
最先进的图像分类算法:FixEfficientNet-L2
来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
FixEfficientNet 是一种结合了两种现有技术的技术:来自 Facebook AI 团队的 FixRes [2] 以及由 Google AI 研究团队首先提出的EfficientNet [3]。FixRes 是 Fix Resolution 的缩写形式,它尝试为用于训练时间的 RoC(分类区域)或用于测试时间的裁剪保持固定大小。EfficientNet 是 CNN 尺度的复合缩放,可提高准确性和效率。本文旨在解释这两种技术及其最新技术。
首先,Facebook AI 研究团队于 2020 年 4 月 20 日将 FixEfficientNet 与相应的论文一起展示 [1],并连续成为计算机视觉领域的一项任务。它是目前最先进的,在 ImageNet 数据集上有最好的结果,参数为 480M,top-1 准确率为 88.5%,top-5 准确率为 98.7%。
让我们更深入地研究一下,以更好地了解组合技术。
训练时间
在 Facebook AI 研究团队提出 FixRes 技术之前,最先进的技术是从图像中提取一个随机的像素方块。这被用作训练时间的 RoC 。(请注意,使用此技术会人为地增加数据量)。然后调整图像大小以获得固定大小(=裁剪)的图像。然后将其输入卷积神经网络 [2]。
RoC = 输入图像中的矩形/正方形
crop = 通过双线性插值重新缩放到特定分辨率的 RoC 像素
训练时间规模扩大
为了更好地了解 FixRes 的具体功能,让我们看一下数学。更改输入图像中 RoC 的大小会影响给定 CNN 的对象大小的分布。该对象在输入图像中的大小为 rxr 。如果 RoC 现在被缩放,它会改变 s 并且对象的大小现在将连续变为 rs x rs 。
对于增强,使用了 PyTorch 的 RandomResizedCrop。输入图像的大小为H x W,从中随机选择一个 RoC,然后将此 RoC 调整为裁剪大小。
输入图像 ( H x W ) 对输出裁剪的缩放比例可以由以下因素表示:
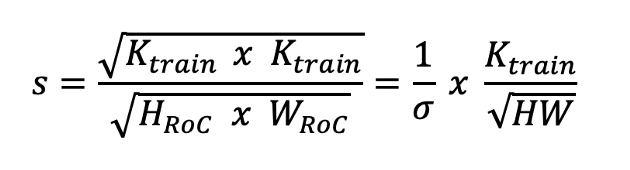
测试时间
在测试时,RoC 通常位于图像的中心,这会导致所谓的中心裁剪。两种裁剪(一种来自训练时间,另一种来自测试时间)具有相同的大小,但它们来自图像的不同部分,这通常会导致 CNN 的分布存在偏差 [2] 。
测试时间规模增加。
如前所述,测试增强与训练时间增强不同。这样,裁剪就有了大小。
关于输入图像是正方形 ( H=W ) 的假设,测试增强的比例因子可以表示为:
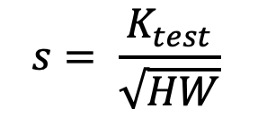
有什么发现?
在开发 FixRes 之前,测试和训练时间的预处理是彼此分开的,从而导致偏差。Facebook AI 团队不断尝试找到一种解决方案,该解决方案同时执行预处理并以某种方式同步,那就是 FixRes 。

如上所述的标准预处理通常会在训练时扩大 RoC,并在测试时减小 RoC 的大小。
FixRes 技术采用非此即彼的方法。它要么降低训练时间分辨率并保持测试裁剪的大小,要么增加测试时间分辨率并保持训练裁剪的大小。目的是检索相同大小的对象(此处是乌鸦),以减少 CNN 中的尺度不变性 [2] 。如下所示:

这会对数据输入 CNN 的方式产生两种影响:
图像中对象(此处是乌鸦)的大小通过 FixRes Scaling 进行更改。
使用不同的裁剪大小会影响神经元的激活方式和时间。
激活统计数据变化问题
Touvron 等人发现,更大的测试裁剪以及最重要的是对象尺寸的调整可以带来更好的准确性。然而,这需要在调整对象大小和更改激活统计数据之间进行权衡。
测试表明,激活图随着图像分辨率的变化而变化。K_test = 224 表示映射为 7x7,K_test = 64 表示映射为 2x2,而 K_test = 448 表示映射为 14x14。这表明激活分布在测试时会发生变化,并且这些值超出了分类器范围 [1]。
为了解决激活统计数据变化的问题,提出了两种解决方案:
参数适应:参数 Fréchet 分布用于拟合平均池化层。然后通过标量变换将新分布映射到旧分布,并作为激活函数应用。
微调:进行校正的另一种方法是对模型进行微调,微调仅应用于 CNN 的最后一层。
在微调阶段,使用标签平滑[1]。
作者预先训练了几个模型,其中 EfficientNet-L2 显示了最佳结果。但什么是 EfficientNet ?
与图像分类中的大多数算法一样,高效网络基于 CNN。CNN 具有三个维度:宽度、深度和分辨率。深度是层数,宽度是通道数(例如,传统的 RGB 将有 3 个通道),分辨率是图像的像素。
EfficientNets 引入了复合缩放,它利用了所有三个维度:
宽度缩放——宽度可以通过具有更多通道的图像来增加,但是准确度增益很快就会下降。
深度缩放——是传统且最典型的缩放方式。通过增加深度,可以增加神经网络的层数。但是添加更多层并不总是能提高网络的性能。大多数情况下它需要更多的时间,但由于梯度消失,性能可能会随着层数的增加而停滞甚至下降。
分辨率缩放——这意味着增加分辨率,从而增加像素数,例如从 200x200 到 600x600。这种缩放的问题在于精度增益随着分辨率的提高而消失。在一定程度上,精度可能会增加,但精度增量会减少。
所有三个维度的放大都会导致精度增量减小,并且为了获得最佳精度结果,必须对所有这三个维度进行平衡缩放。因此提出了复合缩放:
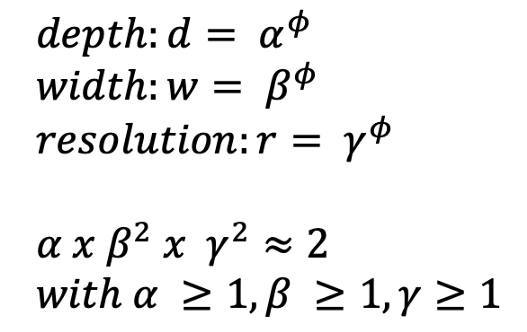
ɸ 指定可用资源,而 alpha、beta 和 gamma 负责分配这些资源。
Touvron 等人[1] , “ 使用神经架构搜索来开发新的基准网络,并对其放大以获得称为 EfficientNets 的一系列模型。” 神经架构搜索 (NAS) 优化了触发器和准确性。
这两种技术的结合使得目前最好的图像分类算法远远领先于 EfficientNet Noisy Student,它在效率和准确性方面都是当前领先的算法。由于其前五名的准确度为 98.7%,因此仍有改进的可能,但它已经相当准确了。因此,要等到这项技术被一种新技术所取代,还需要等待。
由于本文不包含任何实现,小伙伴们可以使用作者的官方 Github 自行尝试。
作者 [1] 的预训练网络如下所示:
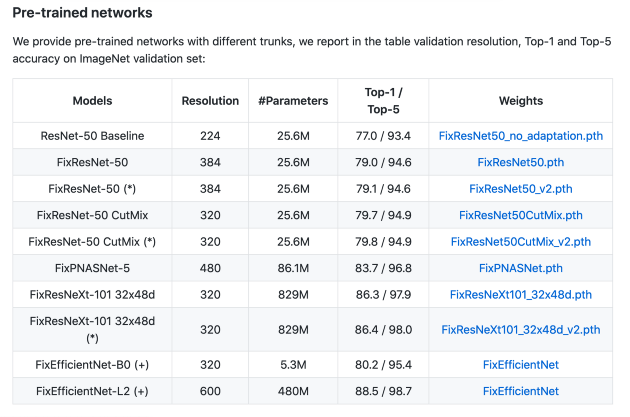
github 存储库的屏幕截图。
[1] Touvron, H.、Vedaldi, A.、Douze, M. 和 Jégou, H. (2020b)。修复训练测试分辨率差异:FixEfficientNet。ArXiv:2003.08237 [Cs]。http://arxiv.org/abs/2003.08237
[2] Touvron, H.、Vedaldi, A.、Douze, M. 和 Jégou, H.(2020a)。修复训练测试分辨率差异。ArXiv:1906.06423 [Cs]。http://arxiv.org/abs/1906.06423
[3] Tan, M., & Le, QV (2020)。EfficientNet:对卷积神经网络的模型放缩重新思考。ArXiv:1905.11946 [Cs,Stat]。http://arxiv.org/abs/1905.11946
Github代码连接:
http : //github.com/facebookresearch/FixRes。
本文仅做学术分享,如有侵权,请联系删文。