
你还在手动部署埋点吗?从0到1开发Babel埋点自动植入插件!
前言
本文由网易的 Pluto Lam 大神投稿,授权本公众号发表。
在各种大型项目中,流量统计是一项重要工程,统计点击量可以在后端进行监控,但是这局限于调用接口时才能统计到用户点击,而前端埋点监控也是一个统计流量的手段,下面就基于百度统计来完成以下需求
在 html页面中插入特定的script标签,src为可选值在全局 window植入可选的函数解析特定格式的 excel表,里面包含埋点的id和参数值(传递给上面的函数)找到项目中所有带有表示的行级注释,并将其替换成执行 2中函数的可执行语句,并传入excel表对应的参数
可能有些读者看到这里就有点蒙了,这到底是个啥,别急,跟着我一步一步做下去就清楚了,接下来我会以一个babel初学者的身份带你边学边做
那就让我们从最难搞定的最后一步开始,这也是比较麻烦的babel操作
babel前置知识
很多读者估计知识配置过babel,但是并不知道它具体是干啥事的,只是依稀记得AST抽象语法树、深度优先遍历、babel-loader等词语
在我们日常的开发中,确实是使用babel-loader比较多,这是babel为webpack开发的一个插件,如果没有任何配置,它将不会对代码做任何修改,只是遍历AST,在webpack构建阶段收集依赖并生成module,我们比较常用的是将ES6转为ES5,只需在preset使用babel官方提供的相关即可,在这就不赘述。
在babel进行深度优先遍历时,会调用我们配置好的plugin,在不同的plugin里面都可以对遍历过程进行监听和操作。
{
"presets": [
"@babel/preset-env" // 提供ES6转ES5功能
],
"plugins": [
"xxx-plugin"
]
}
既然是初学者,那就先来搭建测试环境吧,下面都是使用yarn装包
测试环境
创建一个空文件,执行命令npm init -y,如下图创建文件
测试环境在test文件中,index.js中可以放主要的测试代码
// test/index.js
class App {
}
安装webpack,由于我们的webpack和webpack-cli只有开发时测试会用到,所以加上-D,表示开发依赖
yarn add webpack webpack-cli -D
配置好webpack.config.js
const path = require("path");
module.exports = {
mode: "development", // 开发模式
entry: {
main: path.resolve(__dirname, "./index.js") // 入口文件
},
output: {
filename: "main.js",
path: path.resolve(__dirname, "./dist") // 出口文件
}
}
在/package.json里配置打包命令
// package.json
"scripts": {
"dev": "webpack --config test/webpack.config.js" // 指向test目录下的配置文件
},
运行yarn dev即打包,此时会出现/test/dist/main.js文件,里面为打包好的代码,babel plugin处理过的代码可以在这里校验是否正确
确保可以运行后,安装babel-loader、@babel/core和@babel/preset-env,添加如下配置
@babel/core里面包含babel的常用方法,其中babel-loader和@babel/preset-env都是依赖于@babel/core的
const path = require("path");
module.exports = {
...
module: {
rules: [
{
test: /.js$/,
exclude: /node_modules/,
loader: "babel-loader",
options: {
presets: [
"@babel/preset-env"
]
}
}
]
}
};
yarn dev后可以看看main.js,如果class被转为ES5语法表示,则babel-loader是配置成功的
接下来就可以配置插件了,在options里添加plugins,通过path.resolve()生成绝对路径, 指向/src/index.js
options: {
presets: [
"@babel/preset-env"
],
plugins: [
[
path.resolve(__dirname, "../src/index.js"),
]
]
}
在/src/index.js里写plugin相关代码
module.exports = function() {
return {
visitor: {
Program: {
enter(path) {
console.log("enter");
},
exit(path) {
console.log("exit");
}
},
FunctionDeclaration(path, state){
...
}
}
};
};
babel-plugin在基本结构如上,导出一个函数,函数里面返回一个对象,对象里面就是plugin的相关配置。
我们这个插件主要使用visitor(访问者),顾名思义,在AST遍历时,我们能访问到遍历时访问的每个节点,在visitor里面,我们可以将节点类型抽象成方法,简单点说,只要访问到这种类型的节点,就会执行对应的方法,而且会传入两个参数,其中path表示改节点的路径,可以对该节点进行操作,state是一个全局的变量,从进入visitor开始就存在,里面常用的东西不多,稍后再说。
AST节点
节点的类型非常之多,下面只介绍一些需要用到的,如果有需要可以访问AST node types进行学习。
Programs
官方的解释是这样的
A complete program source tree.
Parsers must specify sourceType as "module" if the source has been parsed as an ES6 module. Otherwise, sourceType must be "script".
通俗点来说,它就是抽象树的最顶端的节点,里面包含整棵树,遍历开始与结束时分别会进入enter方法和exit方法,这样单纯用文字描述读者可能还对抽象树的结构云里雾里,下面我们通过一个网站和控制台打印来看一下具体的节点长什么样
我们可以访问https://astexplorer.net/这个网址,在左边输入想要解析的代码,右边就会对应的AST树,不过这个树有点删减,要详细一点的树可以点击“JSON”查看JSON格式的AST树
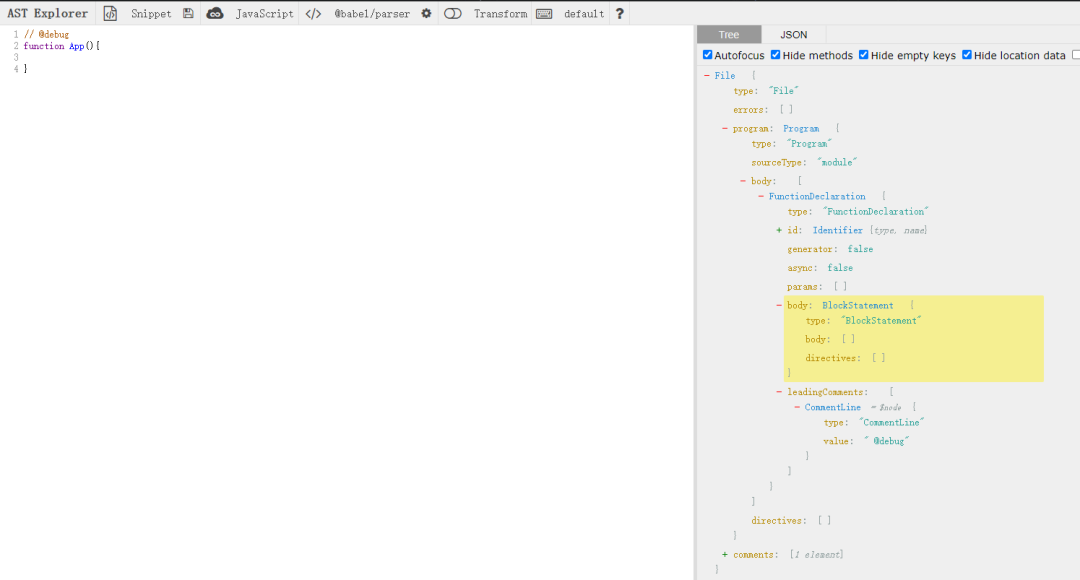
我将JSON去除一些目前不需要用到的属性展示出来
{
"type": "File",
"start": 0,
"end": 30,
"loc": {...},
"errors": [],
"program": {
"type": "Program",
"start": 0,
"end": 30,
"loc": {...},
"sourceType": "module",
"interpreter": null,
"body": [
{
"type": "FunctionDeclaration",
"start": 10,
"end": 30,
"loc": {...},
"id": {...},
"generator": false,
"async": false,
"params": [],
"body": {...},
"leadingComments": [
{
"type": "CommentLine",
"value": " @debug",
"start": 0,
"end": 9,
"loc": {...}
}
]
}
],
"directives": []
},
"comments": [
{
"type": "CommentLine",
"value": " @debug",
"start": 0,
"end": 9,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 9
}
}
}
]
}
可以看到有很多很多属性,但是我们不能拿这个来开发,只能作为参考,要真正操作节点还是需要在控制台打印或者debug查看AST的结构,下面我将控制台打印的节点结构删减后帖出来,可以和上面对比一下。
NodePath {
contexts: [
TraversalContext {
queue: [Array],
priorityQueue: [],
parentPath: undefined,
scope: [Scope],
state: undefined,
opts: [Object]
}
],
state: undefined,
opts: {
Program: { enter: [Array], exit: [Array] },
_exploded: {},
_verified: {},
ClassBody: { enter: [Array] },
...
},
_traverseFlags: 0,
skipKeys: null,
parentPath: null,
container: Node {
type: 'File',
start: 0,
end: 16,
loc: SourceLocation {
start: [Position],
end: [Position],
filename: undefined,
identifierName: undefined
},
errors: [],
program: Node {
type: 'Program',
start: 0,
end: 16,
loc: [SourceLocation],
sourceType: 'module',
interpreter: null,
body: [Array],
directives: [],
leadingComments: undefined,
innerComments: undefined,
trailingComments: undefined
},
comments: [],
leadingComments: undefined,
innerComments: undefined,
trailingComments: undefined
},
listKey: undefined,
key: 'program',
node: Node {
type: 'Program',
start: 0,
end: 16,
loc: SourceLocation {
start: [Position],
end: [Position],
filename: undefined,
identifierName: undefined
},
sourceType: 'module',
interpreter: null,
body: [ [Node] ],
directives: [],
leadingComments: undefined,
innerComments: undefined,
trailingComments: undefined
},
type: 'Program',
parent: Node {
type: 'File',
start: 0,
end: 16,
loc: SourceLocation {
start: [Position],
end: [Position],
filename: undefined,
identifierName: undefined
},
errors: [],
program: Node {
type: 'Program',
start: 0,
end: 16,
loc: [SourceLocation],
sourceType: 'module',
interpreter: null,
body: [Array],
directives: [],
leadingComments: undefined,
innerComments: undefined,
trailingComments: undefined
},
comments: [],
leadingComments: undefined,
innerComments: undefined,
trailingComments: undefined
},
hub: {
file: File {
...
code: 'class App {\r\n\r\n}',
inputMap: null,
hub: [Circular *2]
},
...
},
data: null,
context: TraversalContext {
...
},
scope: Scope {
...
}
}
可以看到总体上结构时差不多的,在真实结构中一般就比网页版多套一层node( path.node ),所以一般参照网页版后直接path.node就可以取到想要的属性。而且是没有最外层的File结构的,只在Program的parent中。
FunctionDeclaration,ClassDeclaration,ArrowFunctionExpression
我们日常写的代码一定是在普通函数、类、箭头函数里面的,所以在这外面的注释我们一律不管,所以这三个节点分别是函数声明、类声明、箭头函数声明。在遍历过程中凡是遇到这三个节点就会进去对应的方法。
注释
眼尖的朋友可能发现了,在上面打印出来的一堆属性中,有comments、leadingComments等单词出现,没错,这就是我们需要关注的行级注释,我们下面实验一下。
function App(){
// 这是innerComments注释
}
function fn() {
// 这是const的前置注释
const a = 1;
function inFn() {
// 这是inFn的inner注释
}
// 这是inFn的后置注释(trailingComments)
}
对应的AST树结构(网页版)
{
...
"program": {
"type": "Program",
...
"body": [
{
...
"id": {
...
"name": "fn"
},
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
...
"body": [
{
"type": "VariableDeclaration",
...
"declarations": [
{
...
"id": {
...
"identifierName": "a"
},
"name": "a"
},
"init": {
...
"value": 1
}
}
],
"kind": "const",
"leadingComments": [
{
"type": "CommentLine",
"value": " fn", // 是const的前置注释
...
}
]
},
{
"type": "FunctionDeclaration",
...
"id": {
"type": "Identifier",
...
"name": "inFn"
},
...
"body": {
"type": "BlockStatement",
...
"innerComments": [ // inner注释
{
"type": "CommentLine",
"value": " inFn",
...
}
}
]
},
"trailingComments": [ // inFn的后置注释
{
"type": "CommentLine",
"value": " abc",
...
}
]
}
],
"directives": []
}
}
],
"directives": []
},
"comments": [
{
"type": "CommentLine",
"value": " fn",
...
},
...其他注释
]
}
可以发现一共有三种注释类型
leadingComments前置注释innerComments内置注释trailingComments后置注释
这三个属性都对应一个数组,每个元素都是一个对象,一个对象对应一个注释
前置和后置注释很好理解,即存在于某个节点的前面或者后面,innerComments呢,只存在于BlockStatement(也就是函数用的大括号)里面,当一个BlockStatement里面有其他语句的时候,这个innerComments又会变成其他语句的前置或后置注释
下面举个例子
function App(){
// 这是innerComments注释
}
function App(){
const a = 2
// 这是trailingComments注释
}
除了上述三个属性外,在最外的File层还有一个comments属性,这里存放着里面所有注释,但是只是可以看,并不能对其进行操作,因为我们是要删除注释后插入对应代码的,在这里操作后就不知道去哪里注入代码了
手写plugin
确定结构
分析完行级注释后,接下来就要确定plugin的基本结构,既然我们只在函数里面操作,那肯定要有一个函数的入口,可以写如下代码
Program: {
enter(path) {
console.log("enter");
console.log("path: ", path);
},
exit(path) {
console.log("exit");
}
},
FunctionDeclaration(path, state) {
},
ClassDeclaration(path, state) {
},
ArrowFunctionExpression(path, state) {
}
但是我们在这三个节点里面进行的操作都是一样的,解决办法就是把方法名用|分割成xxx|xxx形式的字符串
"FunctionDeclaration|ClassDeclaration|ArrowFunctionExpression"(path, state) {}
进入函数以后,还需要对函数里面的节点进行遍历,我们可以调用traverse方法
traverse
traverse方法是@babel/traverse里默认导出的方法,使用traverse可以手动遍历ast树
// 示例代码
import * as babylon from "babylon";
import traverse from "@babel/traverse";
const code = `console.log("test")`;
const ast = babylon.parse(code); // babylon是babel的解析器,将代码转为ast树
traverse(ast, {
enter(path) {
...
}
});
但是我们在visitor里面可以直接使用path.traverse方法,在traverse方法里传入一个对象,不同于visitor,对象里面直接可以放enter方法,也可以放其他节点方法。注释可能在每一个节点旁边,所以我们需要观察每一个节点,所以我们接下来的操作全部都在enter里面。
"FunctionDeclaration|ClassDeclaration|ArrowFunctionExpression"(path, state) {
path.traverse({
enter(path) {
// 操作注释
}
})
}
这时候有同学就有疑问了,我们所有的操作都在path.traverse里面,那如果是外层函数的innerComments怎么办。现实是innerComments是在BlockStatement里面的,而不是在声明语句里面的,所以我们进来后并没有错过任何在函数内的comment。
获取注释
下面就是根据ast结构获取comment了,我们先拿leadingComments试试水
const leadingComments = path.node.leadingComments;
if (leadingComments?.length) {
for (const comment of leadingComments) {
if (comment?.type === "CommentLine") { // 只替换行级
console.log("待更换的注释是", comment.value);
}
}
}
我们给plugin换个“恶劣”一点的测试代码
// @debug
class App {
// inner
/* 块级 */
// 123
inClass() {
// buried-0
console.log(213);
// afterConsole
const b = 2;
}
}
// 外边的猴嘴
function fn() { // fn右边
// buried-1
const a = 1;
// 猴嘴
}
fn();
const a = () => {
// buried-7
};
a();
运行打包后打印
$ webpack --config test/webpack.config.js
enter
待更换的注释是 inner
待更换的注释是 123
待更换的注释是 buried-0
待更换的注释是 afterConsole
待更换的注释是 fn右边
待更换的注释是 buried-1
exit
可以看到从上到下打印出了leadingComments,非常成功,这下子就有信心了,赶紧加上另外两种注释
handleComments(innerComments, "innerComments");
handleComments(trailingComments, "trailingComments");
handleComments(leadingComments, "leadingComments");
function handleComments(comments, commentName) {
if (!comments?.length) return;
for (const comment of comments) {
if (comment?.type === "CommentLine") { // 只替换行级
console.log("待更换的注释是", commentName, comment.value);
}
}
}
另外把处理注释的代码抽离出去,没有人想写三次不是吗
打印出来
$ webpack --config test/webpack.config.js
enter
待更换的注释是 leadingComments inner
待更换的注释是 leadingComments 123
待更换的注释是 trailingComments afterConsole
待更换的注释是 leadingComments buried-0
待更换的注释是 leadingComments afterConsole
待更换的注释是 trailingComments 猴嘴
待更换的注释是 leadingComments fn右边
待更换的注释是 leadingComments buried-1
待更换的注释是 innerComments buried-7
exit
感觉非常完美,但是,怎么感觉有一个注释重复打出来了,吓得我赶紧看看ast树
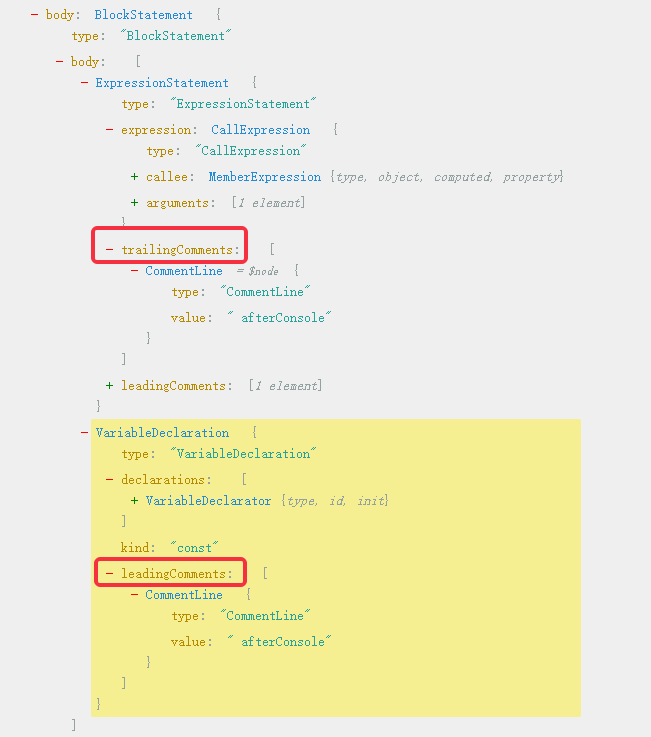
破案了,原来afterConsole既是console.log(123)的trailComment,又是const b=2的leadingComment,这里我称这种注释为“双重注释”,这就需要我们进行去重了,我们先来看看path有哪些属性可以用来去重
去重
使用 path.key获取路径所在容器的索引
path.key可以获得元素的索引,那用这个属性去重好像行得通,下面举个例子演示一下
const a = 1; // path.key = 0
// 注释
const b = 2; // path.key = 1
const c = 3; // path.key = 2
思路:以上面的a、b、c举例,给一个全局的duplicationKey如果注释在a和b中间,当要处理b的leading时,如果有key-1 === duplicationKey,就是如果b的前面有节点存在,则只删除comment,但不注入代码片段
下面我们就来在实际的代码实现一下,我们直接打印出path.key即可
enter(path) {
console.log("pathKey: ", path.key);
...
}
对应代码片段以及运行结果:
// buried-0
console.log(213);
// afterConsole
const b = 2;
pathKey: 0
待更换的注释是 trailingComments afterConsole
待更换的注释是 leadingComments buried-0
pathKey: expression
pathKey: callee
pathKey: object
pathKey: property
pathKey: 0
pathKey: 1
待更换的注释是 leadingComments afterConsole
可以看到前一个节点的key确实是后面的key-1,但是这样又要维护一个全局变量又要判断key是不是数字,特别麻烦,我们可以使用另一个属性
使用 path.getSibling(index)来获得同级路径
使用path.getSibling(path.key - 1)获取上一个兄弟节点即可,如果存在则只删除但不注入代码片段(如果只删除一边,是没有效果的,编译出来的文件还是会有注释)
const isSiblingTrailExit = !path.getSibling(path.key - 1)?.node?.trailingComments;
handleComments(path, leadingComments, "leadingComments", path.parent.body, state.buriedInfo, isSiblingTrailExit)
我们再将测试用例写复杂点
function fn() { // fn右边
function abc() {
// abcInner
}
// 猴嘴
}
打包输出
$ webpack --config test/webpack.config.js
enter
...
待更换的注释是 innerComments abcInner
待更换的注释是 innerComments abcInner
exit
发现abc函数里面的注释被遍历了两次
我们再套一层,发现被遍历了三次
function fn() { // fn右边
function abcd() {
function abc() {
// abcInner
}
}
// 猴嘴
}
$ webpack --config test/webpack.config.js
enter
...
待更换的注释是 innerComments abcInner
待更换的注释是 innerComments abcInner
待更换的注释是 innerComments abcInner
exit
细心的同学可能已经发现问题了,visitor中每次进入函数都会调用目前的这个方法,但是path.traverse的enter里面也包含函数里面的函数,除了最外一层函数,里面的函数都是重复遍历的,这样时间复杂度会呈指数级增加,这当然是不能忍的。要解决这个bug,遍历时每个函数只需要进入一次就够了,那我们在enter里面碰到函数节点进来时直接跳过不就行了吗。
跳出遍历
path里面每个节点都有对应的一个判断方法,判断当前节点是否是对应类型,一般形式是path.isxxx(),xxx为节点类型名,所以FunctionDeclaration、ClassDeclaration、ArrowFunctionExpression对应的判断方法为isFunctionDeclaration、isArrowFunctionExpression、isClassDeclaration。判断以后我们还需调用path.skip(),该方法能跳过当前遍历到的节点
if (path.isFunctionDeclaration() || path.isArrowFunctionExpression() || path.isClassDeclaration()) {
path.skip();
}
再次打包输出
$ webpack --config test/webpack.config.js
enter
待更换的注释是 leadingComments fn右边
待更换的注释是 trailingComments 猴嘴
待更换的注释是 innerComments abcInner
exit
插入注释
现在我们已经可以顺利地拿到项目中所有的行级注释了,接下来我们先将所有注释都替换成固定的语句,如果是块级注释,我们可以将节点使用某些方法替换掉,但是对于行级注释,我们需要分成两步处理
插入需要的代码片段 删除注释
在我们的enter里面,我们是同时处理三种注释,但是在插入代码片段时,leadingComments和trailComments对应的作用域是在上一层节点的,所以需要使用path.parent找到父级节点。
想要插入代码片段,必须使用template解析字符串形式的语句,将其转为ast节点,此方法来自@babel/template,在这里因为此函数是作为一个插件函数导出,所以babel的一些方法会传入这个函数,我们通过解构获得template,在babel底层还是调用@babel/core的,所以这个方法的实例是在@babel/core上面
module.exports = function({ template }){
function handleComments(path, comments, commentName, pathBody, isAdd) {
if (!comments?.length) return;
for (let i = comments.length - 1; i >= 0; i--) {
const comment = comments[i];
if (comment?.type === "CommentLine") { // 只替换行级
const commentArr = comment.value.split("-");
if (commentArr && commentArr[0]?.trim() === "buried") {
if (isAdd) {
console.log("待更换的注释是", commentName, comment.value);
}
path.node[commentName].splice(i, 1);
}
}
}
}
...
enter(path){
...
handleComments(path, innerComments, "innerComments", path.node.body, true);
const isSiblingTrailExit = !path.getSibling(path.key - 1)?.node?.trailingComments;
handleComments(path, leadingComments, "leadingComments", path.parent.body, isSiblingTrailExit);
handleComments(path, trailingComments, "trailingComments", path.parent.body, true);
}
如果要对path下面的注释进行操作,一定要用path找到对应comment进行操作,所以一定要把path传过去。
因为使用splice删除数组中的元素,所以倒序遍历
插入注释就直接在pathbody里面push即可,如何找到pathBody,就直接在ast树上寻找即可,这里就省略此过程
运行输出,查看main.js,可以看到全部注释已经被替换
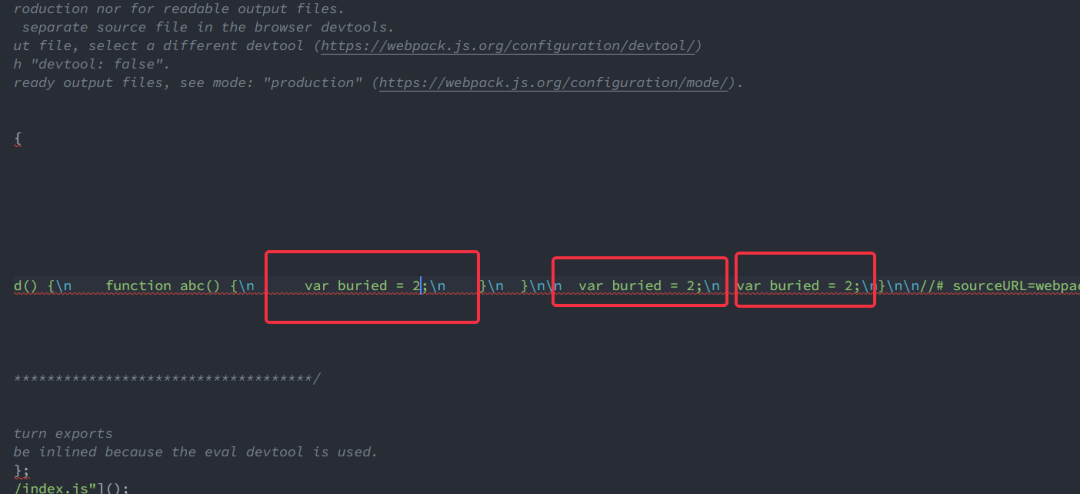
处理Excel表
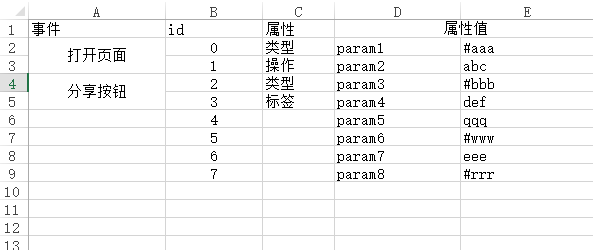
到此为止最麻烦的部分已经解决,接下来就要替换带有标志的注释了,首先要建立注释标志对应的代码片段的映射,我们的方案是读取一个Excel表,这也是为了给不懂代码配置的人(策划、运营)来填写。
首先确定Excel表的格式,id作为标识,属性值是需要传入全局函数的,我们将全局函数命名为AddStatistic,属性值中带有#的是变量,不带#的是字符串
安装node-xlsx,运行yarn add node-xlsx
封装一个解析函数
function parseXlsx(excelFilePath) {
// 解析excel, 获取到所有sheets
const sheets = xlsx.parse(excelFilePath);
const sheet = sheets[0];
return sheet.data.reduce((v, t) => {
if (t[1] === "id") return v;
const paramsArr = [];
for (let i = 3; i < t.length; i++) {
paramsArr.push(t[i]);
}
v[t[1]] = paramsArr;
return v;
}, {});
}
返回的数据格式如下
{
'0': [ 'param1', '#aaa' ],
'1': [ 'param2', 'abc' ],
'2': [ 'param3', '#bbb' ],
'3': [ 'param4', 'def' ],
'4': [ 'param5', 'qqq' ],
'5': [ 'param6', '#www' ],
'6': [ 'param7', 'eee' ],
'7': [ 'param8', '#rrr' ]
}
处理注释
这个函数在Program调用,将得到的buriedInfo存储在state里面
state是存储着一些全局(AST遍历的时候所有入口都能拿到)的属性,作为vistor的全局属性,它可以用来存储一些全局变量,我们将buriedInfo放到state里面,然后传入path.traverse里面的handleComments
Program: {
enter(path, state) {
state.buriedInfo = parseXlsx("./buried.xlsx");
},
},
在handleComments里加一些东西,这些东西就不赘述了
function handleComments(path, comments, commentName, pathBody, buriedInfo, isAdd) {
if (!comments?.length) return;
for (let i = comments.length - 1; i >= 0; i--) {
const comment = comments[i];
if (comment?.type === "CommentLine") { // 只替换行级
const commentArr = comment.value.split("-");
if (commentArr && commentArr[0]?.trim() === "buried") {
if (isAdd) {
const id = commentArr[1].trim();
console.log("buriedInfo[id]", id, buriedInfo[id]);
const params = buriedInfo[id] === undefined ? undefined : buriedInfo[id].map(v => {
return v && v[0] === "#" ? v.slice(1, v.length) : `"${v}"`;
});
const pointAST = template(`window.AddStatistic(${params[0]},${params[1]});`)();
pathBody.push(pointAST);
}
path.node[commentName].splice(i, 1);
}
}
}
}
我们拿最开始的测试用例进行测试
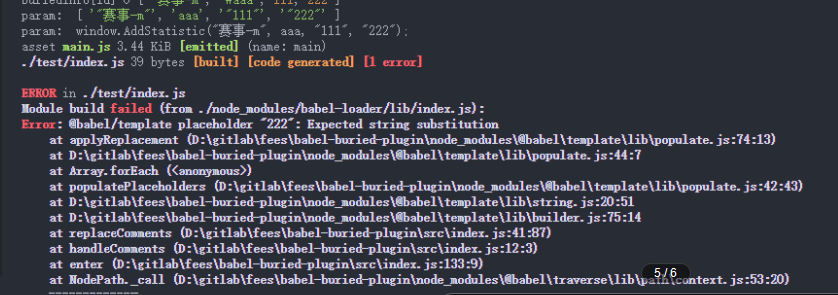
可以看到成功替换掉标志的注释,而且全部标志注释已经删掉
现在只能往AddStatistic加入两个参数,我曾想根据Excel表动态加入参数,使用Array.prototype.join()形成参数,但是总是报错,如果有大佬知道怎么处理可以评论一下
注入全局函数
我们已经把调用AddStatistic的语句插入到项目中,接下来将AddStatistic挂载到全局中,直接在Program的enter里面插入即可
Program: {
enter(path, state) {
const globalNode = template(`window.AddStatistic = ${func}`)();
path.node.body.unshift(globalNode);
}
},
注入script
还有我们要把对应的script插入到html中,同样还是在入口处插入一段代码
// 注入添加script代码
const addSctipt = `(function() {
const script = document.createElement("script");
script.type = "text/javascript";
script.src = "${script}";
document.getElementsByTagName("head")[0].appendChild(script);
})();`;
const addSctiptNode = template(addSctipt)();
path.node.body.unshift(addSctiptNode);
这里的func和script变量都是可以自定义的,在webpack.config.js里配置
plugins: [
[
path.resolve(__dirname, "../src/index.js"),
{
xlsxPath: path.resolve(__dirname, "../buried.xlsx"),
func: `function(category, action) {
window._hmt && window._hmt.push(["_trackEvent", category, action]);
};
`,
script: "https://test.js"
}
]
]
这里传进去的对象可以在state.opts中获得
Program: {
enter(path, state) {
const { xlsxPath, func, script } = state.opts;
}
}
测试一下,在dist目录下面新建一个index.html,引入main.js
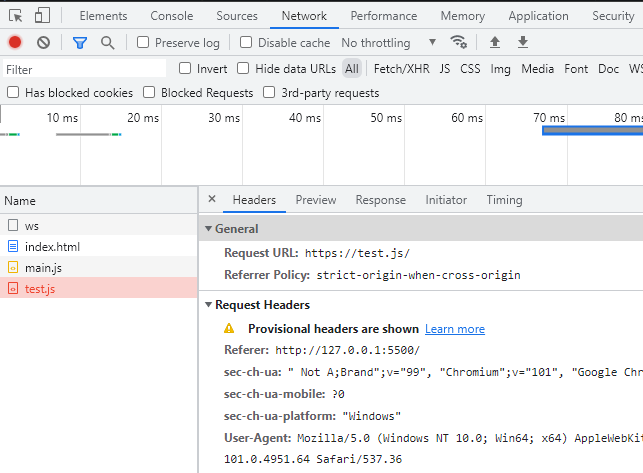
发布
在package.json中写好配置
{
"name": "babel-plugin-tracker",
"version": "0.0.1",
"description": "一个用于统计埋点的babel插件",
"main": "./src/index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1",
"dev": "webpack --config test/webpack.config.js"
},
"keywords": [
"webpack",
"plugin",
"babel",
"babel-loader",
"前端",
"工具",
"babel-plugin",
"excel",
"AST",
"埋点"
],
"author": "plutoLam",
"license": "MIT",
...
}
将main指向刚刚的index.js,直接运行npm publish即可,没有配置npm的小伙伴可以看看其他教程
尾声
babel埋点插件的开发到这里就完成啦,希望大家可以学到一些东西
npm地址:https://www.npmjs.com/package/babel-plugin-tracker
GitHub地址:https://github.com/plutoLam/babel-plugin-tracker
结语
「❤️关注+点赞+收藏+评论+转发❤️」,原创不易,鼓励笔者创作更多高质量文章
最近「JowayYoung」上新了一本新小册「从 0 到 1 落地前端工程化」,对前端工程化感兴趣的可以扫码了解下!