
西安健康码崩了!随便聊聊
共 1887字,需浏览 4分钟
·
2022-01-12 16:52

事件描述
事情大致是这样的,去年 12 月 20 日和今年的 1 月 4 日,短短两周内,西安一码通程序崩了两次,导致市民无法扫码亮码,只能在寒风中排队等候。
官方的解释是:短期用户访问量激增,大概是正常访问量的 10 倍以上,导致网络阻塞、系统崩溃。
于是,名场面来了:
“时任西安市大数据局局长刘军参加发布会并回应称,西安市一码通使用频率加大,对网络与平台造成较大压力,在全员核酸检测的特殊时期,为减轻系统压力,建议广大市民 非必要不展码、亮码 ,在出现系统卡顿时,请耐心等待, 尽量避免反复刷新 。”
虽然听上去挺合理的,但总感觉哪里不太对劲。。。
人类为一个小系统让步?上千万人为几个搞系统的小团队让步?真就 “非必要时不亮码,必要时码不亮” 了。
据说后来,该局长被停职检查。。。
总之,在疫情形势不容乐观的情况下,这个事故的严重程度可以说是 P0 级了。
技术分析
那么事情是否真的如官方所说,是由于网络阻塞导致的系统崩溃呢?
先说说什么是网络阻塞。打个比方,把用户的访问流量想象成往小水管中注水,如果流量突然激增,出水口太小来不及排水,水就流不动了。
怎么解决网络阻塞呢?一种最常见的方案是对网络进行 扩容 。
提到扩容,最简单粗暴的方式是,换个粗水管,就能应对更大的突发流量。但如果平时流量用小水管就能应对,这样改造就会很浪费资源。
除了这种方式外,其实有非常多优秀的扩容方案。比如之前看过美团的一个分享,在某业务访问的高峰期(比如中午 12 点的外卖系统),系统会自动协调其他非高峰期业务的部分资源给该业务,从而保证总资源有限的情况下,顺利扛过流量高峰。
所以,如果健康码第一次的崩溃是因为网络阻塞,按道理来说除了这么大的事故肯定会吸取教训,对网络进行 扩容 等措施的,如果做了扩容,第二次的崩溃就不应该再甩锅给网络了。但现实恰恰相反,第二次崩溃依然宣称是网络阻塞,那我肯定是不信了。
而且有了第一次的经验,第二次又遇到了同样的网络阻塞问题,真的要修复好几个小时么?

此外,事故发生之后,程序明显发生了 回滚 ,界面恢复成了几个月前的样子!
说到回滚,我就来劲了,这种事我干的太多了,大多数情况下,都是写了 Bug 影响到线上项目了,才会做这个操作。

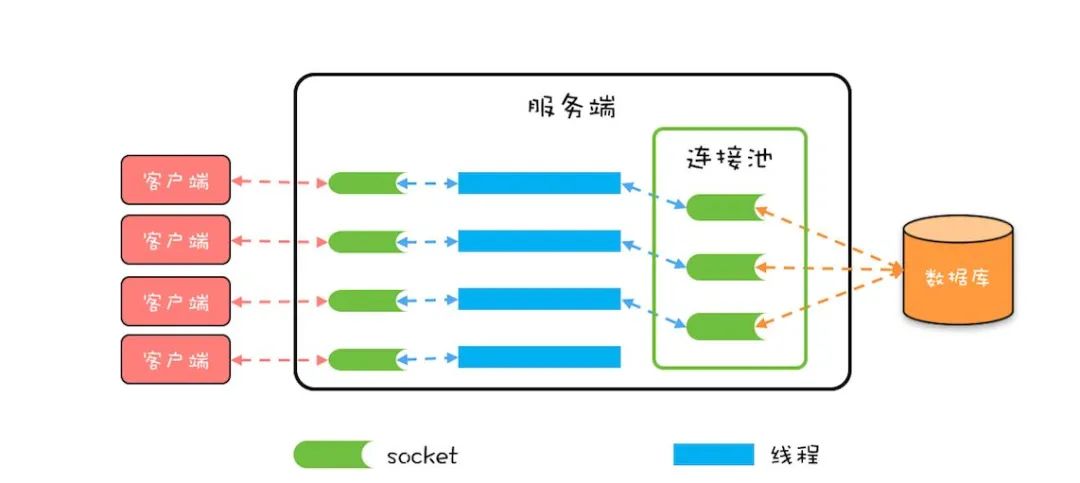
所以我猜测一码通的崩溃,肯定和系统之烂脱不开关系。既然官方称数据库还能正常运行,那么大概率是业务层代码自身出了问题。
比如本来页面很简洁,只需要从服务器查询健康码信息(根据用户 N 天内的行为进行综合计算而成),而一码通新版本又多了核酸检测情况等一些额外的信息查询,所以就增加了单次数据库查询的耗时,占用数据库连接更久、释放得更晚。请求很多的情况下,数据库连接很快就被占满了,导致新的请求都要一直排队等待可用的数据库连接,直到等待超时。
举个例子,本来食堂提供两菜一汤,大家排队去食堂打饭,每个人要花 20 秒。后来食堂突然提供了烤腰子,大家又要多打一道菜,比原来多花 10 秒,队伍移动慢了,就导致后面的队越排越长,直到把食堂堵死。
当然,也有可能是数据库里又多了大量数据,导致查询时间变长。打个比方就是食堂提供了更多菜品,大家挑选的时间更久了。
要解决这个问题,就要定位请求究竟在哪个环节等待,是数据库连接池的最大连接数不足、还是数据库本身的最大连接数不足等。常见的手段就是调整连接数参数、或者对应用进行扩容。
当然这只是我的猜测~
尾声
最后,我从网上了解到,大部分区域的一码通,其实都是由腾讯和阿里免费提供的。但西安不一样,它的一码通,是由当地政府部门招标搭建的,而且还是在三天内研发出来的!
因此,我觉得这次事故需要背锅的人和团队真的太多了,下到写 Bug 的开发者、设计系统的架构师、保障系统的运维同学,上到各公司和政府部门的领导决策者等等。西安不像其他省份一样用全国统一、相对更稳定的健康码也就算了(本地数据管理方便些),但究竟是谁给了你们勇气不对 仅花三天就上线 、上千万人使用 的系统进行压力测试和容灾演练的?
虽然我不是这件事的受害者,不过光是让我想像一下这么多人大冬天里排队等系统修复的场景,我就真的是很气愤了!
当然,如果这件事情真的是天灾,就当我在扯犊子吧。
大概是这样,就随便聊聊,希望以后自己设计系统时能长点心,尽量不要因为自己的失误影响到其他人。
共勉!