
【译】关系型数据库的工作原理
共 1716字,需浏览 4分钟
·
2021-08-11 11:46
一、前言
在进行高性能 Java 持久性培训时,我意识到有必要解释关系数据库的工作原理,否则,很难掌握许多与事务相关的概念,例如原子性、持久性和检查点。
在这篇文章中,我将对关系数据库的内部工作方式进行高层次的解释,同时还暗示一些特定于数据库的实现细节。
二、一图胜千文
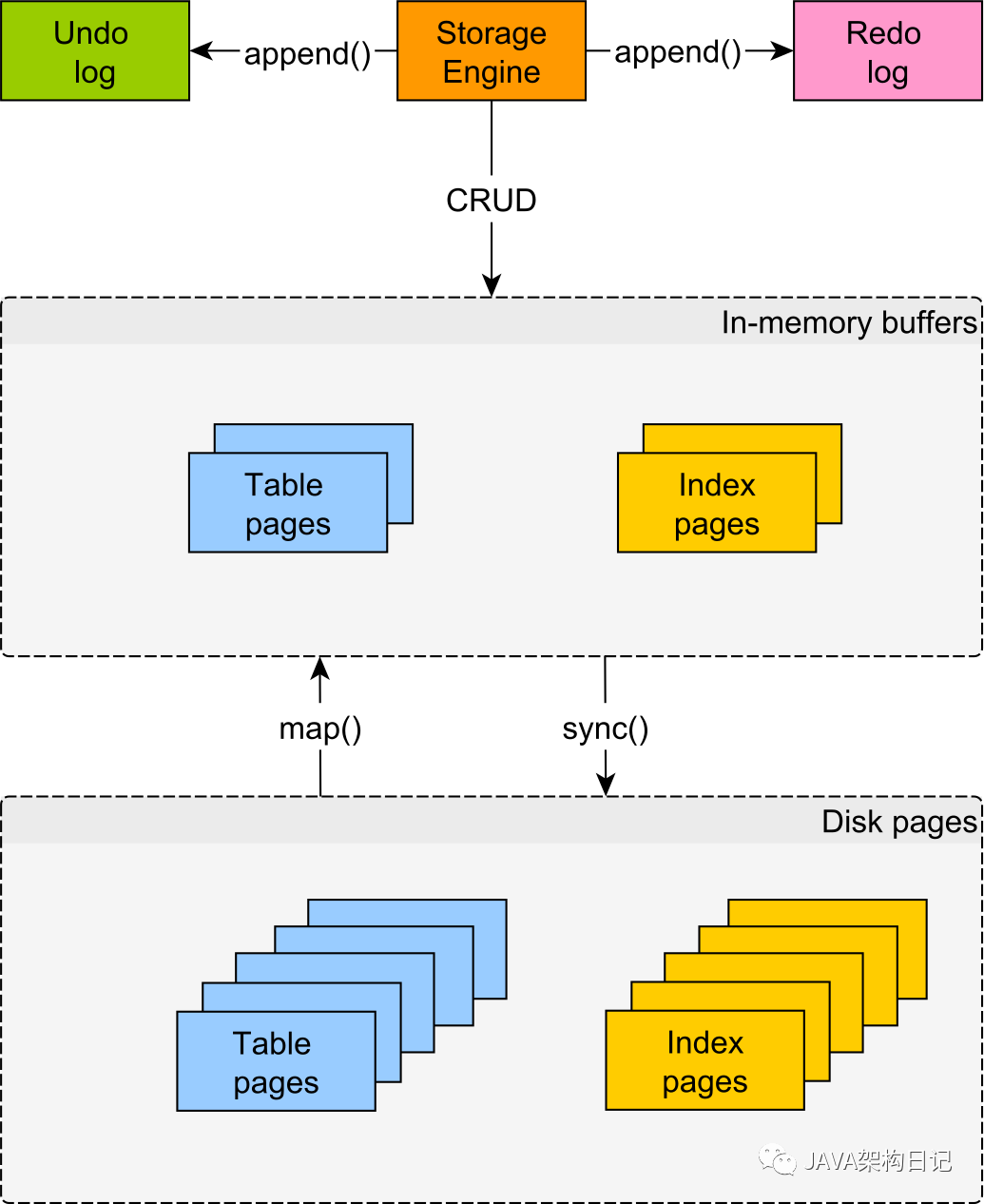
二、Data pages
磁盘访问速度很慢。另一方面,内存甚至比固态硬盘还要快几个数量级。出于这个原因,数据库供应商试图尽可能延迟磁盘访问。无论我们谈论的是表还是索引,数据都被分成一定大小(例如 8 KB)的 page。
当需要读取数据(表或索引)时,关系数据库会将基于磁盘的页面映射到内存缓冲区。当需要修改数据时,关系数据库会更改内存 pages。要将内存 pages 与磁盘同步,必须进行 flush(例如 fsync)。
存储基于磁盘的 page 的缓冲池大小有限,因此通常需要存储数据工作集。只有当整个数据可以放入内存时,缓冲池才能存储整个数据集。但是,如果需要缓存新 page 时磁盘上的总体数据大于缓冲池大小,则缓冲池将不得不逐出旧 pages 为新 pages 腾出空间。
三、Undo log
因为内存中的变化可以被多个并发事务访问,所以必须采用并发控制机制(例如 2PL 和 MVCC)来确保数据完整性。因此,一旦事务修改了表行,未提交的更改将应用于内存结构,而先前的数据会临时存储在 undo log append-only 结构中。
虽然这种结构在 Oracle 和 MySQL 中称为 undo log,但在 SQL Server 中,事务日志起着这种作用。PostgreSQL 没有 undo log,但是通过多版本表结构达到了相同的目的,因为表可以存储同一行的多个版本。然而,所有这些数据结构都用于提供回滚能力,这是原子性的强制性要求。
如果当前运行的事务回滚,undo log 将用于重建事务开始时的内存 pages。
四、Redo log
一旦事务提交,内存中的更改必须保持不变。但是,这并不意味着每个事务提交都会触发 fsync。事实上,这对应用程序性能非常不利。然而,从 ACID 事务属性,我们知道提交的事务必须提供持久性,这意味着即使我们拔掉数据库引擎,提交的更改也需要持久化。
那么,关系数据库如何提供持久性而不在每次事务提交时发出 fsync 呢?
这就是 redo log 发挥作用的地方。redo log也是一种 append-only 基于磁盘的结构,用于存储给定事务所经历的每个更改。因此,当事务提交时,每个数据页更改也将写入_redo log。与刷新固定数量的 data pages 相比,写入 redo log 非常快,因为顺序磁盘访问比 Random access 快得多。因此,它还允许事务快速处理。
虽然这种结构在 Oracle 和 MySQL 中被称为 redo log,但在 SQL Server 中,事务日志也扮演着这个角色。PostgreSQL 将其称为预写日志 (WAL)。
但是,何时将内存中的更改 flush 到磁盘?
关系数据库系统使用检查点将内存中的脏 pages 与其基于磁盘的对应物同步。为避免 IO 流量拥塞,同步通常在较长的时间段内分块完成。
但是,如果关系数据库在将所有脏内存 pages 刷新到磁盘之前崩溃会发生什么?
万一发生崩溃,在启动时,数据库将使用 redo log 重建自上次成功检查点以来未同步的基于磁盘的 data pages。
五、结论
采用这些设计考虑是为了克服基于磁盘的存储的高延迟,同时仍然提供持久性存储保证。因此,需要 undo log 来提供原子性(回滚能力),而需要 redo log 来确保基于磁盘的 page(表和索引)的持久性。
六、译者说:
大家好,我是 如梦技术春哥(mica 开源作者)翻译不易,请帮忙分享给更多的同学,谢谢!!!