
【图解机器学习】人人都能懂的算法原理

算法公式挺费神,机器学习太伤人。任何一个刚入门机器学习的人都会被复杂的公式和晦涩难懂的术语吓到。但其实,如果有通俗易懂的图解,理解机器学习的原理就会非常容易。本文整理了一篇博客文章的内容,读者可根据这些图理解看似高深的机器学习算法。

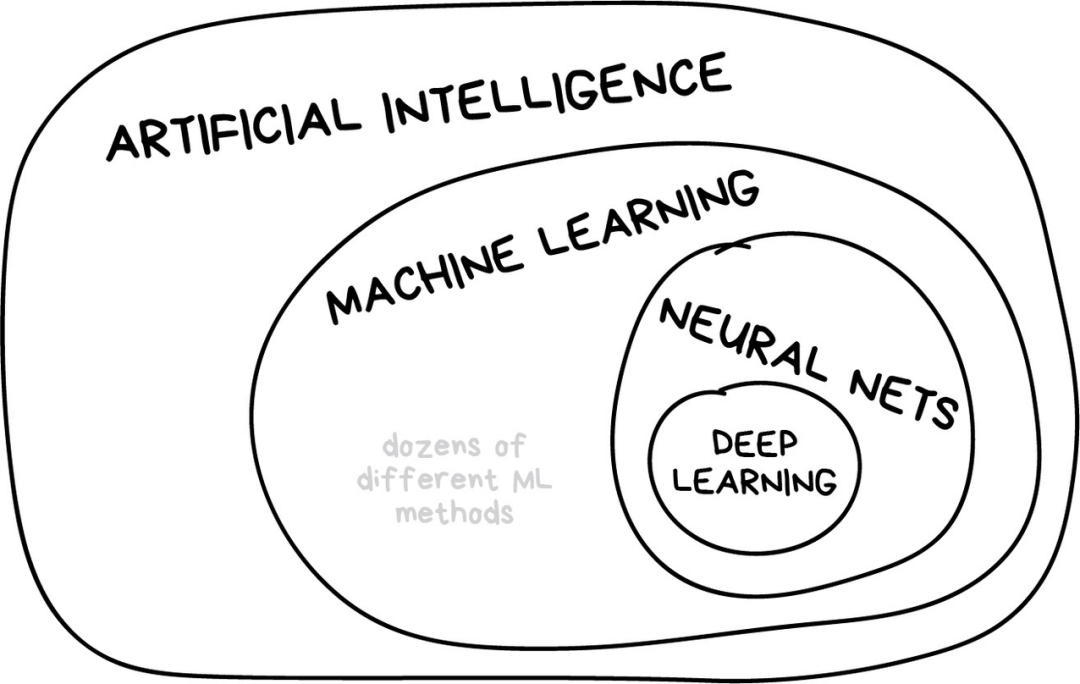
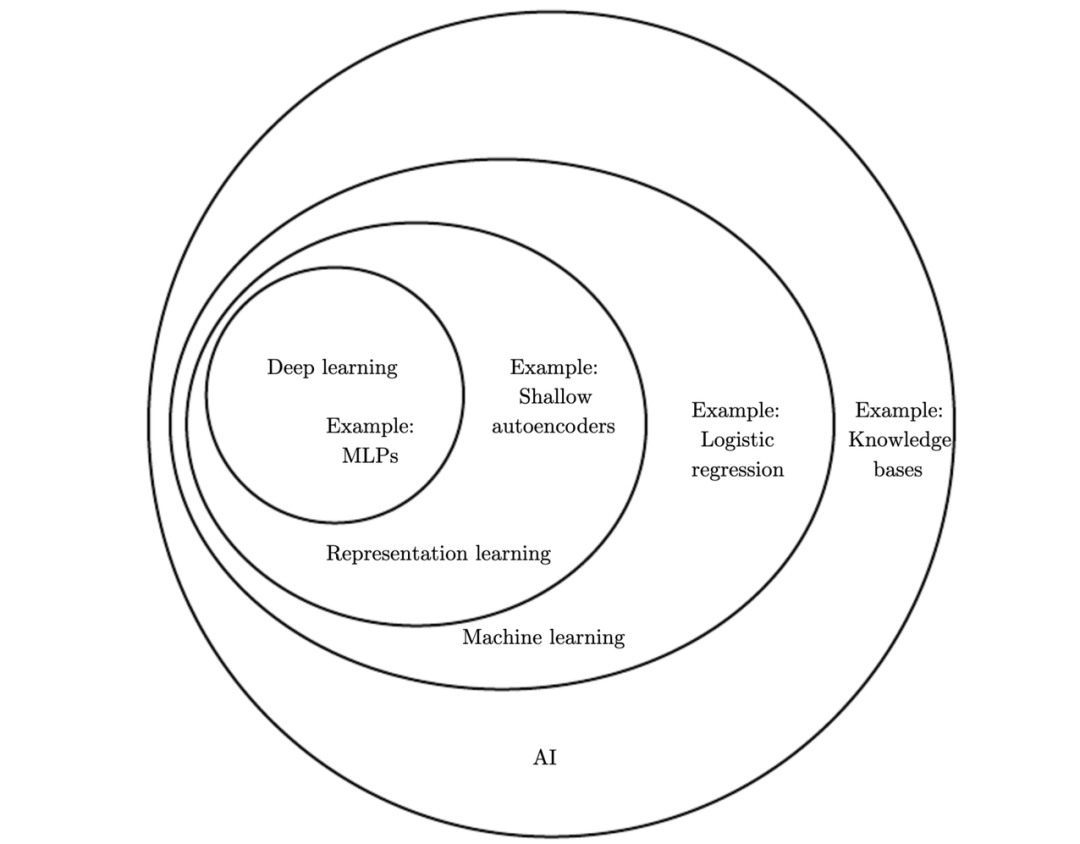
人工智能是个完整的知识领域,类似于生物学或者是化学;
机器学习是人工智能中非常重要的一部分,但并不是唯一一个部分;
神经网络是机器学习的一种,现在非常受欢迎,但依然有其他优秀的算法;
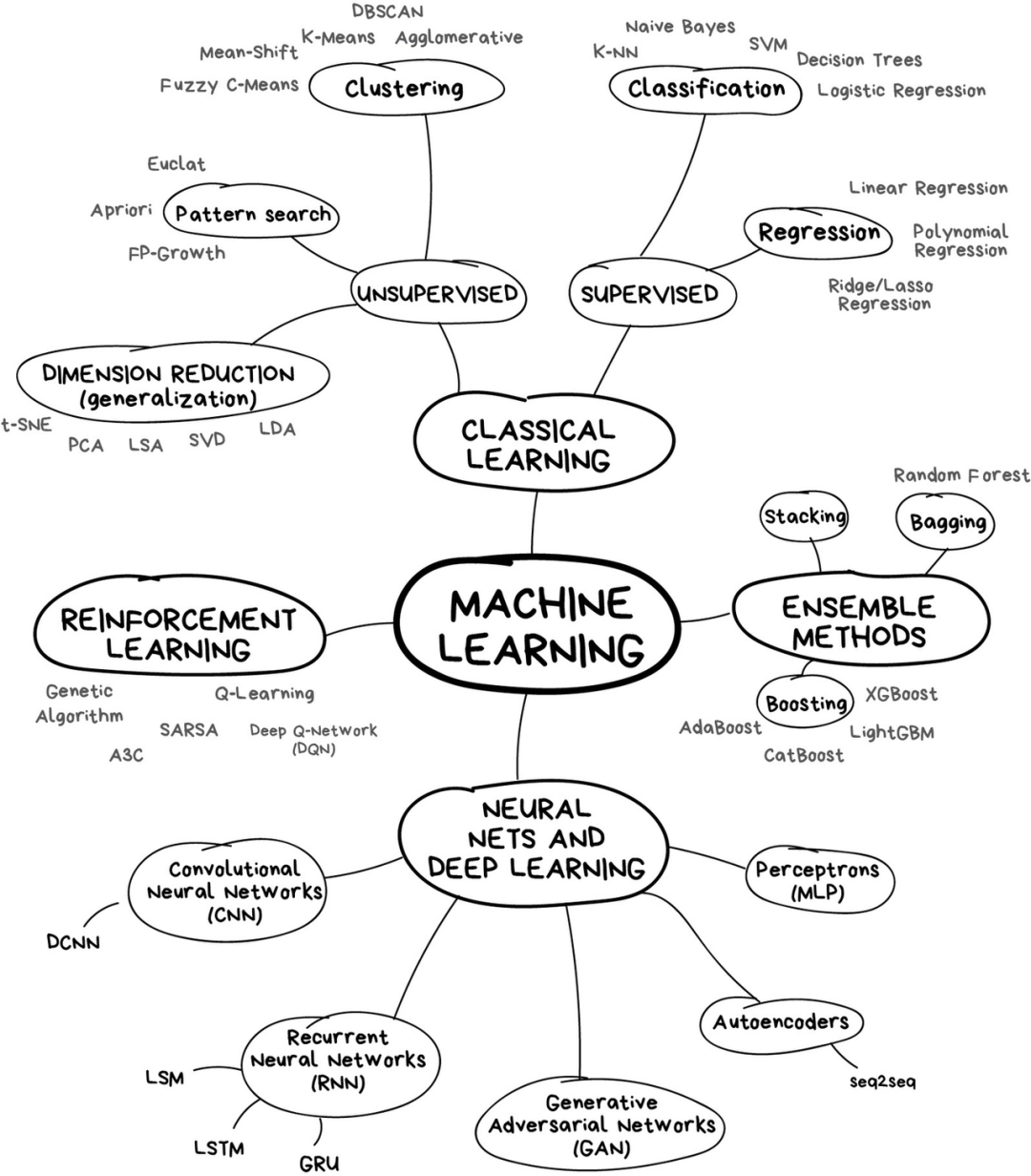
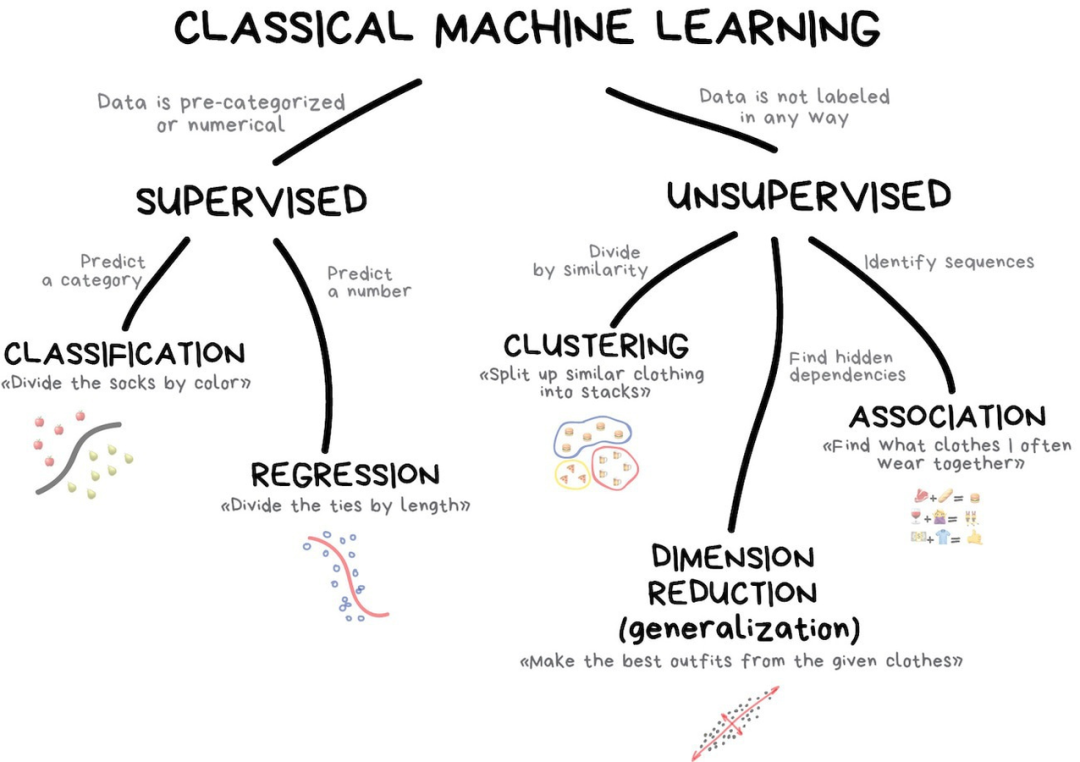
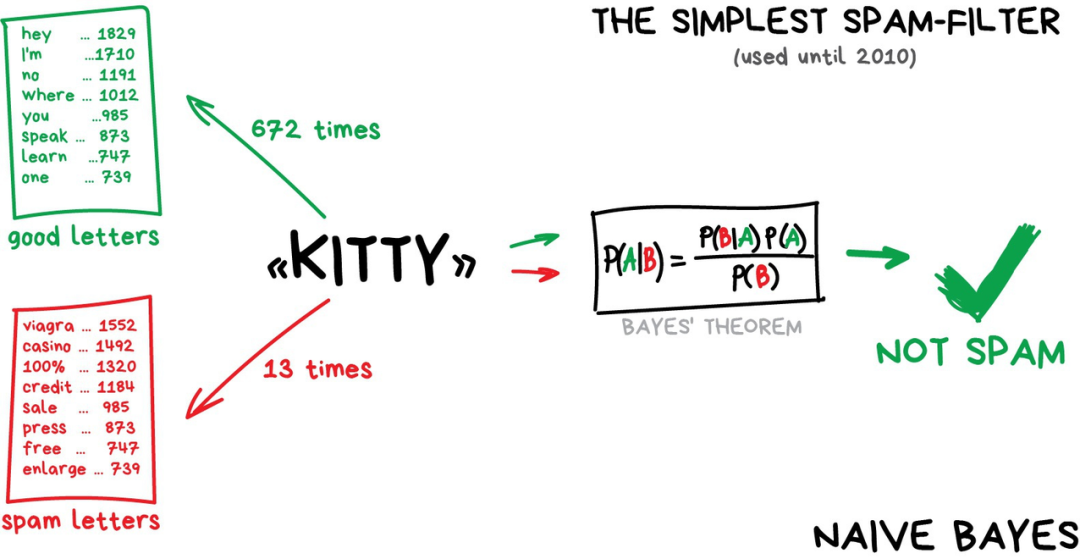
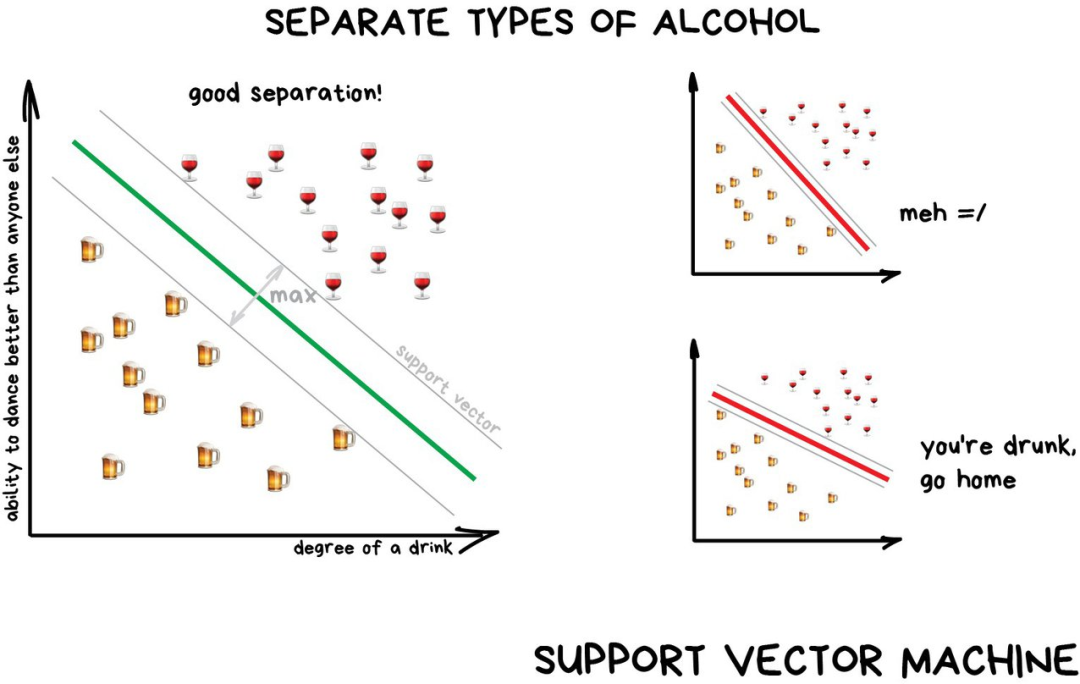
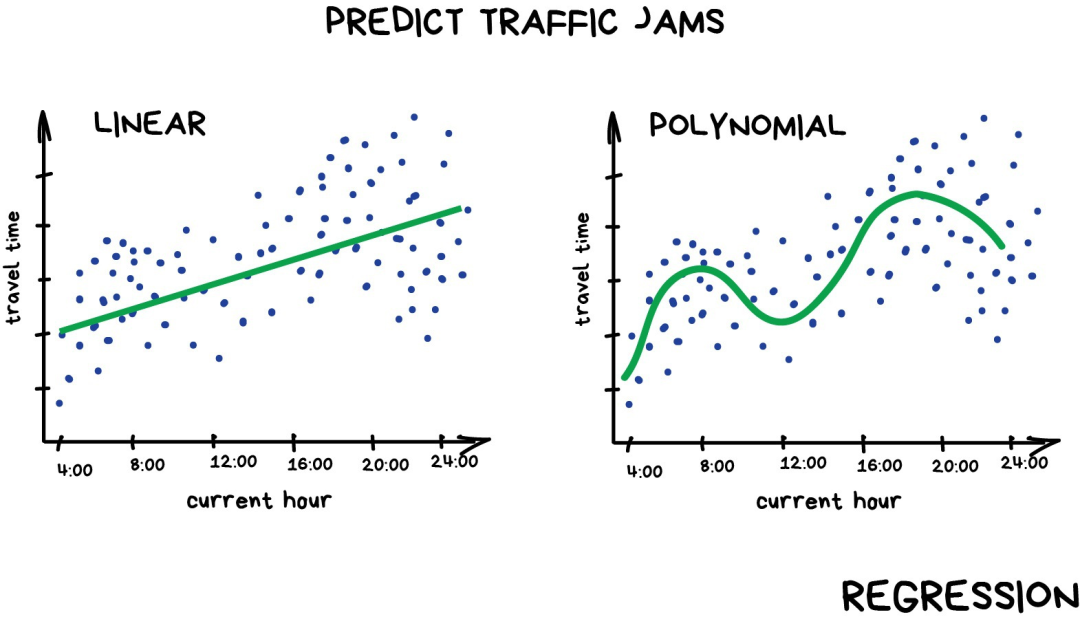
经典机器学习;
强化学习;
神经网络和深度学习;
集成方法;
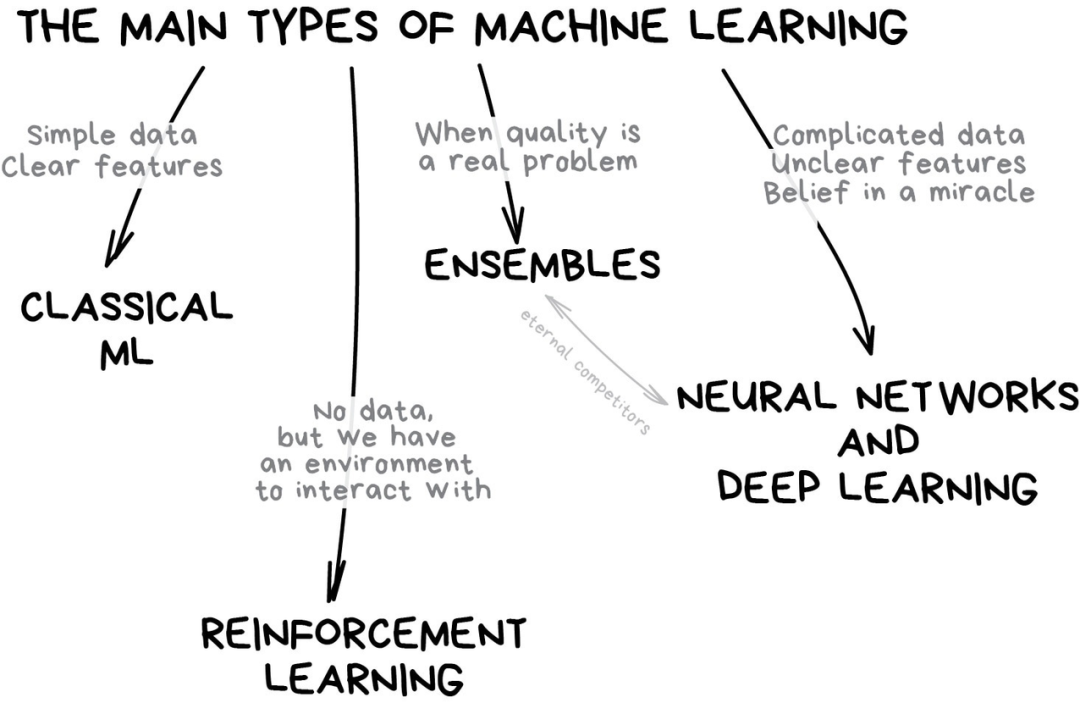
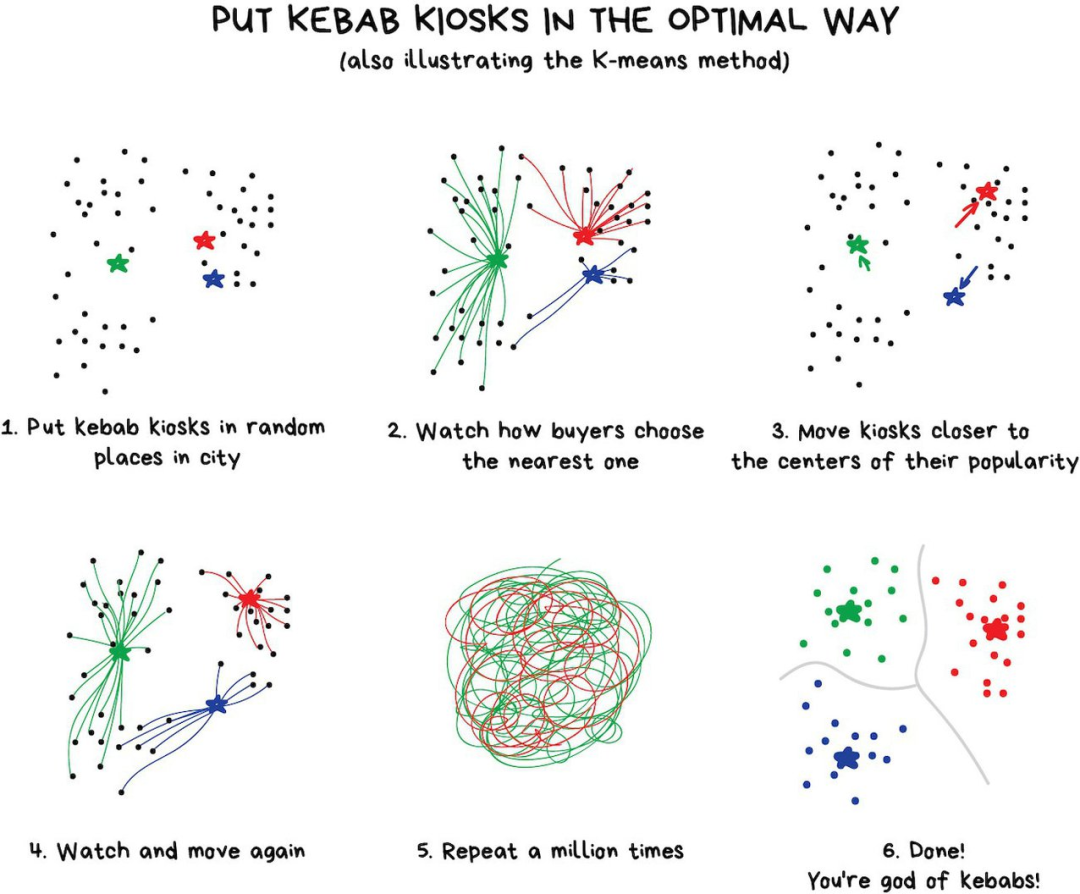
「将特定的特征组合成更高级的特性」

「在订单流中分析出特征模式」

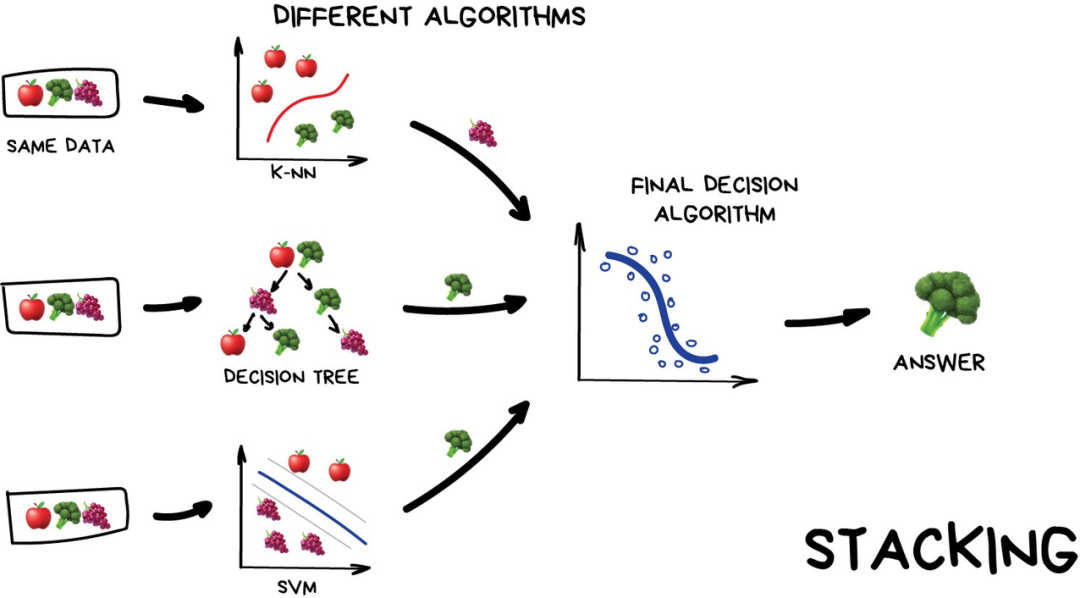
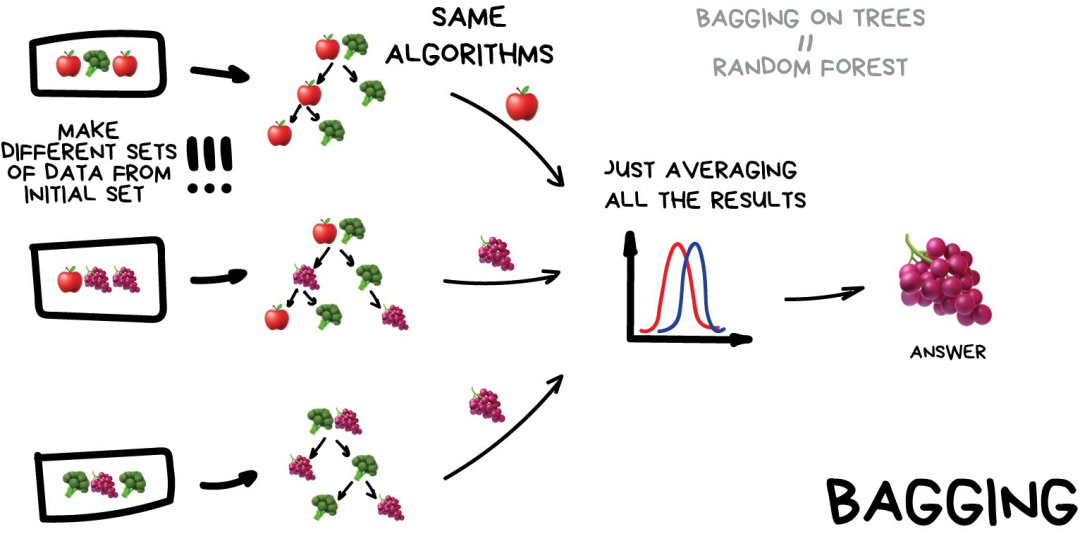
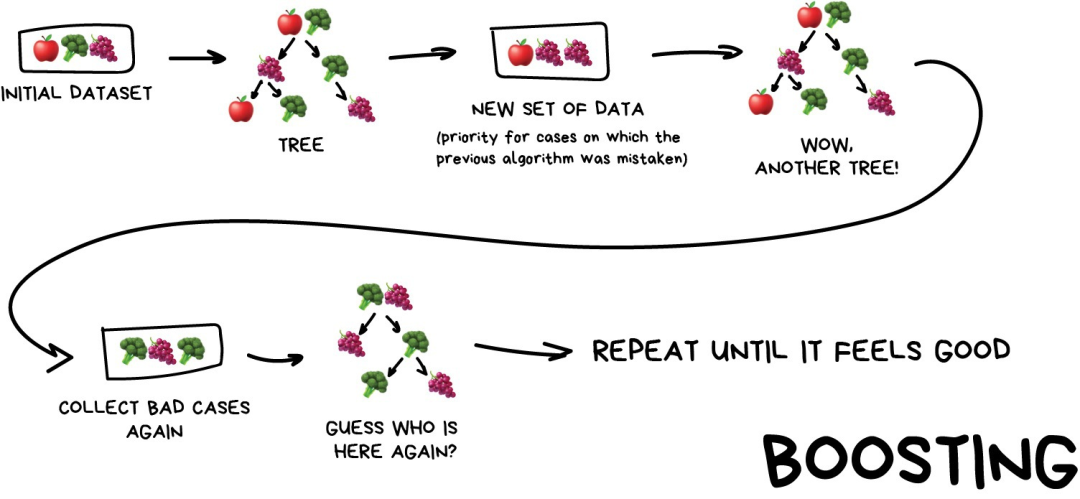

评论