
从低代码到无代码:可视化逻辑编排
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
背景介绍
近年来,关于低代码(LowCode)和无代码(NoCode)的讨论在前端社区内越来越火,简单的说低代码就是通过编写少量代码的方式完成应用的开发及上线,而无代码则更进一步,不需要编写代码通过配置的方式即可完成整个应用的开发。目前集团内部的低代码平台已经有很多,比如iceluna,宜搭,乐高,云凤蝶等等,而通用的无代码搭建平台还处在探索阶段。
低代码和无代码
首先不管是低代码还是无代码,都是针对特定场景或者细分领域的,比如运营的活动页,中后台的表单,表格页面等,因为只有在这些场景下,前端交互相对收敛,能够沉淀出足够多的组件物料,从而通过可视化的方式拖拽组件就能够直接搭建出页面。
目前我所在的团队正在研究面向营销域的中后台前端解决方案。通常来说,中后台解决方案的核心目标是提效,提效包括两个方面,一方面是对研发人员的提效,另一方面是对用户的提效,提效的核心抓手在于生产关系的变更,由前端开发向后端,视觉,产品各方面参与发展,从而降低前端研发的门槛,提高生产效率。提效解决的不是20%的个性化增量需求,而是解决让“非前端”参与进来,解决80%的通用需求。中后台的提效路径大部分走的都是ProCode->LowCode->NoCode方式。
表面上看,从ProCode->LowCode->NoCode看起来好像只有很小的差别,好像只有代码量多少的问题,但整个过程已经从量变发生了质变。ProCode和LowCode主要面向的还是一些需要有前端编程能力的人,而NoCode则代表“非前端”也能够参与的前端的页面搭建中来,这里面不是说完全不需要代码,因为今天哪些算“代码”其实比较难界定,比如用户编写一个配置文件,这个文件是json格式的,那到底能不能算“代码”?所以,NoCode的意思不是说没有代码,而是说在于用户学习门槛和学习成本的降低,普通用户不需要经过艰难的学习就可以做到以前程序要编码才能实现的事情。
iceluna低代码平台的痛点问题
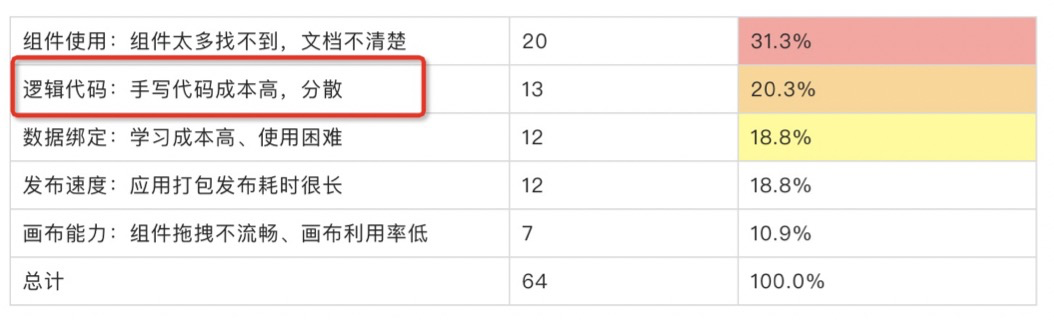
iceluna作为集团内优秀的低代码搭建平台,主要解决中后台页面快速搭建的场景,经过几年的探索,基本能够实现页面UI的可视化搭建,但是针对业务逻辑还是需要手动编码来实现。这对非前端开发人员的上手门槛还是比较高的。下面这张图是最近针对iceluna的用户(前端,后端和测试)做的一个调研分析,可以看到逻辑代码和数据绑定的学习成本也是用户在问卷中提的最多的。
可视化逻辑编排
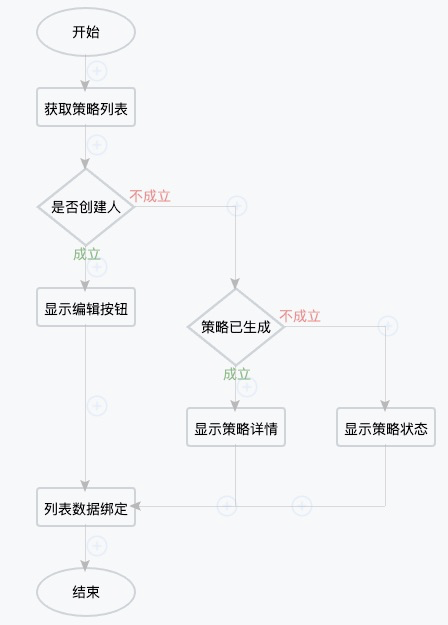
首先我们来通过一个逻辑编排的示例来看一下如果一段代码通过编排的方式呈现出来之后会带来怎么样的体感:
逻辑节点抽象
可以看出,要形成这样的逻辑图谱,本质上就是需要对不同逻辑节点进行组合和串联,真正的逻辑由封装在节点中的函数完成。那么这里就产生了两个问题,首先是如何抽象逻辑节点,抽象出的逻辑节点能不能被复用直接决定了用户编排的成本,如果需要不断的定制个性化逻辑节点可能就失去了编排的意义;其次是逻辑节点的的颗粒度大小也非常关键,如果封装的逻辑颗粒度太大,大到一个功能服务,那么可能就变成了业务流程编排;如果颗粒度太小,小到一个表达式级别,那么对于有编程基础的同学来说,可能直接写代码效率反而更高。
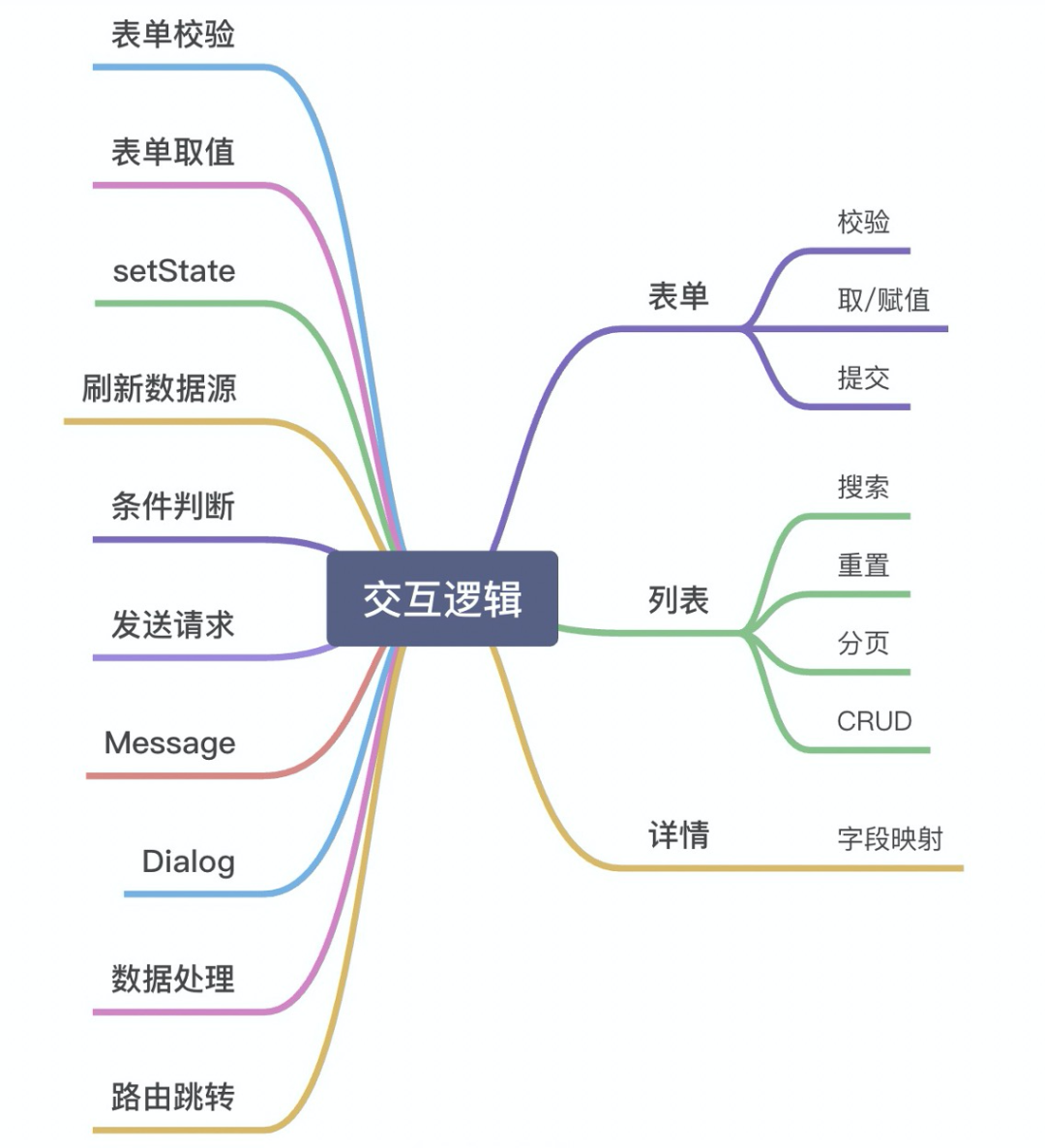
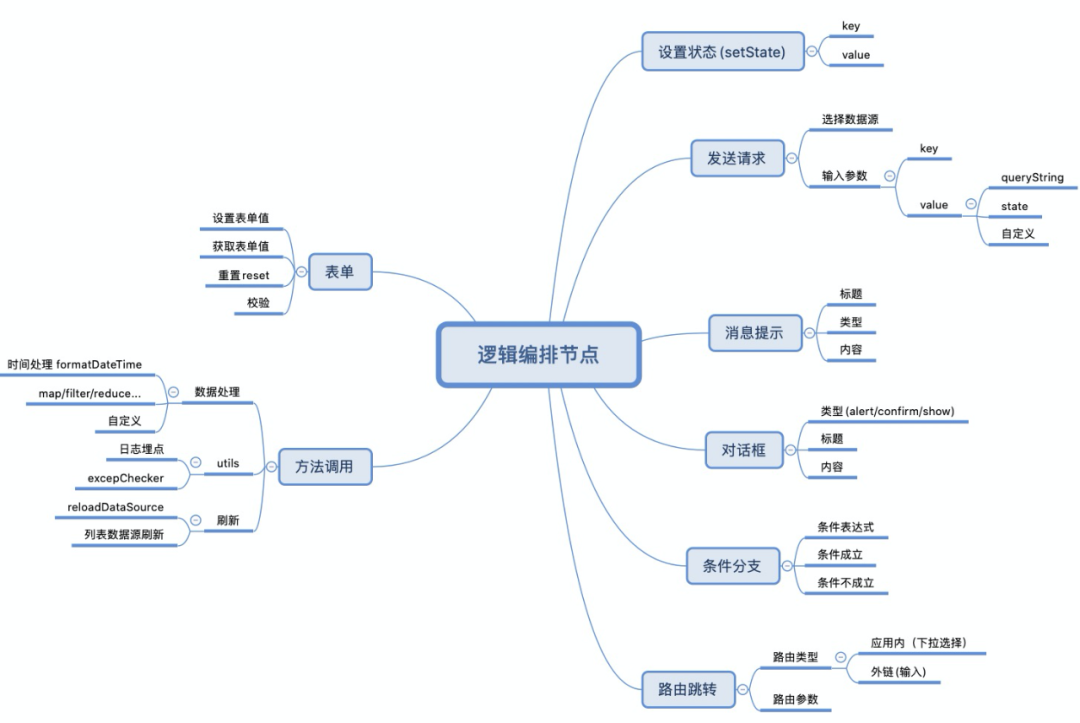
通过对中后台营销域的部分业务代码进行梳理,发现中后台的页面大都是以表单、列表,详情为主,而其中90%的业务逻辑基本上都围绕在表单(校验,取值,赋值,提交),对话框(显隐、提示),发送请求,消息提示,数据处理,路由跳转,条件判断等,相对比较收敛。同时iceluna作为集团内优秀的低代码搭建平台,在上层封装了很多非常好用的api,屏蔽了大部分前端语法层面的差异,比如状态赋值,页面刷新,接口调用,一些常用的工具函数(时间处理)等,为逻辑节点的抽象提供了极大的便利性。
编排协议
由于是可视化编排,自然也避免不了编排的协议,为了避免重复建设最大程度的复用集团内已有的编排方案,最终计划采用LF通用可视化逻辑编排的协议来实现iceluna中的逻辑编排。

技术架构图
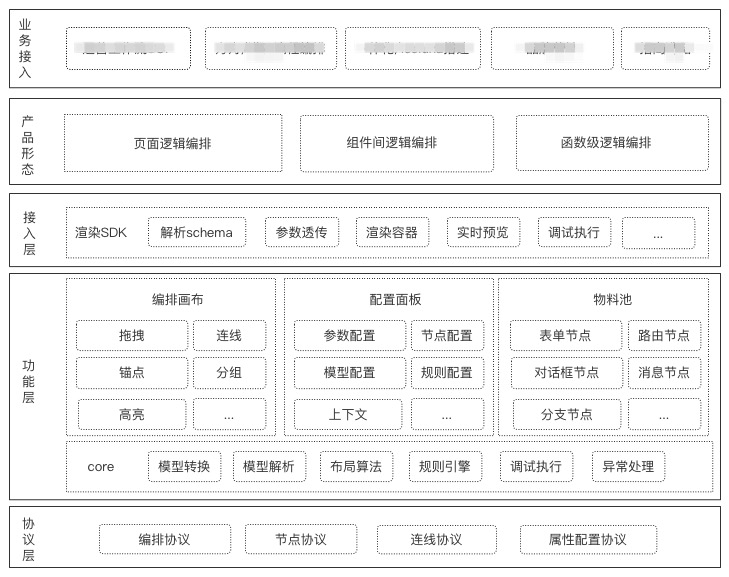
技术难点
自动化布局
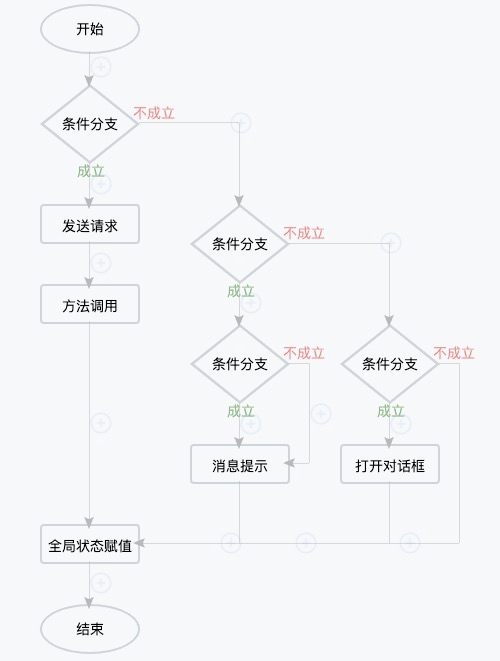
从一开始调研我们就发现大部分的编排产品,都是让用户自己进行拖拽,连线等操作去完成,但是通过前面对逻辑代码的分析,如果我们将异步回调操作使用async/await的方式转换成同步的写法,那么逻辑代码大部分都可以看作是一种串行式的执行过程,偶尔叠加一些if/else的分支判断,这样也非常符合人们常用的思维模式,理解起来非常直观。所以从编排的角度说,就是将不同的逻辑节点和分支判断节点串联起来,布局上不需要太多的灵活性,同时连线操作也显得比较多余,因此我们将拖拽连线全部改成添加节点的方式,然后自动连线即可。
采用这种自动布局的方式会大大简化用户的操作,用户只需关注核心的业务逻辑流程,按顺序添加节点即可,但同时也带来一个问题,由于分支类型的节点会产生两个分支流,如果遇到嵌套分支的情况下,需要自动将上层分支的横坐标的位置统一向右偏移一个单位,否则处在上下层不同分支上的节点位置可能会产生重叠。为此,我设计了一自动布局算法,最终实现的效果图如下:
代码与schema互转
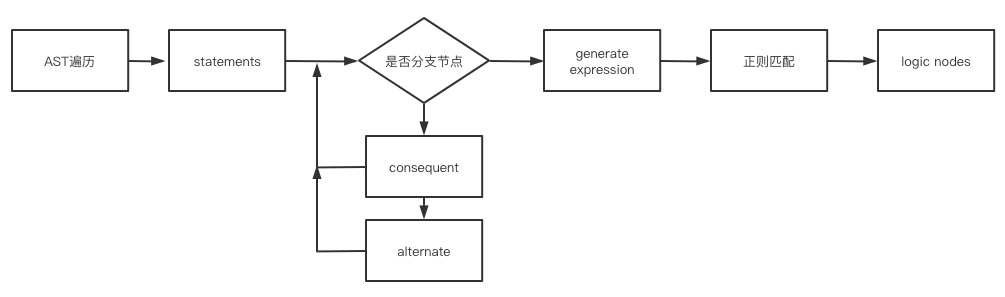
逻辑图编排完成之后,紧接着面临的问题是如何保证编排后的逻辑正确的运行,产生和源码一样的效果。一开始讨论的有两种方案,第一种方案把整个逻辑看成一个事件流,按照前面设计的逻辑编排schema,通过事件注册监听的方式完成逻辑节点的上下游串联,最后设计一套事件执行器,依次触发事件即可。这种方式实现起来比较简单,但是对原有开发流程的侵入性比较强。因为原有保存事件函数的地方都要被替换成逻辑schema,同时负责code review的前端同学看到的不再是代码diff,而是schema的diff,这无疑会大大增加了CR的风险。因此经过一番讨论之后,我们决定采用第二种方案,将逻辑编排后的schema自动转成代码,同时生成后的代码也要能够自动转回schema。
基于schema转成代码是比较容易的,因为每个逻辑节点本身就映射了一段函数片段,而将代码转回schema则稍微有些复杂。这里主要利用了Babel先对代码进行解析,得到抽象语法树AST,然后遍历AST中类型为statement的节点,最后通过正则匹配找到对应的逻辑节点,并串联好连线即可。下图就是生成好的一份代码示例:
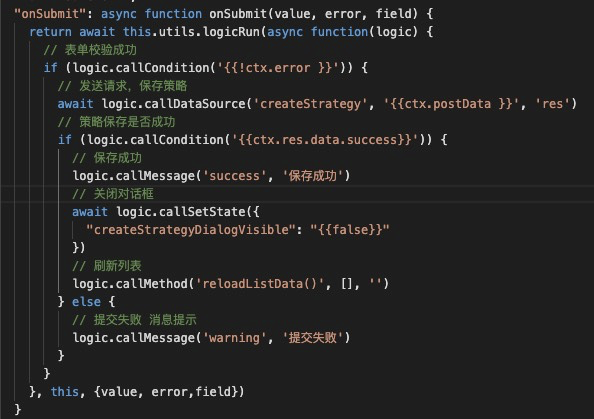
断点调试
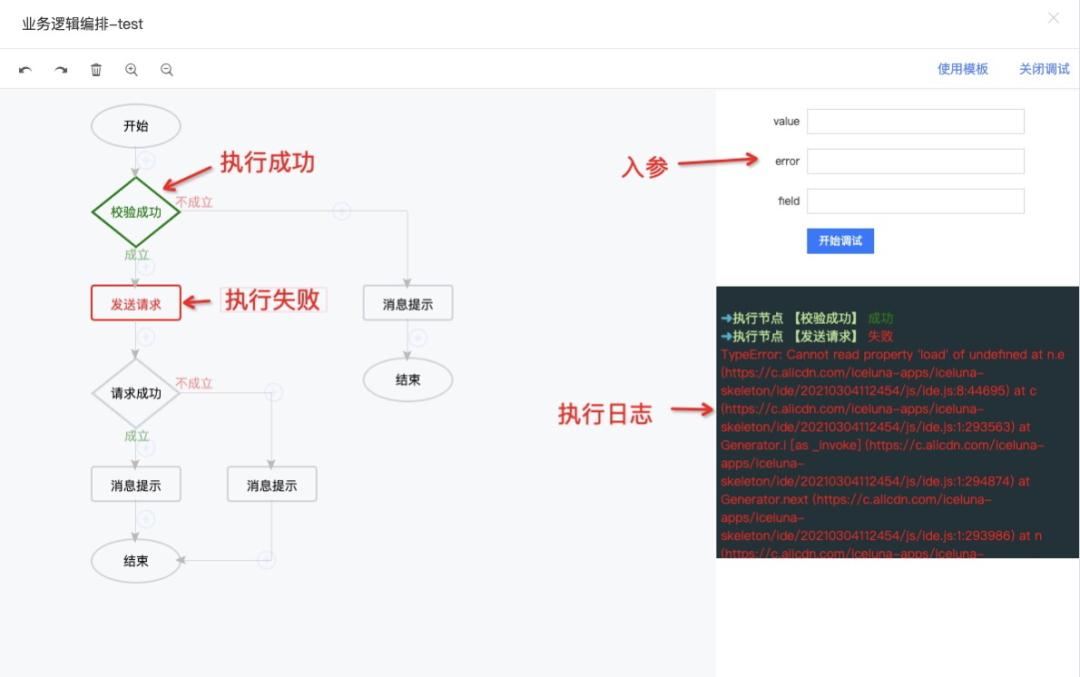
对于写业务逻辑来说,不可避免的需要调试功能,这对有编程能力的同学来说是件很自然的事情,但是当逻辑变成通过可视化的编排之后,如何让这些”非前端“用户也能方便的通过调试定位错误,变得也尤为关键。
调试其实本质上对用户来说,就是需要一个能够让编排后的逻辑模拟运行起来的过程,因此我们对逻辑节点的各个环节做了埋点,用户在模拟运行的过程中就能查看每个节点的数据状态、上下文参数、报错类型等,同时根据逻辑流程图的状态(绿色代表执行成功,红色代表执行失败)也能非常快速的定位问题所在,如下图所示:
总结展望
总结
目前,可视化逻辑编排已经搭载集团内的iceluna低代码搭建平台正式上线,并已经在营销工具业务中正式使用。从低代码向无代码的研发模式升级仍处在探索阶段,过程中避免不了会遇到很多问题,但也算迈出了关键性的一步,值得期待。
展望
前面提到,从ProCode->LowCode->NoCode,通过降低研发门槛,让非技术人员参与到应用开发中来,可以大大提高生产效率,但理想很丰满,现实也很骨感,NoCode搭建平台我认为目前还只能在比较垂直的场景中才能适用,并且由于不像LowCode一样仍然能够写代码的逃离机制,通过NoCode的方式可能只能完成一个70分左右的产品。但是换一个角度去看,如果可以让一个非技术人员,只用很低的门槛就完成一个70分左右的产品(最小可用产品MVP),并能直接推广到市场去试错,如果验证可行,再通过转成LowCode或者ProCode的方式继续迭代优化。光这一点我认为就是很有价值的,是推动商业创新的核心驱动力。因此我认为未来的产品研发节奏可能是从NoCode->LowCode->ProCode,每一流程都要有对应的解决方案,并且互相之间能够相互打通,只有这样才能在竞争日益激烈的市场环境下更好的生存。


“分享、点赞、在看” 支持一波 