
Python人工智能在贪吃蛇游戏中的运用与探索(下)
之前,我们简单的分析介绍了实现贪吃蛇的基本原理和工具,本篇我们将进一步用代码分析其具体的形成过程。传送门如下:
设置规则
首先,我们需要设计运行时弹出的框的大小,在已设环境中,初始化蛇的长度和宽度,以及蛇每次移动的距离。这里看个人喜好,不加以讲解。
接下来我们需要确定蛇如何运动,贪吃蛇中比较重要的就是控制蛇的方向,这里我们使用「随机函数」来设定了蛇的「方向」。定义了初始位置之后,我们用0到3四个数模拟上下左右。
如下我们假设「a=random.randint」(0,3)为0,这时我们设置它为向左走0到3个单位,此时定义方向为1。同理可以得到a另外三个取值的情况。
if a == 0:
self.X = deque([x_start, x_start - 1, x_start - 2, x_start - 3])
self.Y = deque([y_start, y_start, y_start, y_start])
init_dir = 1
模拟蛇吃果实的场景,吃到果实时,蛇的身体会增加一单位长度(增加多少随参数设定变化而不同),这时,我们可以等价看成「果实的坐标加入了整个蛇的坐标队列」,即只需把果实的坐标添加,再区分蛇头和身体即可。判定吃到果实后,分数增加50,果实刷新。
def eat_food(self, x_food, y_food):
self.X.appendleft(x_food)
self.Y.appendleft(y_food)
self.LENGTH += 1
self.MOVES += 100
def update(self, x_change, y_change):
# 更新贪吃蛇身体位置
for i in range(self.LENGTH - 1, 0, -1):
self.X[i] = self.X[i - 1]
self.Y[i] = self.Y[i - 1]
# 更新贪吃蛇头部位置
self.X[0] = self.X[0] + x_change
self.Y[0] = self.Y[0] + y_change
self.MOVES -= 1
if new_head_x == self.FOOD_X and new_head_y == self.FOOD_Y:
self.SNAKE.eat_food(self.FOOD_X, self.FOOD_Y) # 确认吃了食物
reward = 50 # 给予吃食物的奖励
food_eaten = True
def reset(self):
......
......
self.FOOD_X, self.FOOD_Y = self.get_randoms()接下来模拟蛇当场去世的情况。我们用坐标来模拟蛇,那么显然,当蛇的头位置与身体位置发生重合时,即判定扑街。同时,如果蛇头触碰了边界,我们同样判定其死亡。代码中我们会设置一个函数来判定,当其满足死亡条件时,将被赋值为False(训练时我们将结果存储在done[])。
def bit_itself(self):
for i in range(1, self.LENGTH):
if self.X[0] == self.X[i] and self.Y[0] == self.Y[i]:
return True
return False
def is_on_body(self, check_x, check_y, remove_last=True):
X, Y = self.X.copy(), self.Y.copy()
if remove_last: # 不考虑尾部
Y.pop()
for x, y in zip(X, Y):
if x == check_x and y == check_y:
return True
return False
if new_head_x < x1 or new_head_x > x2 or new_head_y < y1 or new_head_y > y2:
reward = -50
done = True
self.SNAKE.kill()def kill(self):
self.is_alive = False
此处我们涉及到了zip()函数,zip的功能主要是将涉及到的元素合并起来,这里通过将蛇身体的坐标的合并,可以轻松得到坐标列,当蛇头(x,y)正好在该列之中,即重合。
if action == 0:
if self.VELOCITY == 1: # 向右移动
x_change = 1
else:
x_change = -1 # 向左移动
update = True
......
具体的行动规则依照设定的上下左右的方式来决定。
到此我们完成了贪吃蛇设计的第一阶段。
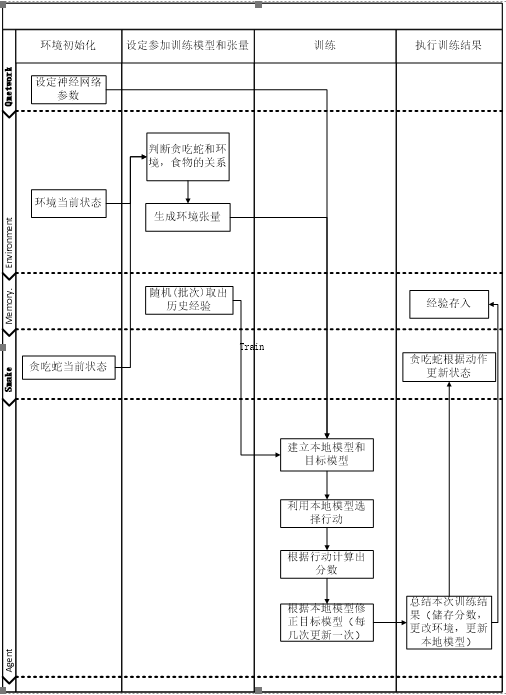
上图是贪吃蛇人工智能诞生,训练与运行的主要流程,我们将以该图流程为依据展开。
初始化环境
神经网络参数的设置
HIDDEN_UNITS = (32, 16, 32) # 神经网络隐藏层神经元数目
NETWORK_LR = 0.001 # 神经网络学习率
BATCH_SIZE = 64 # 训练批次
UPDATE_EVERY = 5 # 本地模型每训练5次更新
GAMMA = 0.95 # 强化学习中的折扣因子
NUM_EPISODES = 5000 # 最大迭代次数
def train():
agent = DeepQ_agent(env, hidden_units=HIDDEN_UNITS, network_LR=NETWORK_LR,
batch_size=BATCH_SIZE, update_every=UPDATE_EVERY, gamma=GAMMA) # 深度学习环境
......
折扣因子是估算未来的价值所需要的元素。在贪吃蛇中,我们需要大约确定未来几步的最优选择,而距离现在越远,其影响越小,即当我们计算rewards时,未来每一步的分数都会乘折扣因子的n次方。
环境状态设定
def reset(self):
# 初始化贪吃蛇和食物的位置
snake_x, snake_y = self.get_randoms(length=4)
self.SNAKE = Snake(snake_x, snake_y, self.WIDTH, self.HEIGHT)
self.VELOCITY = self.SNAKE.INITIAL_DIRECTION
self.FOOD_X, self.FOOD_Y = self.get_randoms()
self.STATE = self.SNAKE.look(self.FOOD_X, self.FOOD_Y,
self.get_boundaries())
return self.STATE
初始化蛇、果实的位置,方向,将其存储在state中(Q(s,a)的 s)
设定训练模型和张量
判断蛇和与环境的关系,生成环境张量
上面的代码块中的look就是机器判断环境的核心
def look(self, x_food, y_food, boundaries):
# 往上观察
up = self.lookInDirection(boundaries, y=-1, x=0)
......#左右等剩余七个观察
head_x, head_y = self.head_pos()
......
aa = np.hstack((food_position, up, up_right, right, down_right, down, down_left, left, up_left))
return np.hstack((food_position, up, up_right, right, down_right, down, down_left, left, up_left))
def lookInDirection(self, boundaries, y, x):
tail_distance = 0 # 0如果尾部不在这个方向
distance = 1 # 1是离墙的最小距离
curr_x, curr_y = self.head_pos()
check_x, check_y = curr_x + x, curr_y + y # 按照方向变化头部位置
x1, x2, y1, y2 = boundaries
while y1 <= check_y <= y2 and x1 <= check_x <= x2:
if tail_distance == 0 and (self.is_on_body(check_x, check_y,
remove_last=False)):
tail_distance = (1 / distance)
# 持续迭代
check_y += y
check_x += x
distance += 1
return np.array([1 / distance, tail_distance])
边界距离从行动后distance的迭代得到。通过对果实,边界距离、方向的计算与估计,确立出state。通过look出来的结果,将各种影响环境状态的因素用hstack合并,生成环境张量。
开始训练
建立本地和目标模型,并预估动作
self.qnetwork_local = QNetwork(input_shape=self.env.STATE_SPACE,
output_size=self.nA,
learning_rate=self.NETWORK_LR)
#print(self.qnetwork_local.model.summary())
#一个模型用于本地训练,另外一个模型随之更新权重
self.qnetwork_target = QNetwork(input_shape=self.env.STATE_SPACE,
output_size=self.nA,
learning_rate=self.NETWORK_LR)
self.memory = ReplayMemory(self.MEMORY_CAPACITY, self.BATCH_SIZE)
#使用本地模型估计下一个动作
target = self.qnetwork_local.predict(states, self.BATCH_SIZE)
#使用目标模型估计下一个动作
target_val = self.qnetwork_target.predict(
next_states, self.BATCH_SIZE)
target_next = self.qnetwork_local.predict(
next_states, self.BATCH_SIZE)用两个模型的优点和各自用途在(上)中已经讲到过,这里不再解释。
干货 | Python人工智能在贪吃蛇游戏中的应用探索(上)
计算分数
for i in range(self.BATCH_SIZE):
if dones[i]:
target[i][actions[i]] = rewards[i]
else:
target[i][actions[i]] = rewards[i] + self.GAMMA * \
target_val[i][max_action_values[i]
当蛇死掉,分数即为当前的分数。否则将继续迭代,但是预估的每个未来的行动都会乘以折扣因子。同时,在训练批次范围内的多次循环会得到一系列的rewards,其中的最大值就是我们预估出的最佳行动方式,我们以此会不断更新权重,使贪吃蛇更加智能。
执行训练
开始移动
def act(self, state, epsilon): #设置epsilon默认为0
state = state.reshape((1,)+state.shape)
action_values = self.qnetwork_local.predict(
state)
if random.random() > epsilon:
#选择最好的行动
action = np.argmax(action_values)
else:
#选择随机的行动
action = random.randint(0, self.nA-1)
return action
行动的时候有两种情况。此处我们设置了epsilon(取0.1),并取(0,1)随机数,当大于epsilon时则按照rewards最大的经验行动。当小于时,则会随机采取一次行动,同时epsilon会乘以一个系数,直到设定的最小值(我们设置了0.01)。这样做的目的,是为了在刚开始训练时,快速积累行动经验,加快人工智能的进步。同时,随着无数次的训练,权重的不断更新,蛇的行动会越来越准确。
存储与提取经验
def add_experience(self, state, action, reward, next_state, done):
self.memory.add(state, action, reward, next_state, done)
def add(self, state, action, reward, next_state, done):
'''把经验存储起来'''
e = tuple((state, action, reward, next_state, done))
def sample(self, state_shape):
experiences = random.sample(self.memory, k=self.BATCH_SIZE)
# 提取反馈信息
states, actions, rewards, next_states, dones = zip(*experiences)
def learn(self):
if self.memory.__len__() > self.BATCH_SIZE:
states, actions, rewards, next_states, dones = self.memory.sample(
self.env.STATE_SPACE)当经验组数量大于训练批次后,每次我们都会提取出64组(训练批次数量)的经验,来得到相应的action。
model_arch = '2019816'
resume_model_path = model_out_dir + '/snake_dqn_2019815_final.h5'
agent.qnetwork_local.model = load_model('F://贪吃蛇//SnakeAI-master//agents_models//snake_dqn_2019816_3000.h5')
这一步是人工智能贪吃蛇的关键步骤,「我们定义训练模型的路径,并在正式运行时调用。该训练文件会存入训练生成神经网络模型的权重。当我们运行时会调用该文件中的权重。如果该路径下没有已有的训练文件,那么训练生成的权重就会存入。如果想要重新训练,我们就要删除并重新定义这一路经。」
这里的原理是「通过神经网络的无数次训练来调整权重。当贪吃蛇训练时遇到新环境,根据已有模型,预测一个接近的结果向量来选择最好的方式移动。训练环境也会逐渐扩大(训练环境与遇到的环境不是一个),当达到训练批次时就会固定。」
总流程如下
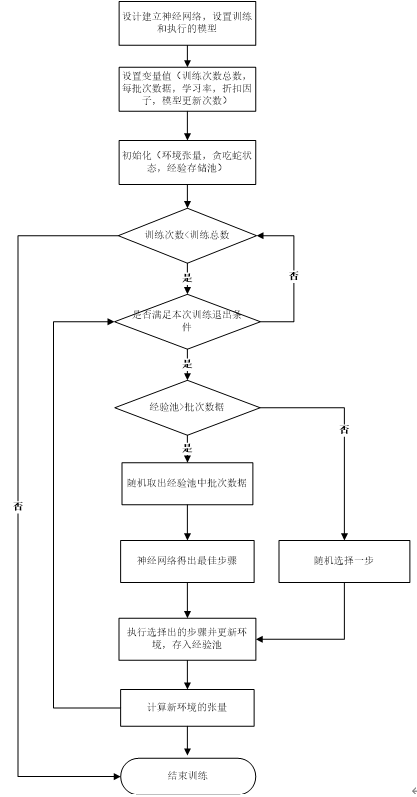
自此,贪吃蛇人工智能的介绍结束。
干货 | Python人工智能在贪吃蛇游戏中的应用探索(上)
「参考文献:」
贪吃蛇代码
源代码作者:齐浩洋(香港城市大学数据科学学院)
文案 && 编辑:白宇啸(华中科技大学管理学院)
审稿&&修正:齐浩洋(香港城市大学数据科学学院)
指导老师:秦虎(华中科技大学管理学院)
如对文中内容有疑问,欢迎交流。
如有需求,可以联系:
秦虎老师(professor.qin@qq.com)
白宇啸(华中科技大学管理学院本科一年级:291666597@qq.com)
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
记得点个在看支持下哦~
