
HBase 原理 | HBase Compaction Offload 功能的实现与应用
文|牛豫林小米云平台工程师,Apache HBase Committer
导读
本文介绍了HBase Compaction Offload功能的设计与实现,以及在小米的应用。HBase Compaction操作会造成读写服务响应毛刺,我们通过引入CompactionServer组件,将Compaction任务剥离到CompactionServer上执行,避免与RegionServer产生资源竞争,优化读写毛刺。同时Compaction Offload功能加强存储计算分离,CompactionServer可以独立于RegionServer进行扩缩容,便于云原生容器化部署。
背景
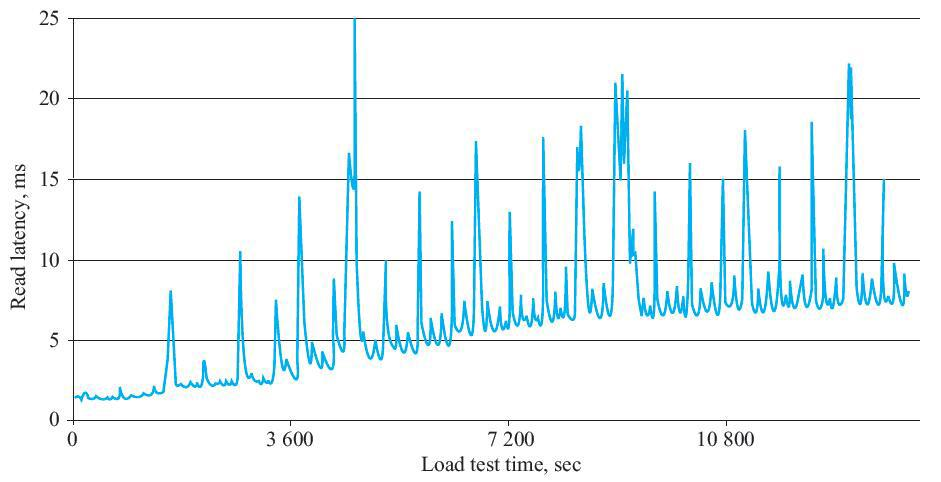
HBase是基于LSM-Tree架构的分布式数据库,对于数据写入不会原地更新,而是在内存(Memtable)中创建更新键的新值,然后定期将内存中的数据刷新为只读的存储文件(HFile),读取数据就需要遍历多个文件找到该键所对应的正确值。随着存储文件不断增加,读性能会因为需要读取的文件数增多而下降(如图.1所示)。HBase会执行Compaction操作将多个文件合并,使文件个数基本稳定,进而使读取IO的次数趋于稳定,将延迟控制在一定范围内(图.2)。在现有HBase架构中,Compaction操作在RegionServer上执行,合并文件会带来很大的带宽以及IO压力,同时也会消耗CPU和内存资源,造成读取响应延迟增大,出现毛刺。
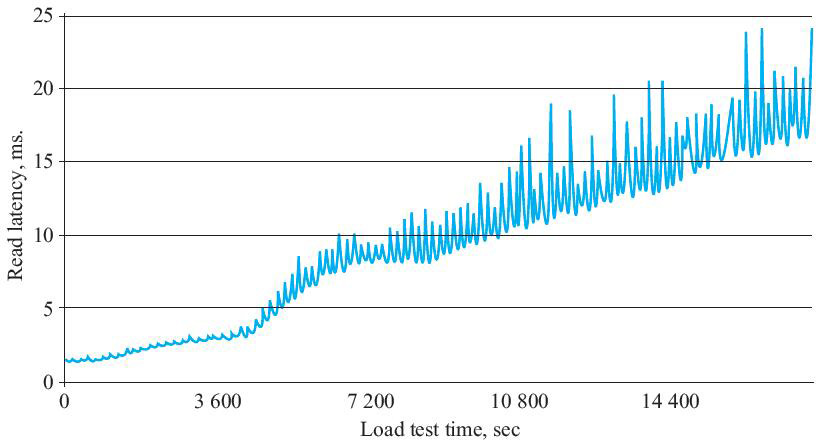
图.1 读取延时随数据写入时间增加而不断增加
目前Compaction相关逻辑都是在RegionServer中执行的,如图.3所示。
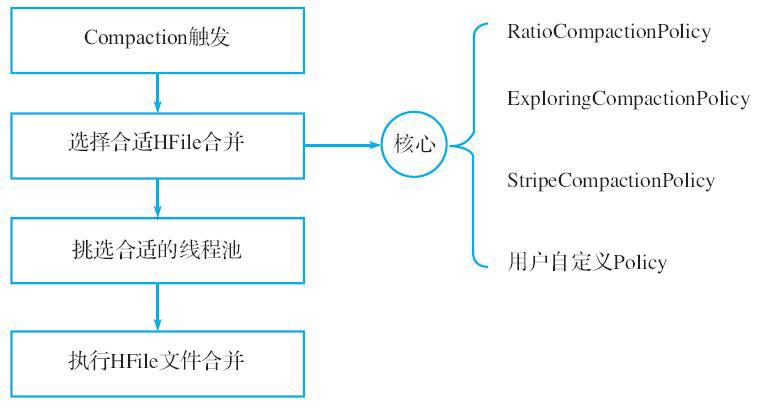
图.3 Compaction执行流程
Compaction的执行流程可以分解为多个子流程:
1、触发条件:Flush、Open Region、CompactionCheckerChore、Admin操作
2、执行Compaction
根据Compaction策略选择要合并的文件
选择合适的线程池,执行Compact
3、完成Compaction
将Compact产生的新文件从tmp目录移动到Region相应目录,并加载新文件
将参与Compact的输入文件标记为Compacted
CompactedHFilesDischarger线程定期扫描并删除Compacted文件
Compaction Offload功能将步骤2中的部分从RegionServer中移出,在CompactionServer上执行。
整体架构变化
引入新的组件CompactionServer(以下简写为CS),将Compaction任务从RegionServer中剥离出来。新的HBase架构包含组件为:Master、RegionServer、CompactionServer。同时为了管理CS,在Master中增加CompactionServer Manager(以下简写为CS Manager)模块,如图.4 所示。
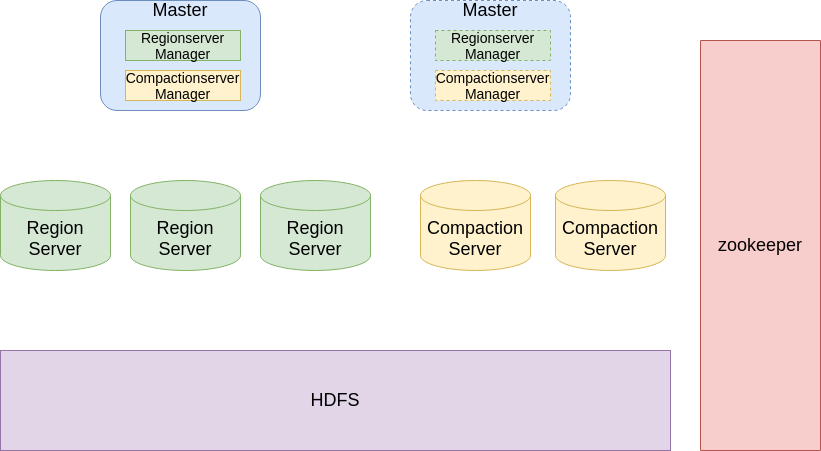
图.4 HBase新整体架构
CompactionServer可以代替RegionServer执行Compaction操作,它使用HDFS Client与HDFS进行交互,从HDFS中读取需要执行Compaction文件的内容,并将Compaction产生的新文件写入HDFS。CompactionServer是无状态的,易于扩展。CS Manager管理CS并维护Region到CS的映射,使每个CS执行某些Regoin的Compaction操作,这类似于Master将Region分配给RegionServer提供读写服务。
在实现CS和CS Manager的过程中,我们复用了RegionServer和RegionServerManager的代码,例如从HDFS中Scan Storefile以及对这些文件执行Compaction并写回HDFS,同时对于Compaction的核心—Compaction策略,我们将其视为黑盒,保持原先的执行逻辑,不做修改。
新的架构可以带来如下好处:
1、CompactionServer可以部署在独立机器上,不与RegionServer产生资源竞争,优化读写毛刺。
2、加强存储计算资源分离,将RegionServer计算任务进一步分离到多个Server上,CS可以独立于RegionServer进行扩缩容,便于容器化部署。
3、有了中心化的CS Manager, Master可以对Compaction任务进行整体限速。
Compaction逻辑的变化
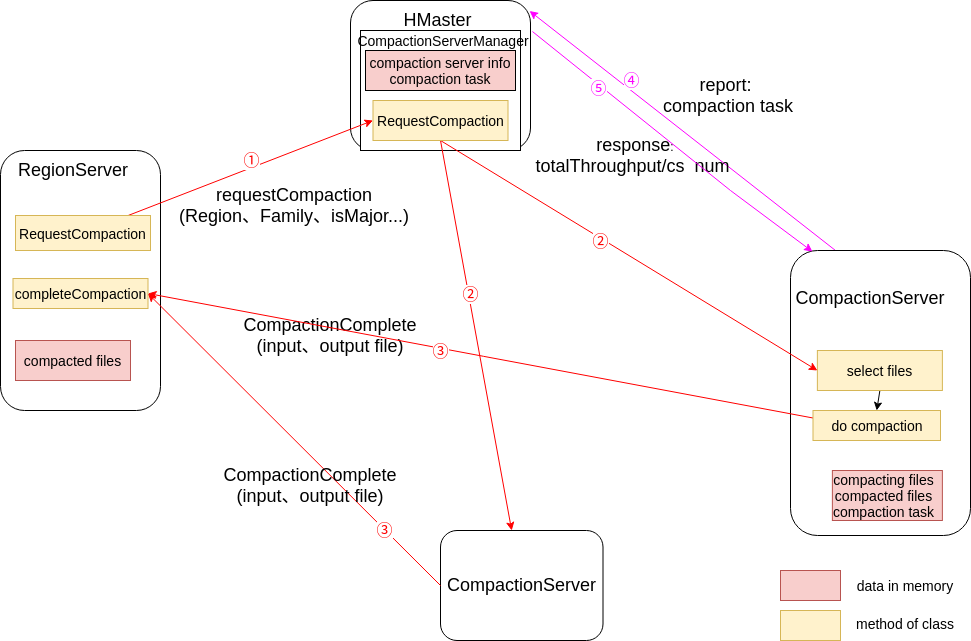
图.5 CompactionOffload模块交互图
增加CompactionServer后,执行Compaction时各模块功能发生变化:
1、RegionServer
需要执行Compaction时,发送Request Compaction请求到Master,请求中携带Region、Family等信息(图.5中①)。
接受CS的CompactionComplete请求(图.5中③),然后进行原先的逻辑(Compaction现有逻辑中3)。
2、Master
新增类CompactionServerManager,用来管理CS以及转发Compaction请求。
接受RegionServer的Request Compaction请求,并转发给相应CS,这里同一个Region的请求会转发到同一个CS(图.5中②)。
响应CS的心跳请求,返回对CS的限速信息(图.5中⑤)。
页面展示CS列表以及Compaction Task汇总信息。
3、CompactionServer
接受Master转发来的Request Compaction请求,执行选择文件和Compact逻辑(Compaction现有逻辑中2)。
发送CompleteCompaction请求给相应的Regionserver,请求参数包括参与执行Compaction的文件列表和Compaction生成文件列表(图.5中③)。
给Master发送心跳并汇报Compaction Task信息(图.5中④)。
获取Master的汇报答复,其中包含限速信息,对Compaction任务进行限速调整。
Compaction Offload功能开关
集群级别:在HBase Shell中执行enable_compaction_offload/disable_compaction_offload命令开启或关闭整集群Compaction Offload功能。
表级别:创建/修改表时设置表的COMPACTION_OFFLOAD_ENABLED的属性为true或false。
只有集群和表级别开关同时开启,才会执行Compaction Offload逻辑。
Compaction Offload功能Failover
1、Master宕机 RegionServer请求Master失败,会回退到原先的本地执行Compaction方式。
对于已经在CS执行完毕的Compaction任务,会直接请求RegionServer(图.5中③),不会受到Master不可用的影响。
2、CompactionServer宕机 CS宕机后,CS Manager会将请求发送到其他可用的CS,若全部CS都不可用,RegionServer会回退到本地执行Compaction的方式。
3、RegionServer宕机或Region移动 在CS执行完Compaction并请求RegionServer时(图.5中③),若发生RegionServer宕机或Region移动,我们会等待Region重新Online,从Master中获取Region最新所在RegionServer,然后重试Compaction Complete请求。
Compaction Offload功能兼容性
1、FavoredNodes/Locality 若某个Region开启了FavoredNodes特性,CompactionOffload功能会进行兼容,在文件写回HDFS时使用FavoredNodes特性,保证Compaction生成的文件副本在指定DataNode列表上。
若未开启FavoredNodes特性,会将发送RequestCompaction请求的RegionServer地址设置为HStore的FavoredNodes,在写回HDFS时写入RegionServer所在机器的DataNode,保证Locality。若RegionServer所在机器未部署DataNode,则会随机选择DataNode进行写入。
2、MOB CompactionServer在执行Compaction时会创建HStore对象,复用Compaction逻辑。若RequestCompaction请求中Family是开启MOB特性的,我们会创建HMobStore,从而兼容MOB Compaction。
3、RegionCoprocessor HBase用户通过定制Coprocessor可以在Compaction操作过程中执行自定义逻辑,Compaction Offload功能需要兼容Coprocessor保证Compaction的语义正确。我们引入RegionCoprocessorService接口,使Region可以在CompactionServer上打开时挂载Compaction相关的Coprocessor。
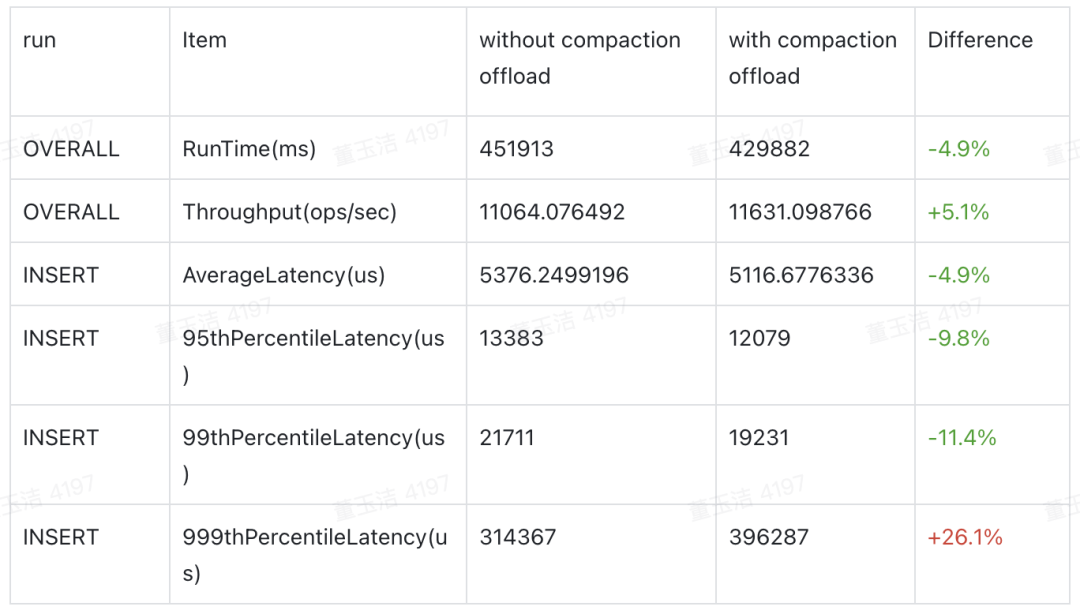
YCSB测试
RegionServer:Num = 2、 MaxHeap = 25g、MaxDirectMem = 25g、HDD
CompactionServer:Num = 1、MaxHeap = 25g、HDD
5M Records and Operations
Wordload A
Wordload B
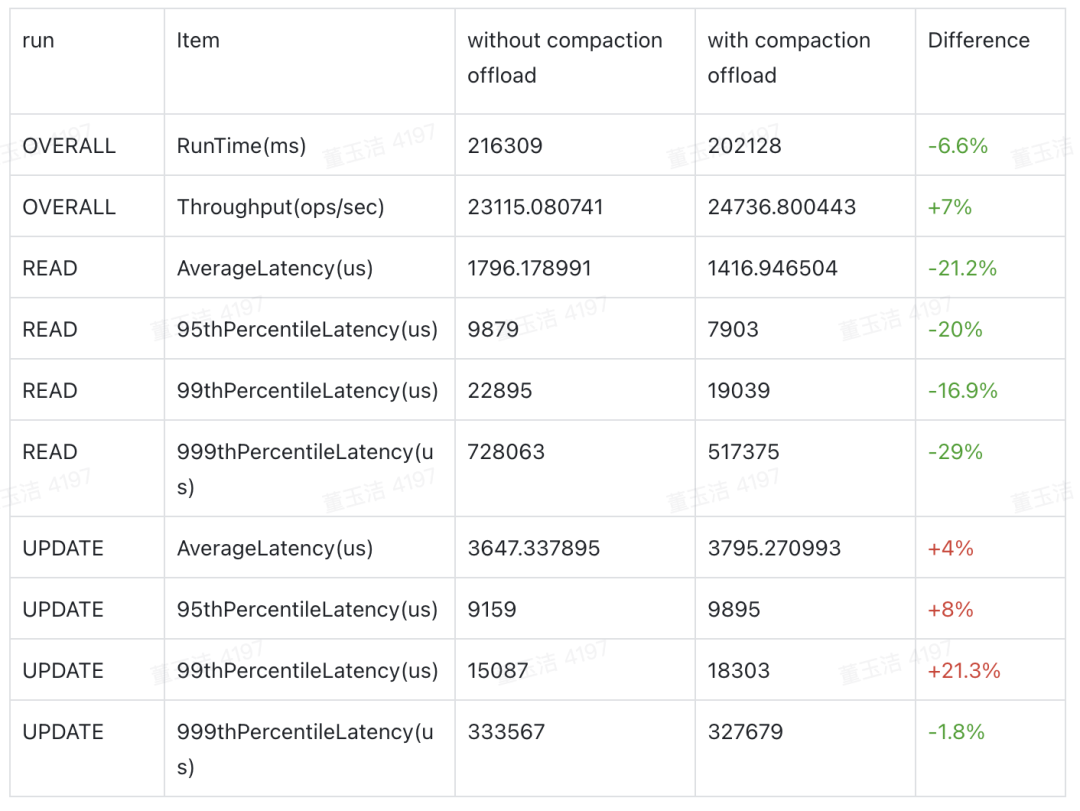
YCSB测试表明,开启Compaction Offload对吞吐和P99延迟有10%左右提升。
上线效果
小米推送集群:60个RegionServer节点,单节点128G内存、10T SSD。单机读/写QPS均值:40k/2.5k;单机读/写QPS峰值:90k/10k。
我们在该集群上线Compaction Offload功能,将5个RegionServer服务器替换为部署CS,每个服务器部署4个CS。上线时间为7月18日,我们分别截取了服务端和客户端对访问延时的监控如图6、7、8所示。发现开启Compaction Offload功能可以显著降低P99延时,但是对于平均延迟和P999优化效果不明显。
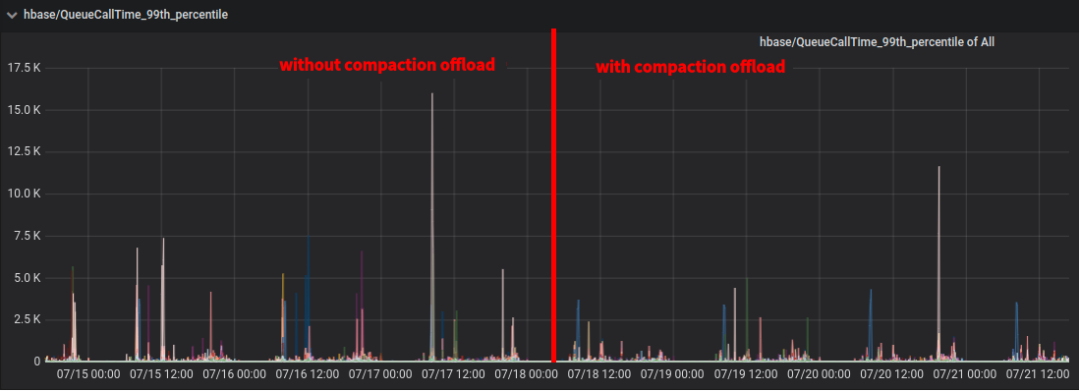
图.6 HBase服务侧监控:请求排队时间(P99)
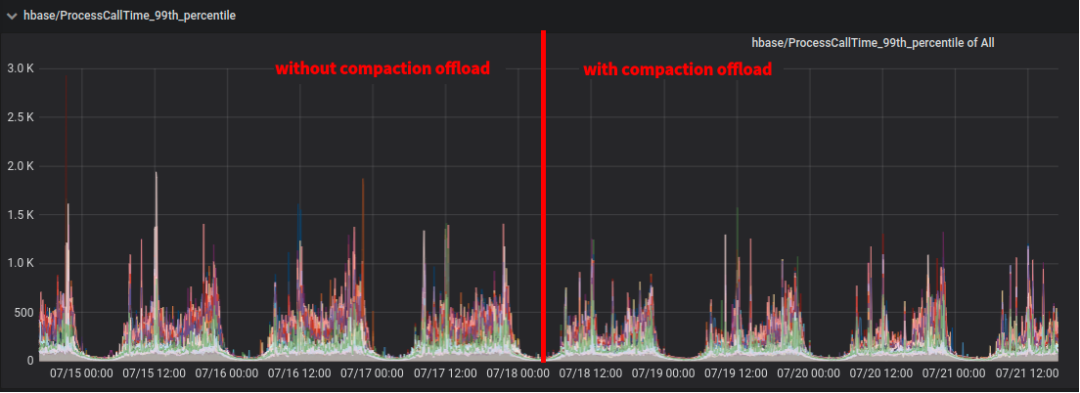
图.7 HBase服务侧监控:请求处理时间(P99)
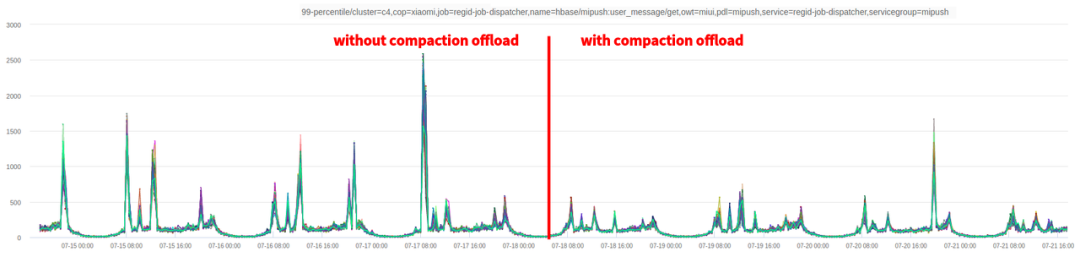
图.8 业务侧监控:Get请求HBase集群耗时(P99)
Compaction Offload功能同步到社区
目前Compaction Offload功能在小米内部分支开发完毕,正在同步到社区,参考HBASE-25714。
支持异构Compaction Offload功能
目前Compaction Offload功能只能在CS上执行,后续可以考虑将Compaction提交到YARN上执行,获得更高的资源利用率。由于Minor Compaction对实时性有较高要求,可以使用Spark Streaming或者Flink计算框架对Compaction任务进行处理。
CompactionServer支持BlockCache
图.2 Compaction任务造成读写毛刺不仅仅是因为其与RegionServer产生资源竞争,另一个原因是Compaction结束时替换文件造成RegionServer BlockCache失效,这时需要重新从HDFS读取文件并加载到BlockCache,Compaction Offload功能目前只能解决Compaction任务与RegionServer资源竞争的问题。我们计划在CS中引入BlockCache,在Compaction执行过程中缓存需要的HFile Block,当Compaction任务结束替换文件后,RegionServer可以从CS的BlockCache中读取相应Block,减轻读文件造成的延时毛刺。
https://issues.apache.org/jira/browse/HBASE-25714
http://www.vldb.org/pvldb/vol8/p850-ahmad.pdf
https://hbase.apache.org/book.html
《HBase原理与实践》
喜欢此内容的人还喜欢
【Doris全面解析】Doris SQL 原理解析
 米家插件平台的技术实践之路日志异常检测初步实践与探索基于chaosblade的故障注入平台实践
米家插件平台的技术实践之路日志异常检测初步实践与探索基于chaosblade的故障注入平台实践