
详解 XGBoost 2.0重大更新!
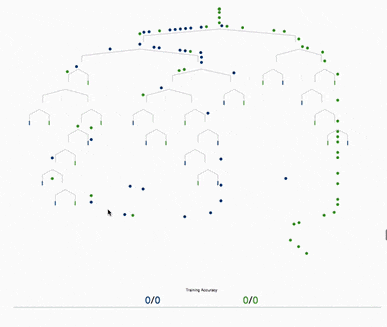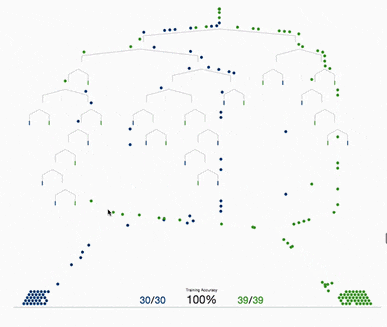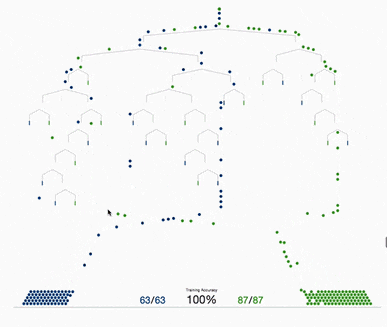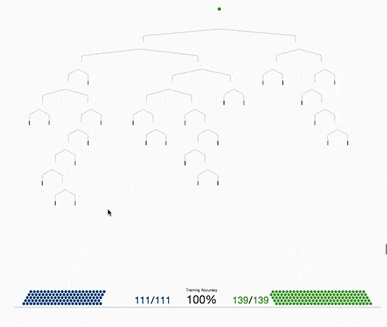
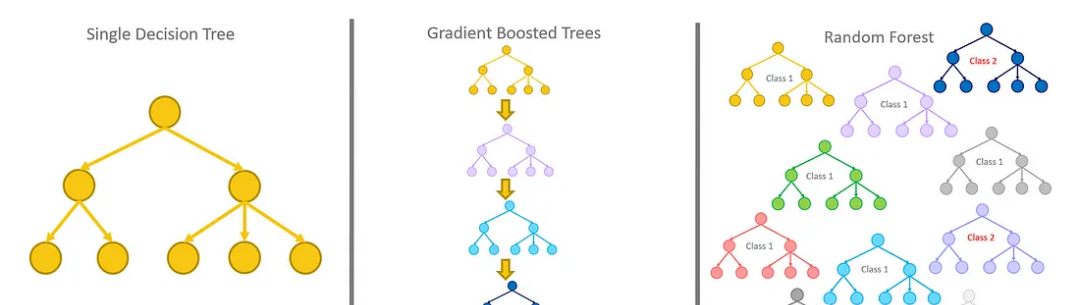
决策树
损失函数
基尼系数
基尼指数还是信息增益?
过拟合和修剪
-
分割:随着树的增长,持续监控它在验证数据集上的性能。如果性能开始下降,这是停止生长树的信号。 -
后修剪:在树完全生长后,修剪不能提供太多预测能力的节点。这通常是通过删除节点并检查它是否会降低验证准确性来完成的。如果不是则修剪节点。
随机森林

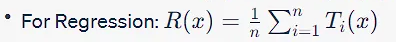
过拟合和Bagging
梯度增强决策树
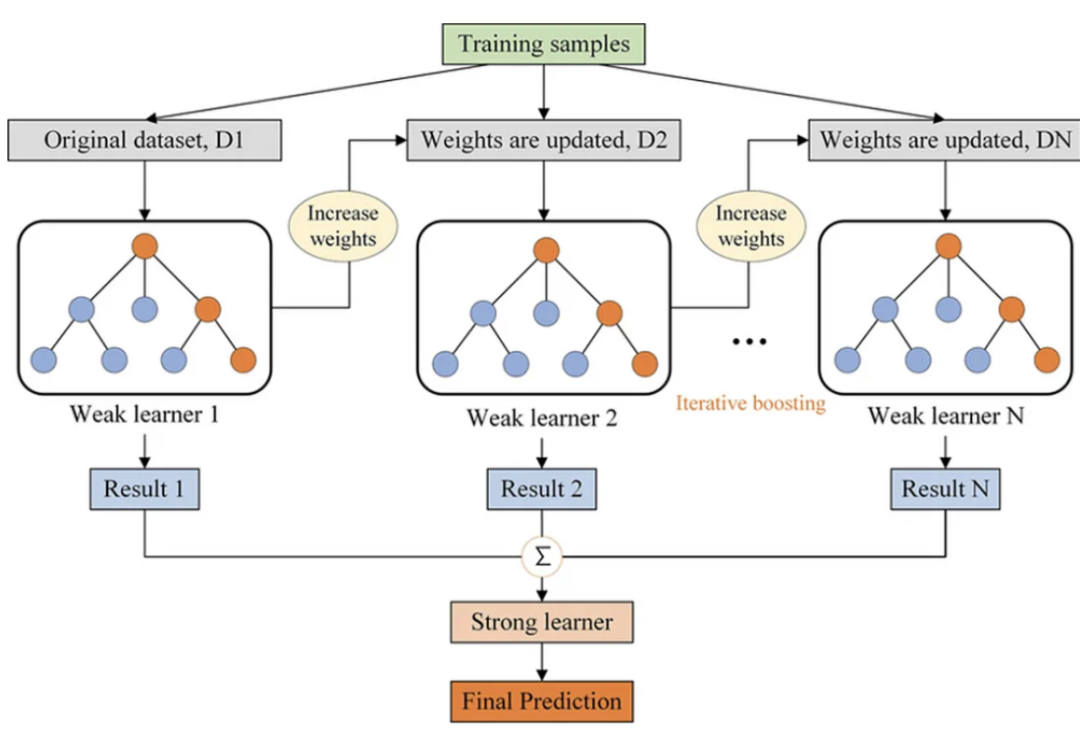
为什么它比决策树和随机森林更好?
-
减少过拟合:与随机森林一样,GBDT也避免过拟合,但它是通过构建浅树(弱学习器)和优化损失函数来实现的,而不是通过平均或投票。 高效率:GBDT专注于难以分类的实例,更多地适应数据集的问题区域。这可以使它在分类性能方面比随机森林更有效,因为随机森林对所有实例都一视同仁。
优化损失函数:与启发式方法(如基尼指数或信息增益)不同,GBDT中的损失函数在训练期间进行了优化,允许更精确地拟合数据。
更好的性能:当选择正确的超参数时,GBDT通常优于随机森林,特别是在需要非常精确的模型并且计算成本不是主要关注点的情况下。
灵活性:GBDT既可以用于分类任务,也可以用于回归任务,而且它更容易优化,因为您可以直接最小化损失函数。
梯度增强决策树解决的问题
XGBoost

计算效率
缺失数据的处理
正则化
稀疏性
硬件的优化
特征重要性和模型可解释性
早停策略
处理分类变量
XGBoost 2.0有什么新功能?
具有矢量叶输出的多目标树
设备参数
Hist作为默认树方法
基于gpu的近似树方法
内存和缓存优化
Learning-to-Rank增强
新的分位数回归支持
总结
评论