
1.3 万亿条数据查询,如何做到毫秒级响应?
共 5798字,需浏览 12分钟
·
2022-01-23 23:53
知乎,在古典中文中意为“你知道吗?”,它是中国的 Quora,一个问答网站,其中各种问题由用户社区创建,回答,编辑和组织。
作为中国最大的知识共享平台,我们目前拥有 2.2 亿注册用户,3000 万个问题,网站答案超过 1.3 亿。
随着用户群的增长,我们的应用程序的数据大小无法实现。我们的 Moneta 应用程序中存储了大约 1.3 万亿行数据(存储用户已经阅读过的帖子)。
由于每月累计产生大约 1000 亿行数据且不断增长,这一数字将在两年内达到 3 万亿。在保持良好用户体验的同时,我们在扩展后端方面面临严峻挑战。
在这篇文章中,我将深入探讨如何在如此大量的数据上保持毫秒级的查询响应时间,以及 TiDB 是一个开源的 MySQL 兼容的 NewSQL 混合事务/分析处理( HTAP)数据库,如何为我们提供支持获得对我们数据的实时洞察。
我将介绍为什么我们选择 TiDB,我们如何使用它,我们学到了什么,优秀实践以及对未来的一些想法。
| 我们的痛点
系统架构要求
Moneta 应用程序具有以下特征:
需要高可用性数据:Post Feed 是第一个出现的屏幕,它在推动用户流量到知乎方面发挥着重要作用。 处理巨大的写入数据:例如,在高峰时间每秒写入超过 4 万条记录,记录数量每天增加近 30 亿条记录。 长期存储历史数据:目前,系统中存储了大约 1.3 万亿条记录。随着每月累积约 1000 亿条记录并且不断增长,历史数据将在大约两年内达到 3 万亿条记录。 处理高吞吐量查询:在高峰时间,系统处理平均每秒在 1200 万个帖子上执行的查询。 将查询的响应时间限制为 90 毫秒或更短:即使对于执行时间最长的长尾查询,也会发生这种情况。 容忍误报:这意味着系统可以为用户调出许多有趣的帖子,即使有些帖子被错误地过滤掉了。
考虑到上述事实,我们需要一个具有以下功能的应用程序架构:
高可用性:当用户打开知乎的推荐页面时,找到大量已经阅读过的帖子是一种糟糕的用户体验。 出色的系统性能:我们的应用具有高吞吐量和严格的响应时间要求。 易于扩展:随着业务的发展和应用程序的发展,我们希望我们的系统可以轻松扩展。
勘探
代理:这会将用户的请求转发给可用节点,并确保系统的高可用性。 缓存:这暂时处理内存中的请求,因此我们并不总是需要处理数据库中的请求。这可以提高系统性能。 存储:在使用 TiDB 之前,我们在独立的 MySQL 上管理我们的业务数据。随着数据量的激增,独立的 MySQL 系统还不够。 然后我们采用了 MySQL 分片和 Master High Availability Manager( MHA)的解决方案,但是当每月有 1000 亿条新记录涌入我们的数据库时,这个解决方案是不可取的。
MySQL Sharding 和 MHA 的缺点
MySQL 分片的缺点:
应用程序代码变得复杂且难以维护。 更改现有的分片键很麻烦。 升级应用程序逻辑会影响应用程序的可用性。
MHA 的缺点:
我们需要通过编写脚本或使用第三方工具来实现虚拟 IP(VIP)配置。 MHA 仅监视主数据库。 要配置 MHA,我们需要配置无密码安全 Shell( SSH)。这可能会导致潜在的安全风险。 MHA 不为从属服务器提供读取负载平衡功能。 MHA 只能监视主服务器(而不是从主服务器)是否可用。
| 什么是 TiDB?
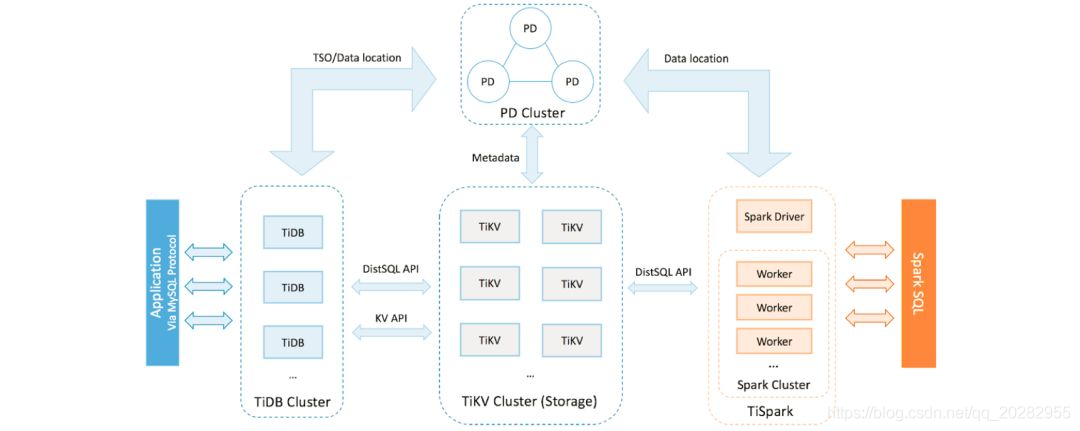
在 TiDB 平台内部,主要组件如下:
TiDB 服务器是一个无状态的 SQL 层,它处理用户的 SQL 查询,访问存储层中的数据,并将相应的结果返回给应用程序。它与 MySQL 兼容并且位于 TiKV 之上。另外搜索公众号互联网架构师回复关键字"2T”获取一份惊喜礼包。 TiKV 服务器是数据持久存在的分布式事务键值存储层。它使用 Raft 共识协议进行复制,以确保强大的数据一致性和高可用性。 TiSpark 集群也位于 TiKV 之上。它是一个 Apache Spark 插件,可与 TiDB 平台配合使用,支持商业智能(BI)分析师和数据科学家的复杂在线分析处理(OLAP)查询。 放置驱动程序(PD)服务器是由 etcd 支持的元数据集群,用于管理和调度 TiKV。
TiDB 的主要功能包括:
水平可扩展性。 MySQL 兼容的语法。 具有强一致性的分布式事务。 云原生架构。 使用 HTAP 进行最小提取,转换,加载( ETL)。 容错和 Raft 恢复。 在线架构更改。
| 我们如何使用 TiDB
我们架构中的 TiDB
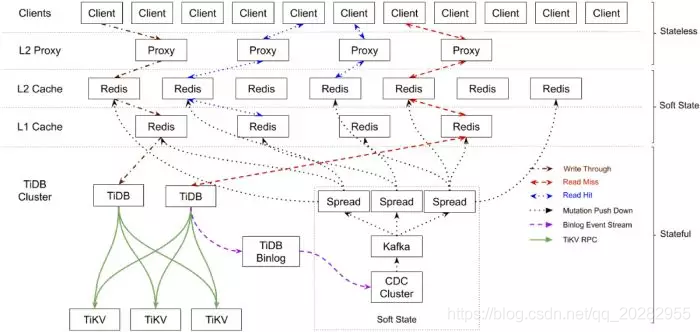
我们在系统中部署了 TiDB,Moneta 应用程序的整体架构变为:
顶层:无状态和可伸缩的客户端 API 和代理。这些组件易于扩展。 中间层:软状态组件和分层 Redis 缓存作为主要部分。当服务中断时,这些组件可以通过恢复保存在 TiDB 群集中的数据来自我恢复服务。 底层:TiDB 集群存储所有有状态数据。它的组件高度可用,如果节点崩溃,它可以自我恢复其服务。
TiDB 的性能指标


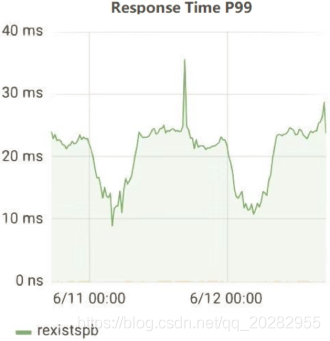

| 我们学到了什么
更快地导入数据
减少查询延迟
在此过程中,我们积累了宝贵的数据和数据处理知识:
有些查询对查询延迟很敏感,有些则不然。我们部署了一个单独的 TiDB 数据库来处理对延迟敏感的查询。(其他非延迟敏感的查询在不同的 TiDB 数据库中处理。) 这样,大型查询和对延迟敏感的查询在不同的数据库中处理,前者的执行不会影响后者。 对于没有理想执行计划的查询,我们编写了 SQL 提示来帮助执行引擎选择最佳执行计划。 我们使用低精度时间戳 Oracle( TSO)和预处理语句来减少网络往返。
评估资源
| 对 TiDB 3.0 的期望
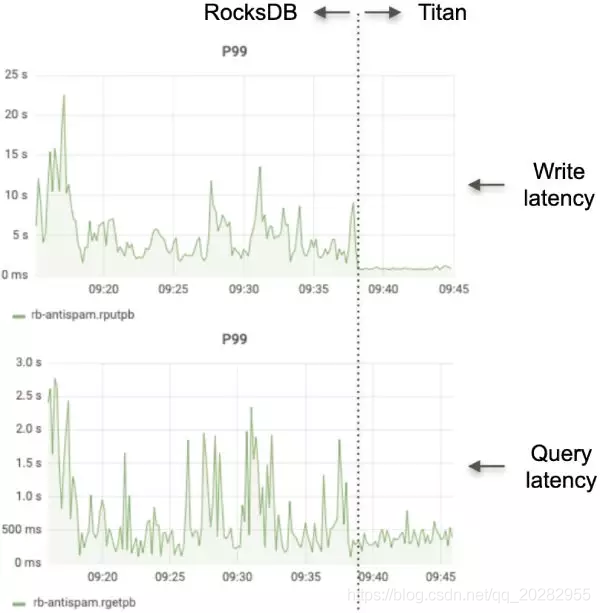
下图分别显示了与 RocksDB 和 Titan 相比的写入和查询延迟:
④gRPC 和多线程 Raftstore 中的批处理消息
⑤SQL 计划管理
⑥TiFlash
⑦反垃圾邮件应用程序中的 TiDB 3.0
| 下一步是什么
我们决定参与开发开源工具,并参与社区的长期发展。基于我们与 PingCAP 的共同努力,TiDB 将变得更加强大。