可以自定义查询数据返回的字段名;当两张表有相同的字段需要都被查询出,使用别名可以完美的进行区分,避免冲突
ELECT a.title AS atitle,u.username,u.title AS utitle FROM article AS a, user AS u where a.uid=u.uid
关联查询时候,关联表自身的时候,一些分类表,必须使用别名。
别名也可以在group by与having的时候都可使用
别名可以在order by排序的时候被使用
查看上面一段sql
delete , update MySQL都可以使用别名,别名在多表(级联)删除尤为有用
delete t1,t2 from t_a t1 , t_b t2 where t1.id = t2.id
子查询结果需要使用别名
查看上面一段sql
别名使用注意事项
虽然定义字段别名的 AS 关键字可以省略,但是在使用别名时候,建议不要省略 AS 关键字
书写sql语句的注意事项
书写规范上的注意
字符串类型的要加单引号
select后面的每个字段要用逗号分隔,但是最后连着from的字段不要加逗号
使用子查询创建临时表的时候要使用别名,否则会报错。
为了增强性能的注意
不要使用“select * from ……”返回所有列,只检索需要的列,可避免后续因表结构变化导致的不必要的程序修改,还可降低额外消耗的资源
不要检索已知的列
select user_id,name from User where user_id = ‘10000050’
使用可参数化的搜索条件,如=, >, >=, <, <=, between, in, is null以及like ‘
%’;尽量不要使用非参数化的负向查询,这将导致无法使用索引,如<>, !=, !>, !<, not in, not like, not exists, not between, is not null, like ‘% ’ 当需要验证是否有符合条件的记录时,使用exists,不要使用count(*),前者在第一个匹配记录处返回,后者需要遍历所有匹配记录
Where子句中列的顺序与需使用的索引顺序保持一致,不是所有数据库的优化器都能对此顺序进行优化,保持良好编程习惯(索引相关)
不要在where子句中对字段进行运算或函数(索引相关)
如where amount / 2 > 100,即使amount字段有索引,也无法使用,改成where amount > 100 * 2就可使用amount列上的索引
如where substring( Lastname, 1, 1) = ‘F’就无法使用Lastname列上的索引,而where Lastname like ‘F%’或者where Lastname >= ‘F’ and Lastname < ‘G’就可以
在有min、max、distinct、order by、group by操作的列上建索引,避免额外的排序开销(索引相关)
小心使用or操作,and操作中任何一个子句可使用索引都会提高查询性能,但是or条件中任何一个不能使用索引,都将导致查询性能下降,如where member_no = 1 or provider_no = 1,在member_no或provider_no任何一个字段上没有索引,都将导致表扫描或聚簇索引扫描(索引相关)
Between一般比in/or高效得多,如果能在between和in/or条件中选择,那么始终选择between条件,并用>=和<=条件组合替代between子句,因为不是所有数据库的优化器都能把between子句改写为>=和<=条件组合,如果不能改写将导致无法使用索引(索引相关)
调整join操作顺序以使性能最优,join操作是自顶向下的,尽量把结果集小的两个表关联放在前面,可提高性能。(join相关) 注意:索引和关联我会单独拿出来两篇文章进行详细讲解,在这个注意事项中只是简单提一下。

MySql基础架构(sql查询语句在MySql内部具体是怎么执行的?)

—————END—————
喜欢本文的朋友,欢迎关注公众号 达达前端,收看更多精彩内容
点个[在看],是对达达最大的支持!
