
0.2 秒居然复制了 100G 文件?怎么做到的?
点击关注公众号,Java干货及时送达
来源 | OSC开源社区(ID:oschina2013)
cp 命令,把他给惊到了!cp 拷贝了一个 100 G的文件,竟然一秒不到就拷贝完成了!ls 看一把文件,显示文件确实是 100 G。sh-4.4# ls -lh
-rw-r--r-- 1 root root 100G Mar 6 12:22 test.txt
sh-4.4# time cp ./test.txt ./test.txt.cp
real 0m0.107s
user 0m0.008s
sys 0m0.085s
cp 一秒没到就完成了工作,惊呆了,为啥呢?分析文件
du 命令看一下,却只有 2M ,根本不是100G,这是怎么回事?sh-4.4# du -sh ./test.txt
2.0M ./test.txt
stat 命令显示的信息:sh-4.4# stat ./test.txt
File: ./test.txt
Size: 107374182400 Blocks: 4096 IO Block: 4096 regular file
Device: 78h/120d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 12:22:00.888871000 +0000
Modify: 2021-03-13 12:22:46.562243000 +0000
Change: 2021-03-13 12:22:46.562243000 +0000
Birth: -
stat 命令输出解释:Size 为 107374182400(知识点:单位是字节),也就是 100G ; Blocks 这个指标显示为 4096(知识点:一个 Block 的单位固定是 512 字节,也就是一个扇区的大小),这里表示为 2M;
Size 表示的是文件大小,这个也是大多数人看到的大小; Blocks 表示的是物理实际占用空间;
现实的存取场景
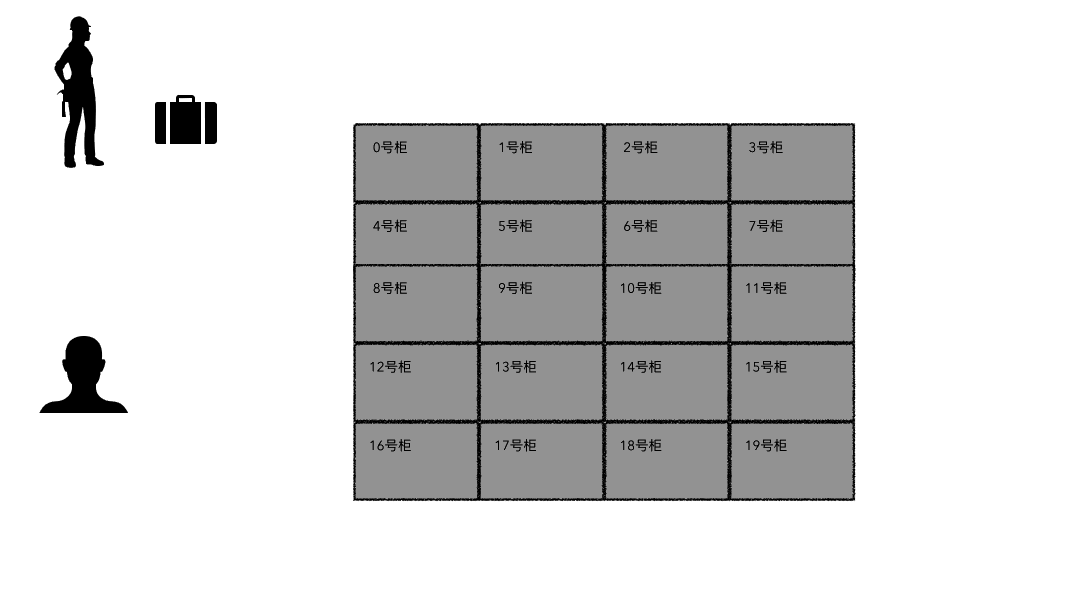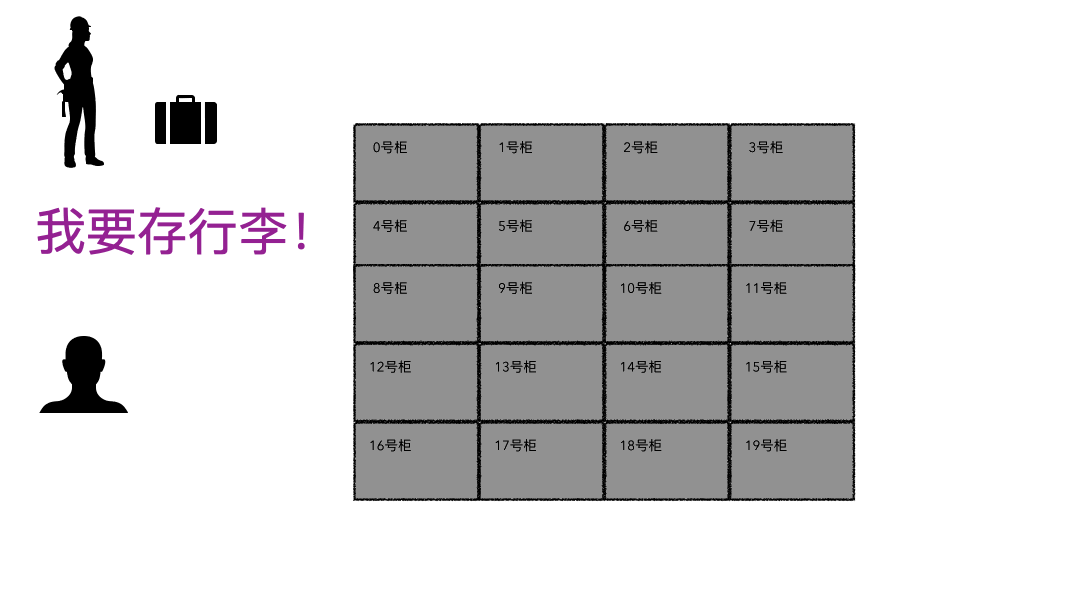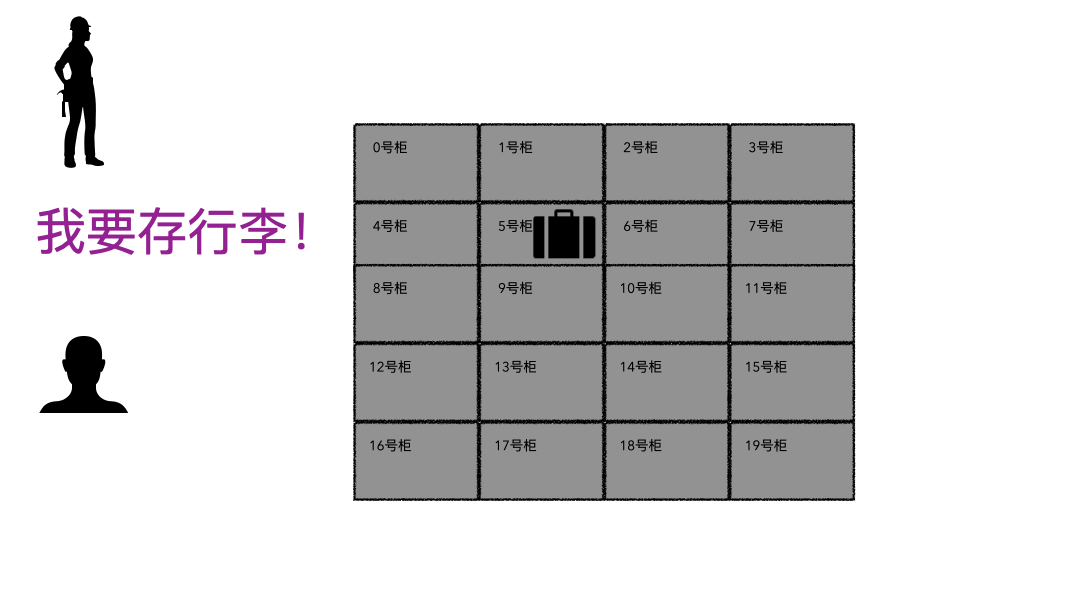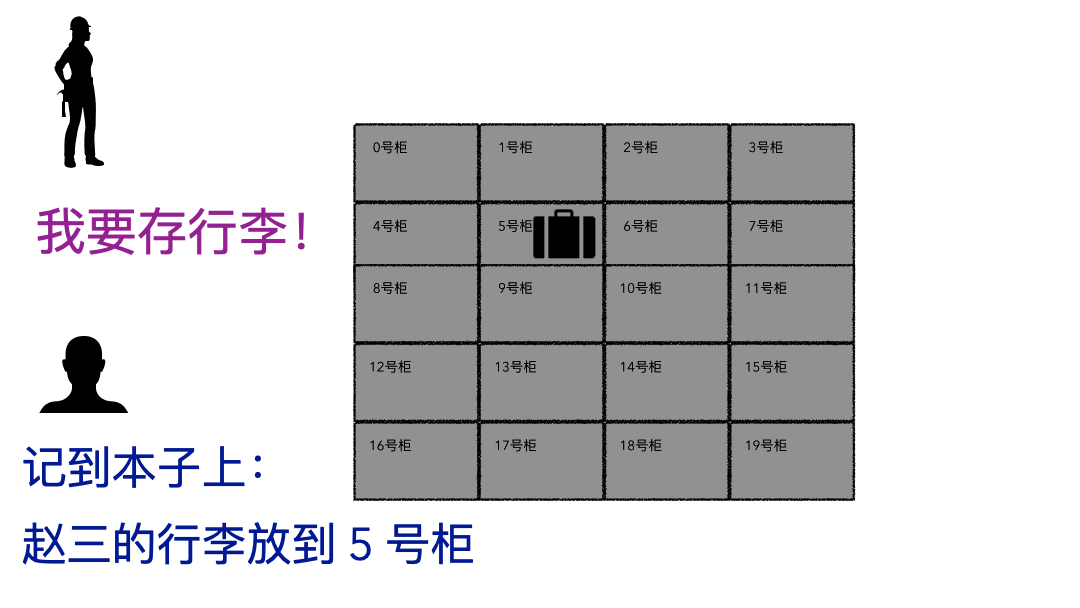
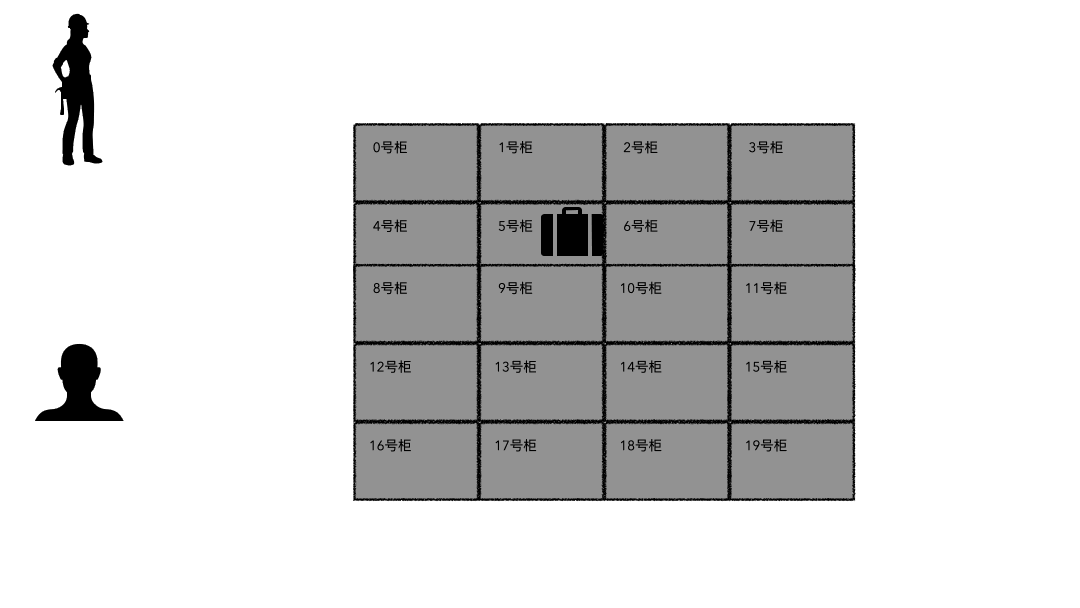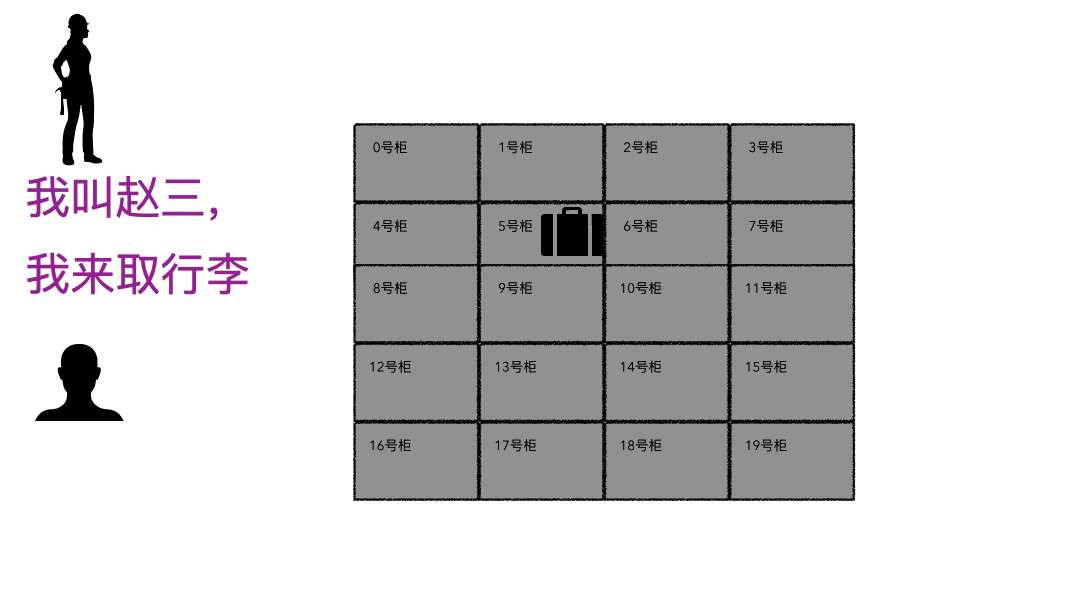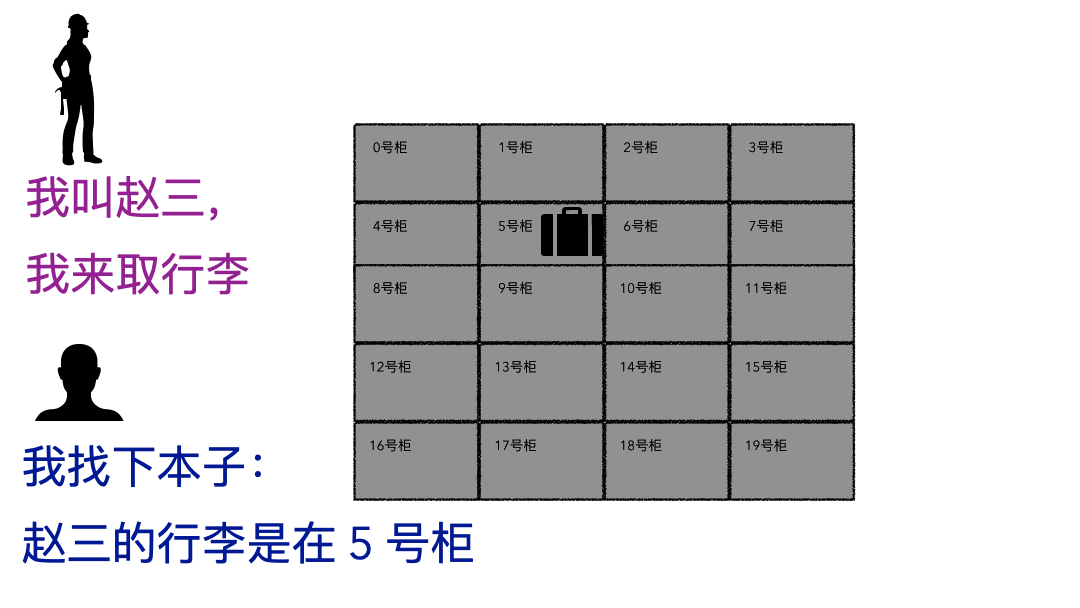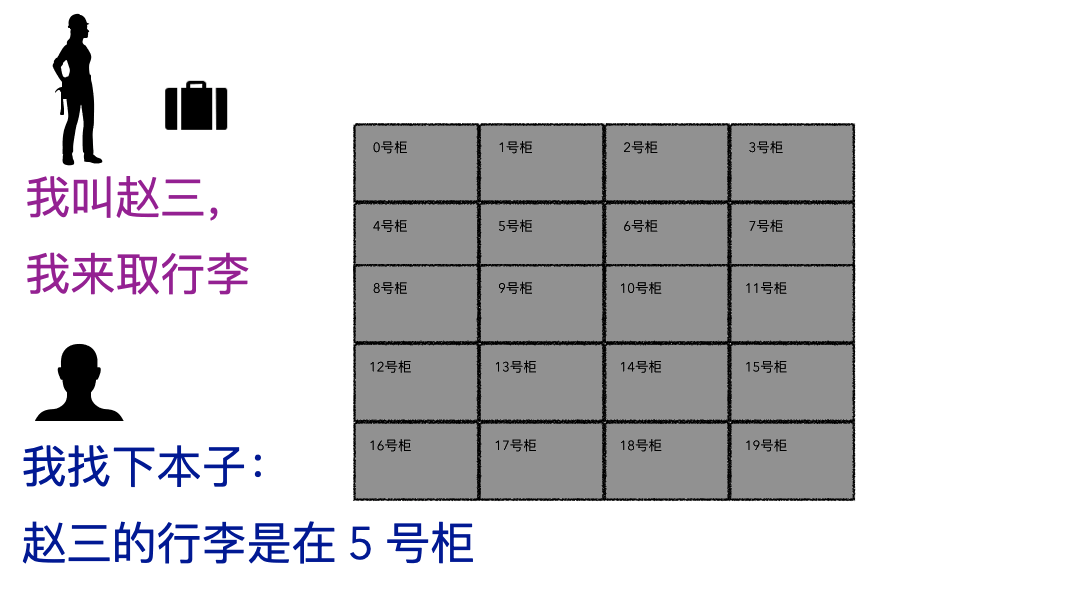
文件系统
登记名字就是在文件系统记录文件名; 生成的牌子就是元数据索引; 你的行李就是文件; 寄存室就是磁盘(容纳东西的物理空间); 管理员整套运行机制就是文件系统;
空间管理

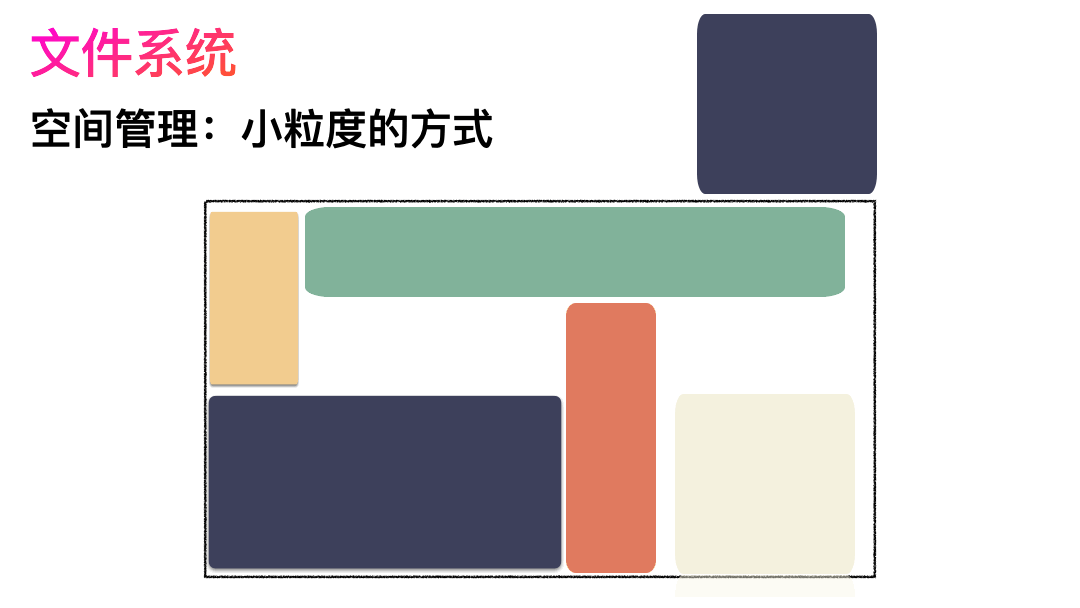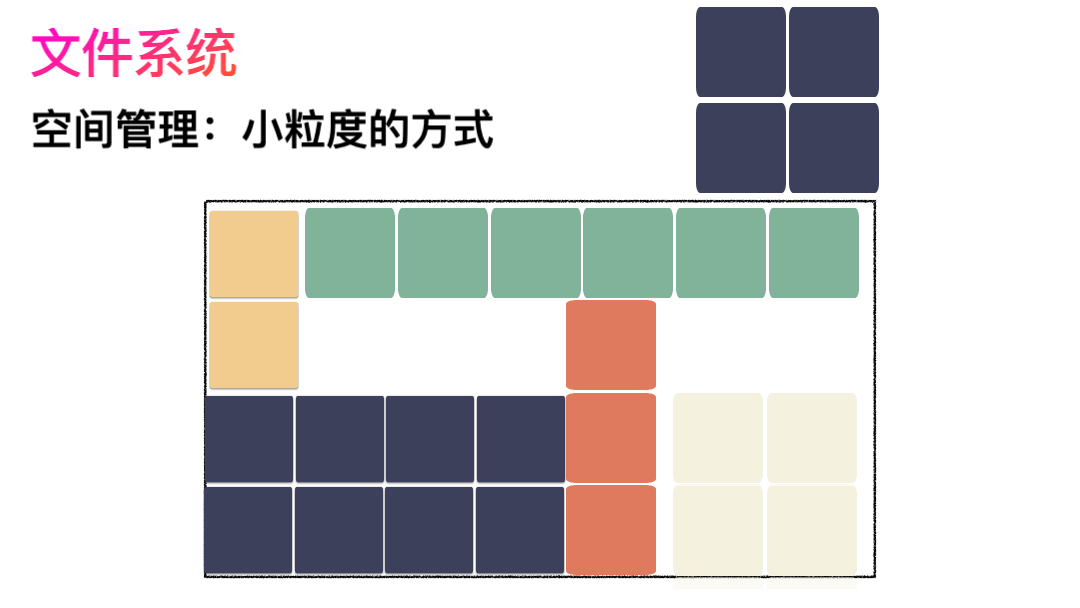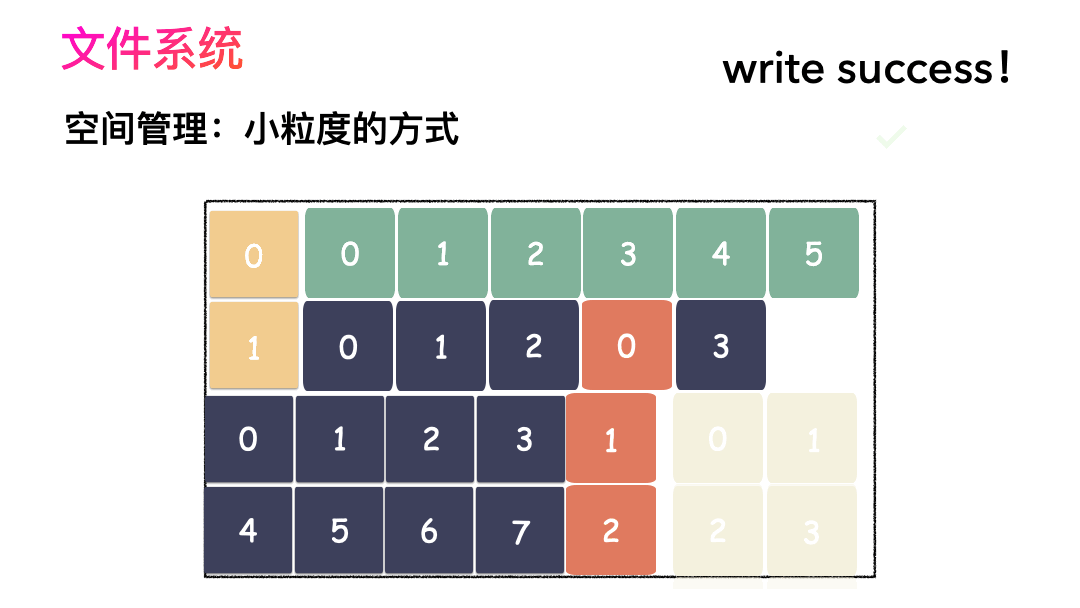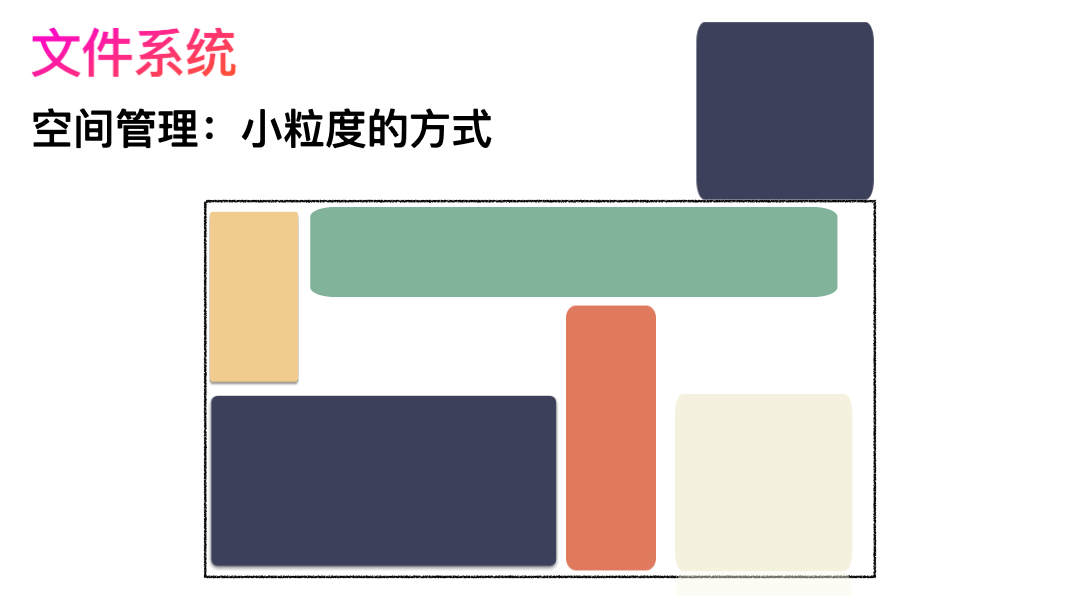
先写数据:数据先按照 Block 粒度存储到磁盘的各个位置; 再写元数据:然后把 Block 所在的各个位置保存起来,即inode(我用一本书来表示);
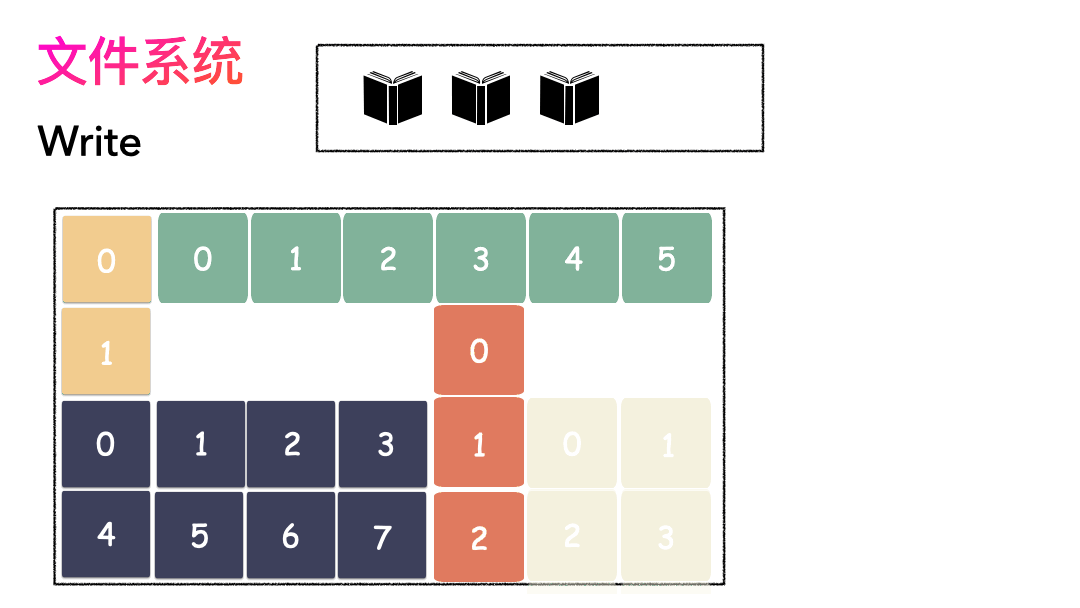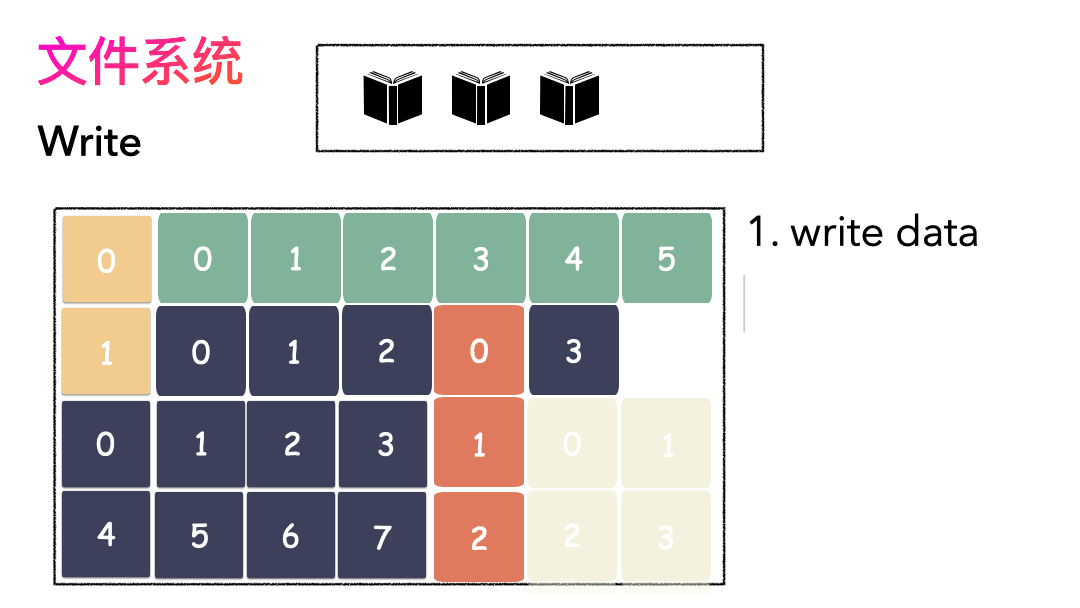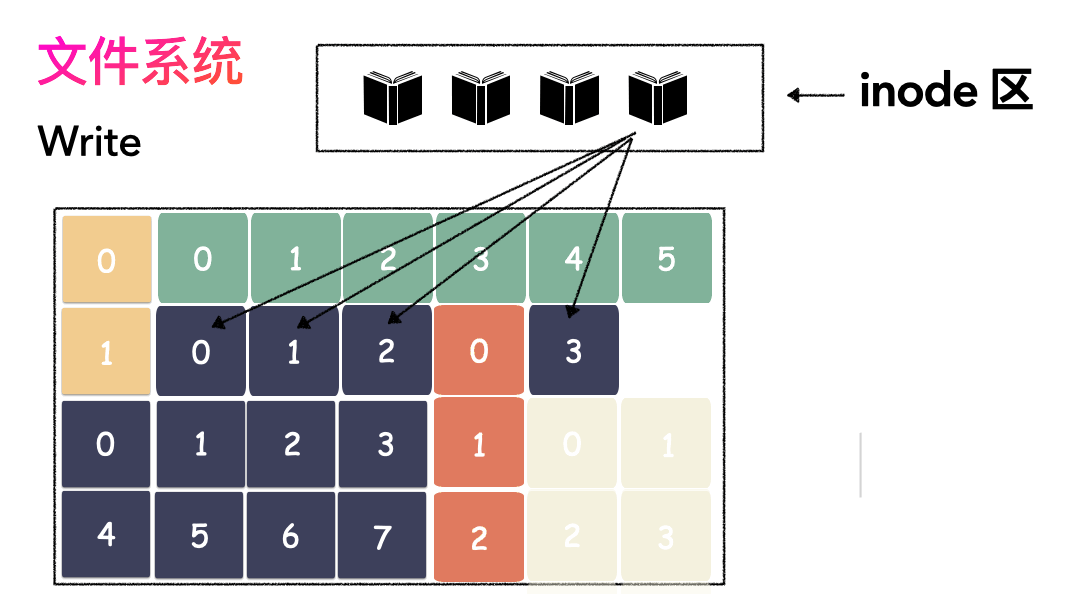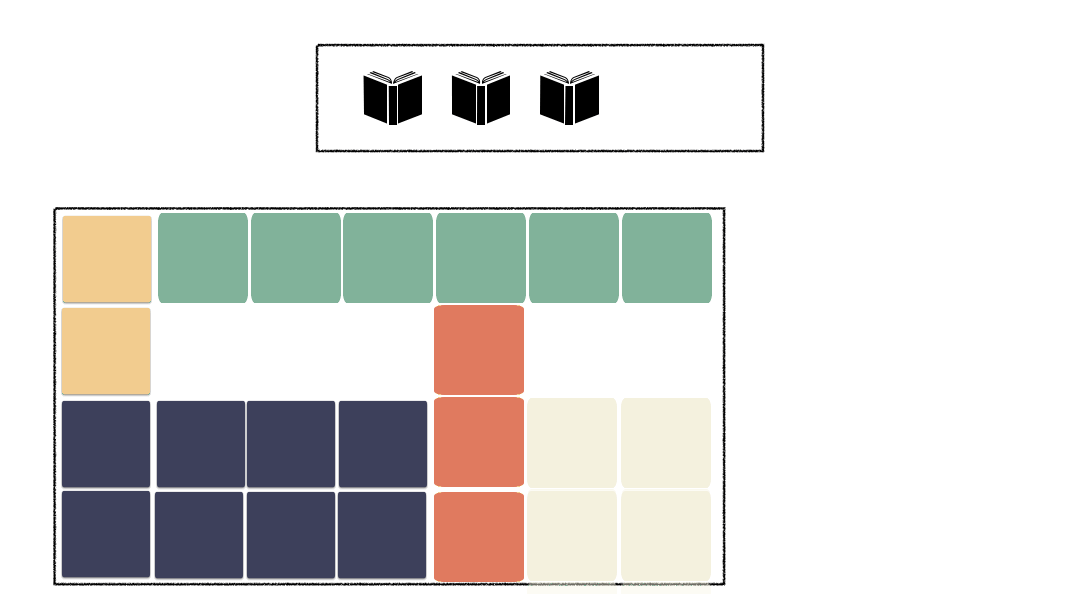
先读inode,找到各个 Block 的位置; 然后读数据,构造一个完整的文件,给到用户;
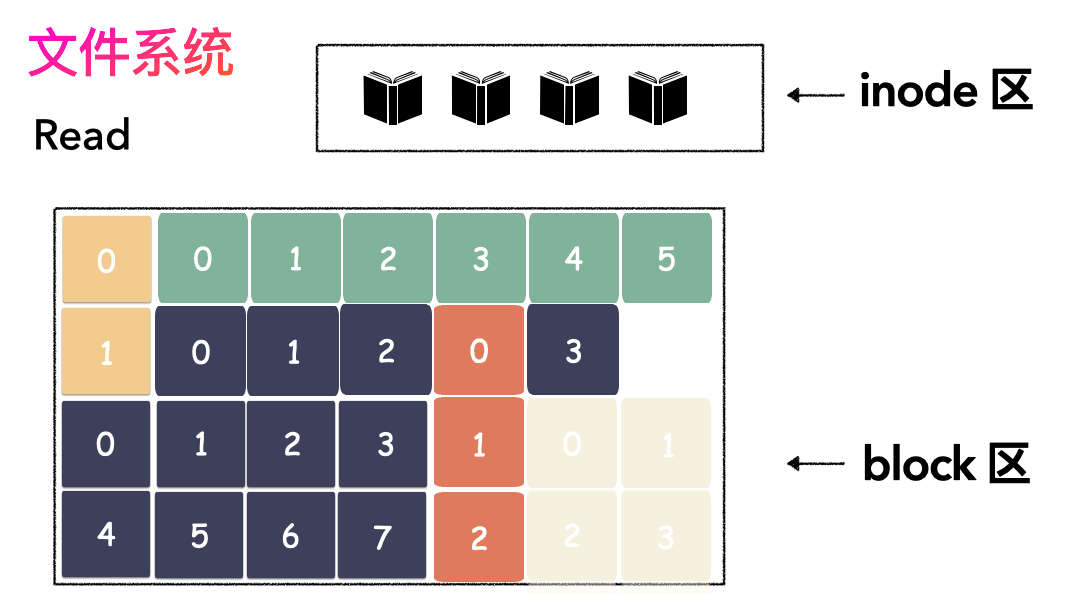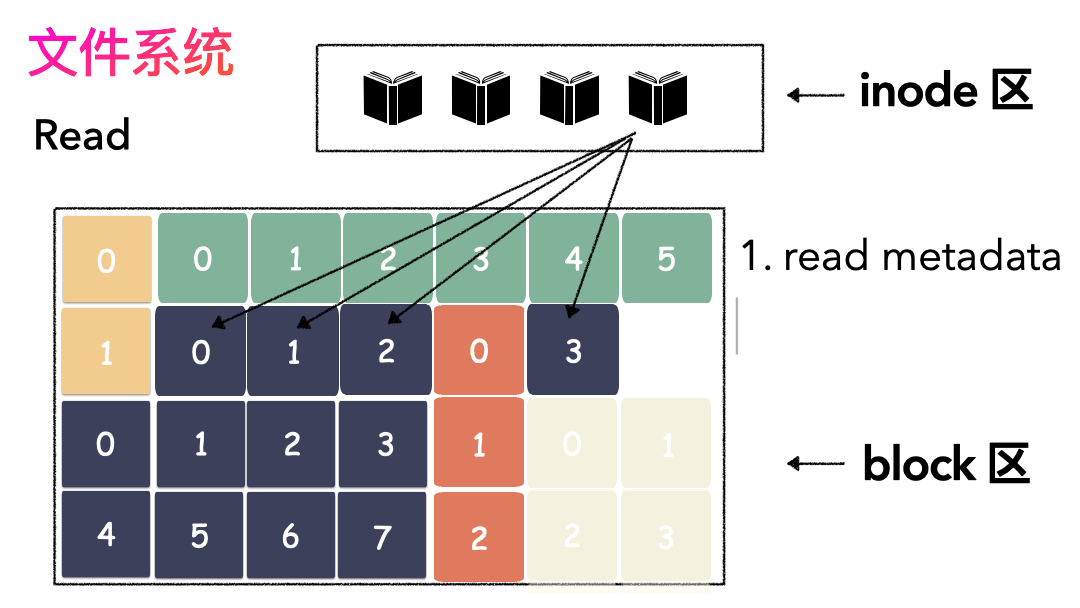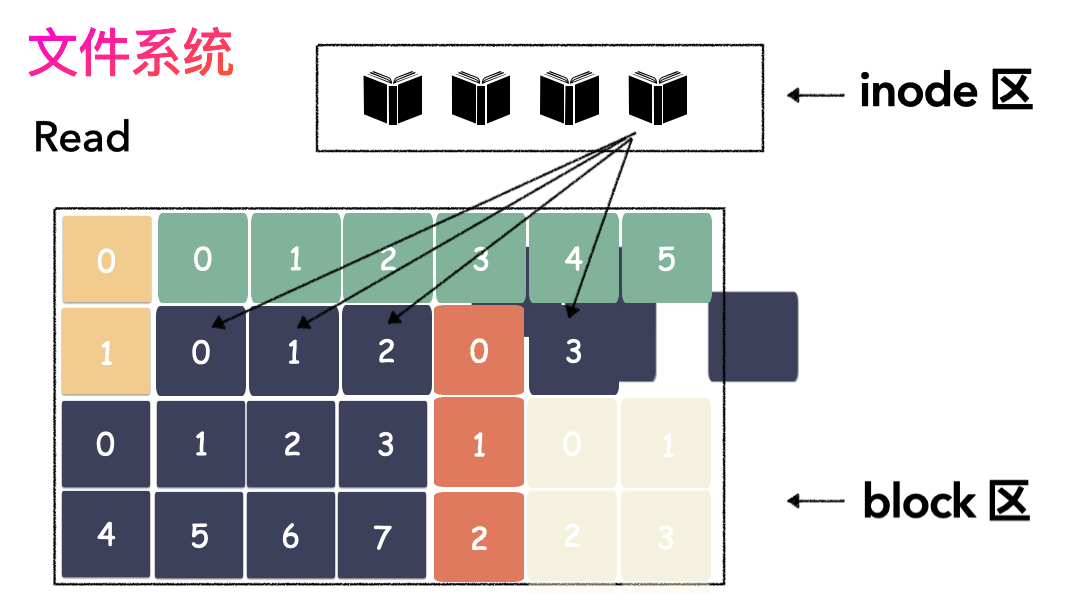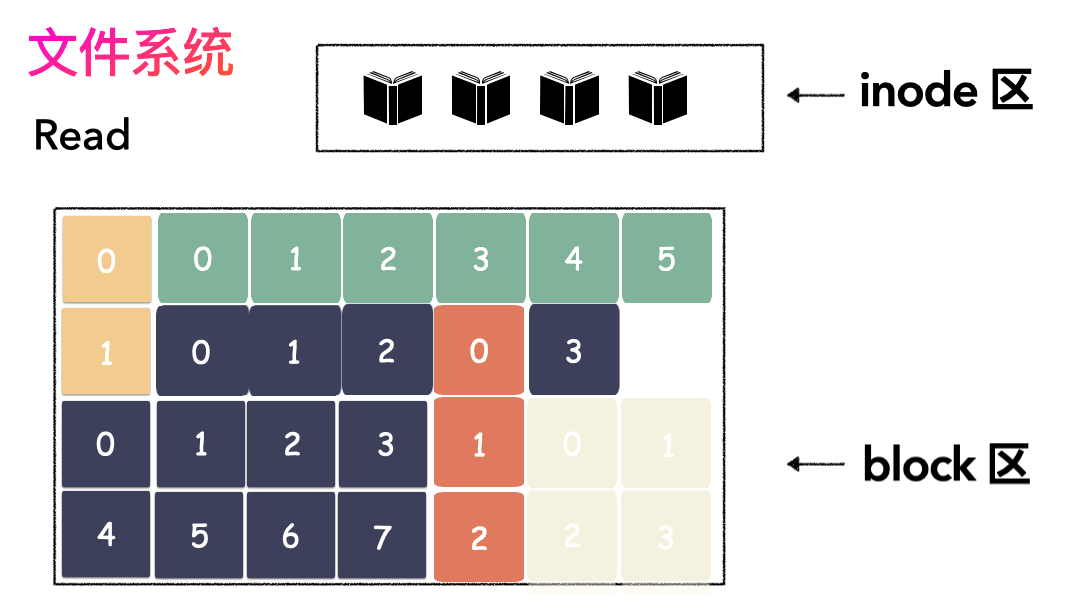
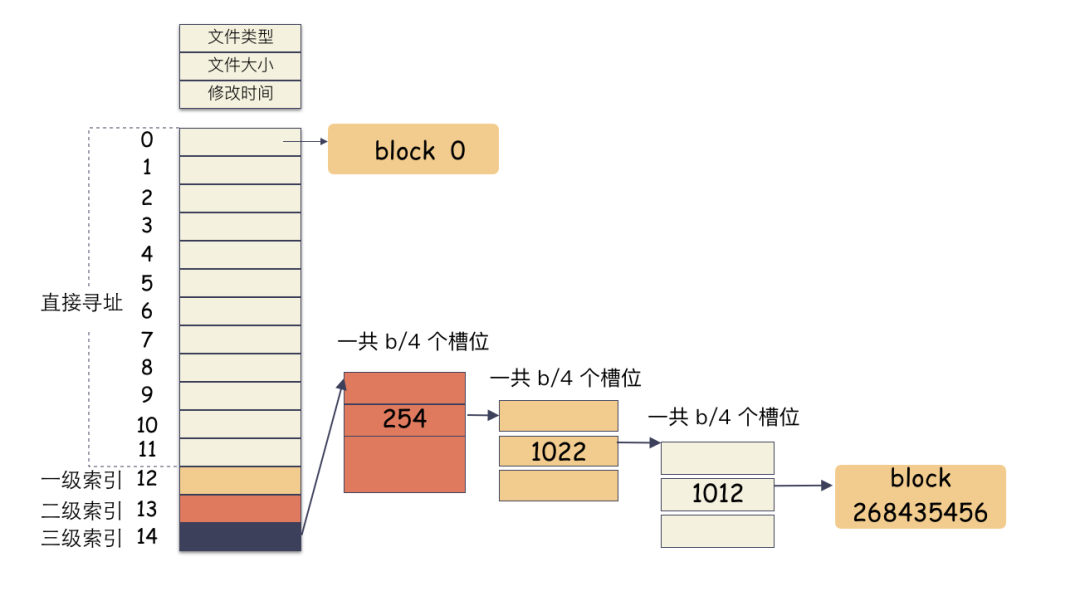
inode/block 概念
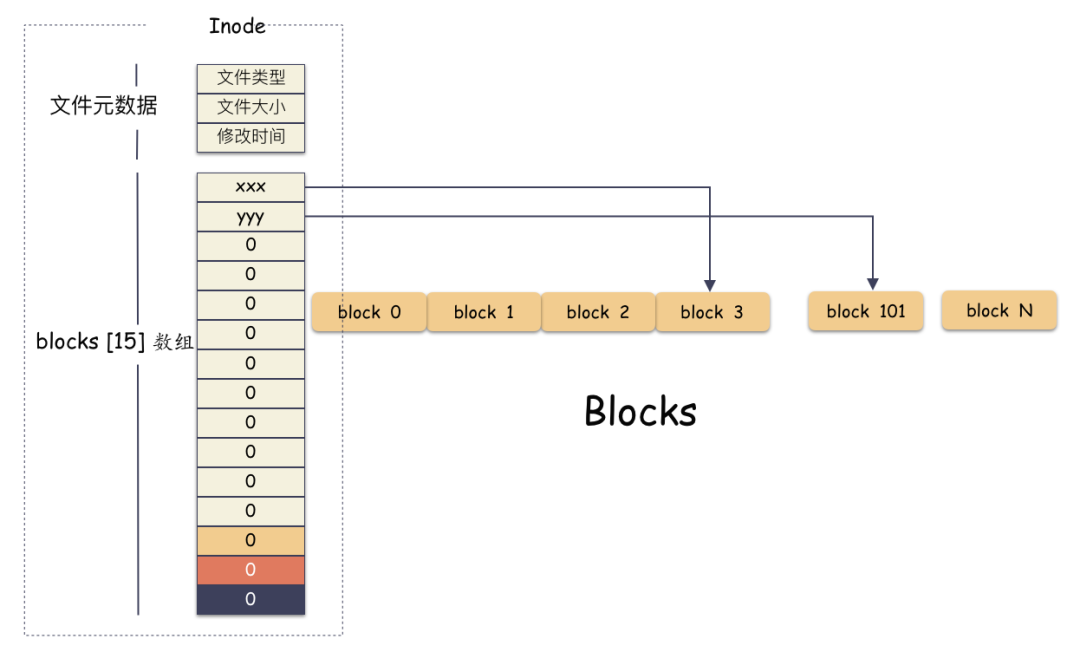
前 12 个槽位(也就是 0 - 11 )我们成为直接索引; 第 13 个位置,我们称为 1 级索引; 第 14 个位置,我们称为 2 级索引; 第 15 个位置,我们称为 3 级索引;

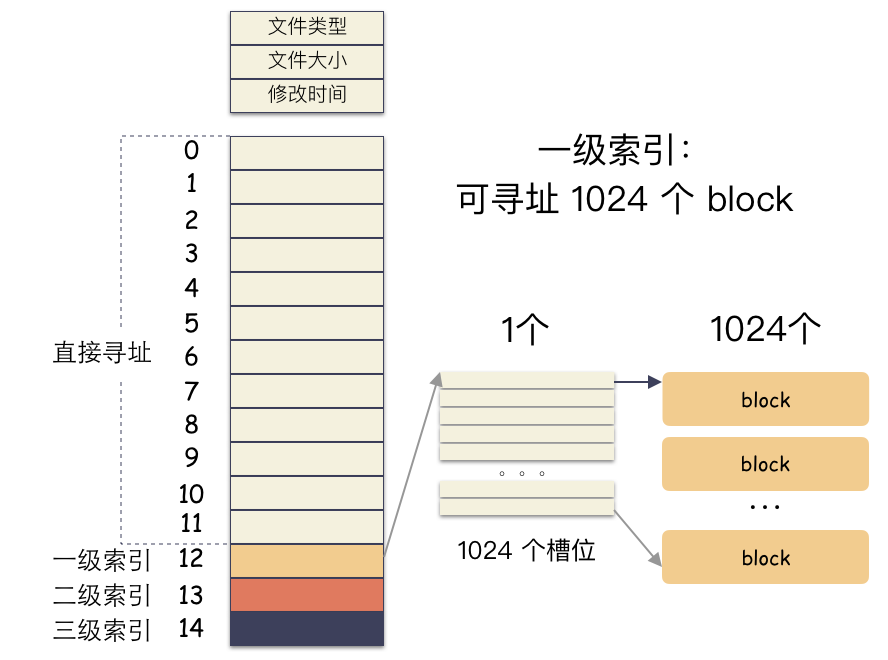
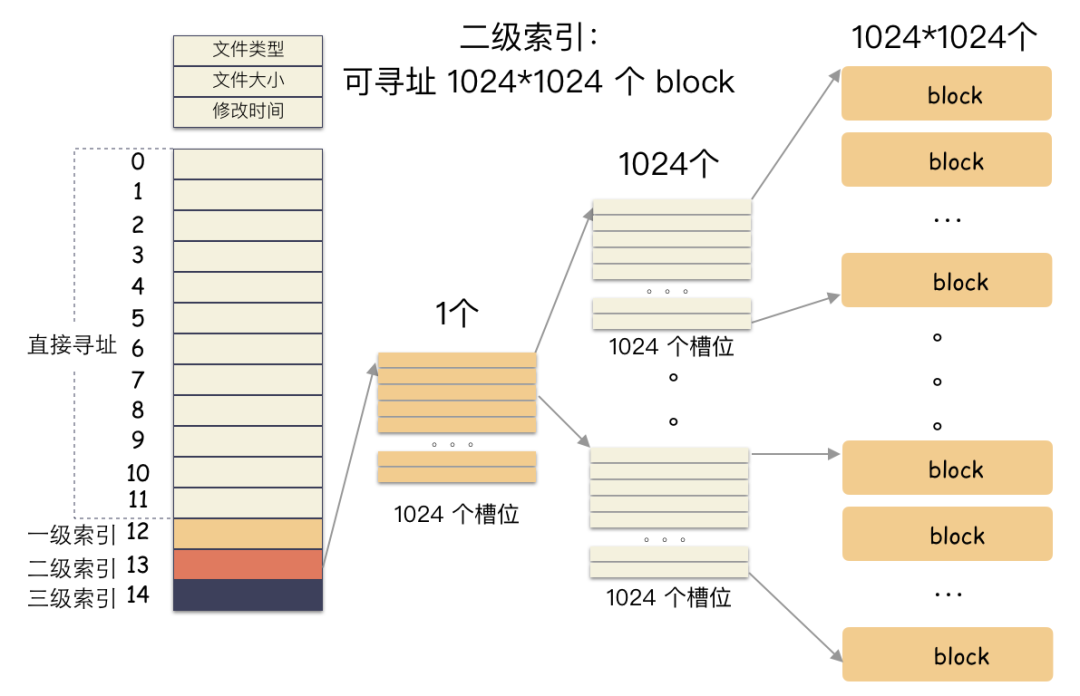
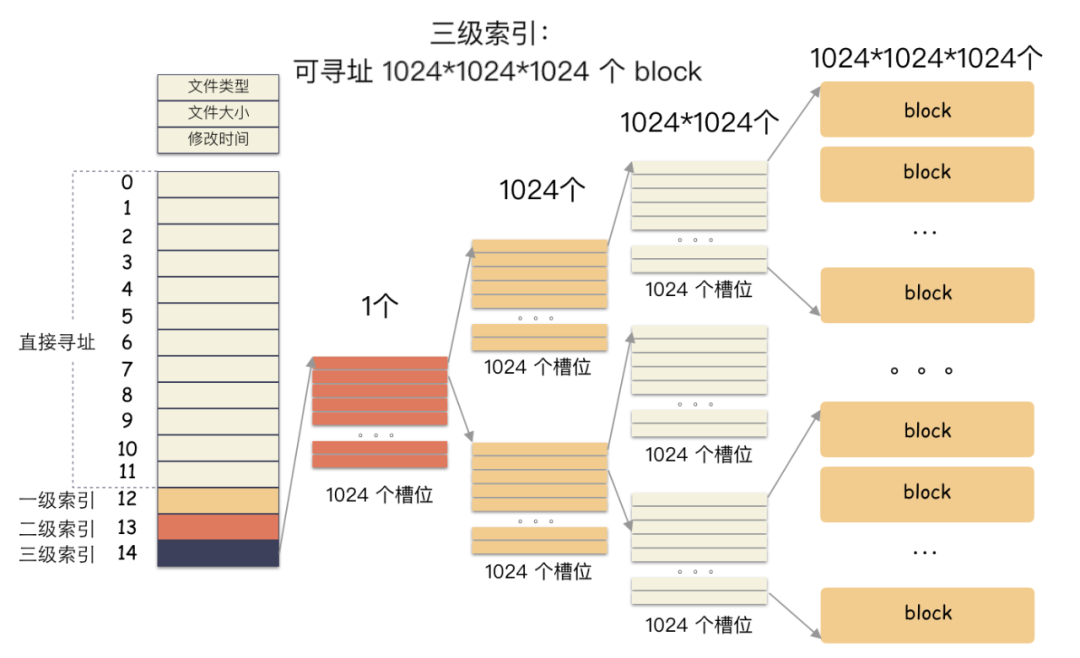
为什么cp那么快?
创建一个文件,这个时候分配一个 inode; 在 [ 0,4K ] 的位置写入 4K 数据,这个时候只需要 一个 block,把这个编号写到 block[0]这个位置保存起来;在 [ 1T,1T+4K ] 的位置写入 4K 数据,这个时候需要分配一个 block,因为这个位置已经落到三级索引才能表现的空间了,所以需要还需要分配出 3 个索引块; 写入完成,close 文件;
总结
首先,最关键的是把磁盘空间切成离散的、定长的 block 来管理; 然后,通过 inode 能查找到所有离散的数据(保存了所有的索引); 最后,实现索引块和数据块空间的后分配;







关注Java技术栈看更多干货

评论