
Python 标准库中最有用的装饰器
众所周知,Python 语言灵活、简洁,对程序员友好,但在性能上有点不太令人满意,这一点通过一个递归的求斐波那契额函数就可以说明:
def fib(n):
if n <= 1:
return n
return fib(n - 1) + fib(n - 2)
在我的 MBP 上计算 fib(40) 花费了 33 秒:
import time
def main():
start = time.time()
result = fib(40)
end = time.time()
cost = end - start
print(f"{result = } {cost = :.4f}")
if __name__ == '__main__':
main()
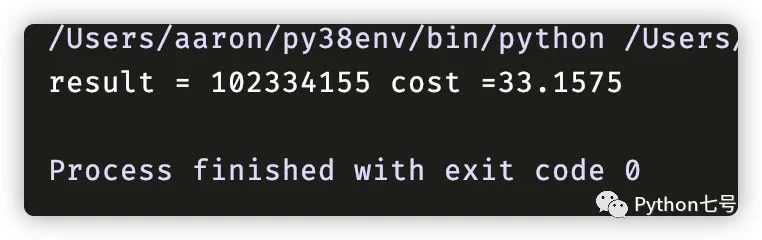
但是,假如使用标准库中的这个装饰器,那结果完全不一样
from functools import lru_cache
@lru_cache
def fib(n):
if n <= 1:
return n
return fib(n - 1) + fib(n - 2)
这次的结果是 0 秒,你没看错,我保留了 4 位小数,后面的忽略了。
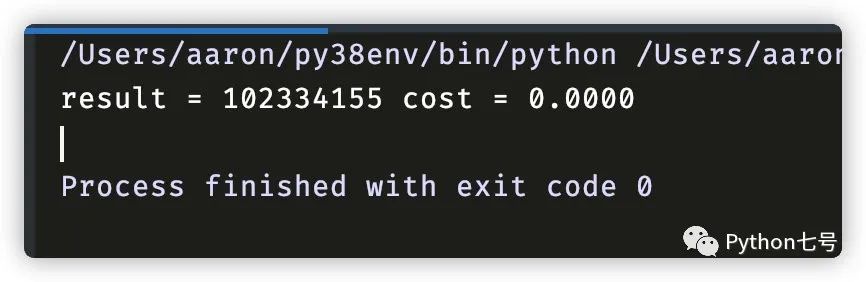
提升了多少倍?我已经计算不出来了。
关于装饰器,如果还不是很熟悉的话,可以看下这两篇文章:
为什么 lru_cache 装饰器这么牛逼,它到底做了什么事情?今天就来聊一聊这个最有用的装饰器。
如果看过计算机操作系统的话,你对 LRU 一定不会陌生,这就是著名的最近最久未使用缓存淘汰算法。
而 lru_cache 就是这个算法的具体实现。(这个算法可是面试经常考的哦,有的面试官要求现场手写代码)
现在,我们来看一个 lru_cache 的源代码,其中的英文注释,我已经为你翻译为中文:
def lru_cache(maxsize=128, typed=False):
"""LRU 缓存装饰器
如果 *maxsize* 是 None, 将不会淘汰缓存,缓存大小也不做限制
如果 *typed* 是 True, 不同类型的参数将独立做缓存,比如 f(3.0) and f(3) 将认为是不同的函数调用而缓存在两个缓存节点上。
函数的参数必须可以被 hash
查看缓存信息使用的是命名元组 (hits, misses, maxsize, currsize)
查看缓存信息:user_func.cache_info(). 清理缓存信息:user_func.cache_clear().
LRU 算法: http://en.wikipedia.org/wiki/Cache_replacement_policies#Least_recently_used_(LRU)
"""
# lru_cache 的内部实现是线程安全的
if isinstance(maxsize, int):
# 负数转换为 0
if maxsize < 0:
maxsize = 0
elif callable(maxsize) and isinstance(typed, bool):
#如果被装饰的函数(user_function)直接通过 maxsize 参数传入
user_function, maxsize = maxsize, 128
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
elif maxsize is not None:
raise TypeError(
'Expected first argument to be an integer, a callable, or None')
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
return decorating_function
这里面有两个参数,一个是 maxsize,表示缓存的大小,当传入负数时,自动设置为 0,如果不传入 maxsize,或者设置为 None,表示缓存没有大小限制,此时没有缓存淘汰。还有一个是 type,当 type 传入 True 时,不同的参数类型会当作不同的 key 存到缓存当中。
接下来,lru_cache 的核心在这个函数上 _lru_cache_wrapper,建议有感情的阅读、背诵并默写。我们来看下它的源代码
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
# 所有 lru cache 实例共享的常量:
sentinel = object() # 用来表示缓存未命中的唯一对象
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
cache = {}
hits = misses = 0
full = False
cache_get = cache.get # 绑定函数来获取缓存中 key 的值
cache_len = cache.__len__ # 绑定函数获取缓存大小
lock = RLock() # 因为链表上的更新是线程不安全的
root = [] # 循环双向链表的根节点
root[:] = [root, root, None, None] # 初始化根节点的前后指针都指向它自己
if maxsize == 0:
def wrapper(*args, **kwds):
# 没有缓存,仅更新统计信息
nonlocal misses
misses += 1
result = user_function(*args, **kwds)
return result
elif maxsize is None:
def wrapper(*args, **kwds):
# 仅仅排序,不考虑排序和缓存大小限制
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
else:
def wrapper(*args, **kwds):
# 大小有限制,并跟踪最近使用的缓存
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed)
with lock:
link = cache_get(key)
if link is not None:
# 缓存命中,将命中的缓存移动到循环双向链表的头部
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
# 走到这里说明 key 已经放在了缓存,且锁已经释放了,链表已经更新了,这里什么也不需要做了,最后只需要返回计算的结果就可以了。
pass
elif full:
# 如果缓存满了, 使用最老的根节点来存储新节点就可以了,链表上不需要删除(是不是很聪明)
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
# 最后,我们需要从缓存中清除这个 key,因为它已经无效了。
del cache[oldkey]
# 新值放入缓存
cache[key] = oldroot
else:
# 如果没有满,将新的结果放入循环双向链表的头部
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
# 使用 cache_len 绑定方法而不是 len() 函数,后者可能会被包装在 lru_cache 本身中
full = (cache_len() >= maxsize)
return result
def cache_info():
"""报告缓存统计信息"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""清理缓存信息"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
wrapper.cache_info = cache_info
wrapper.cache_clear = cache_clear
return wrapper
如果我写的注释你都看明白了,那也不用看我下面的废话了,如果还有点不太明白,我啰嗦几句,也许你就明白了。
第一、所谓缓存,用的仍然是内存,为了快速存取,用的就是一个 hash 表,也就是 Python 的字典,都是在内存里的操作。
cache = {}
第二、如果 maxsize == 0,就相当于没有使用缓存,每调用一次,未命中数就 + 1,代码逻辑是这样的:
def wrapper(*args, **kwds):
nonlocal misses
misses += 1 # 未命中数
result = user_function(*args, **kwds)
return result
第三、如果 maxsize == None,相当于缓存无限制,也就不需要考虑淘汰,这个实现非常简单,我们直接在函数中用一个字典就可以实现,比如说:
cache = {}
def fib(n):
if n in cache:
return cache[n]
if n <= 1:
return n
result = fib(n - 1) + fib(n - 2)
cache[n] = result
return result
运行时间:
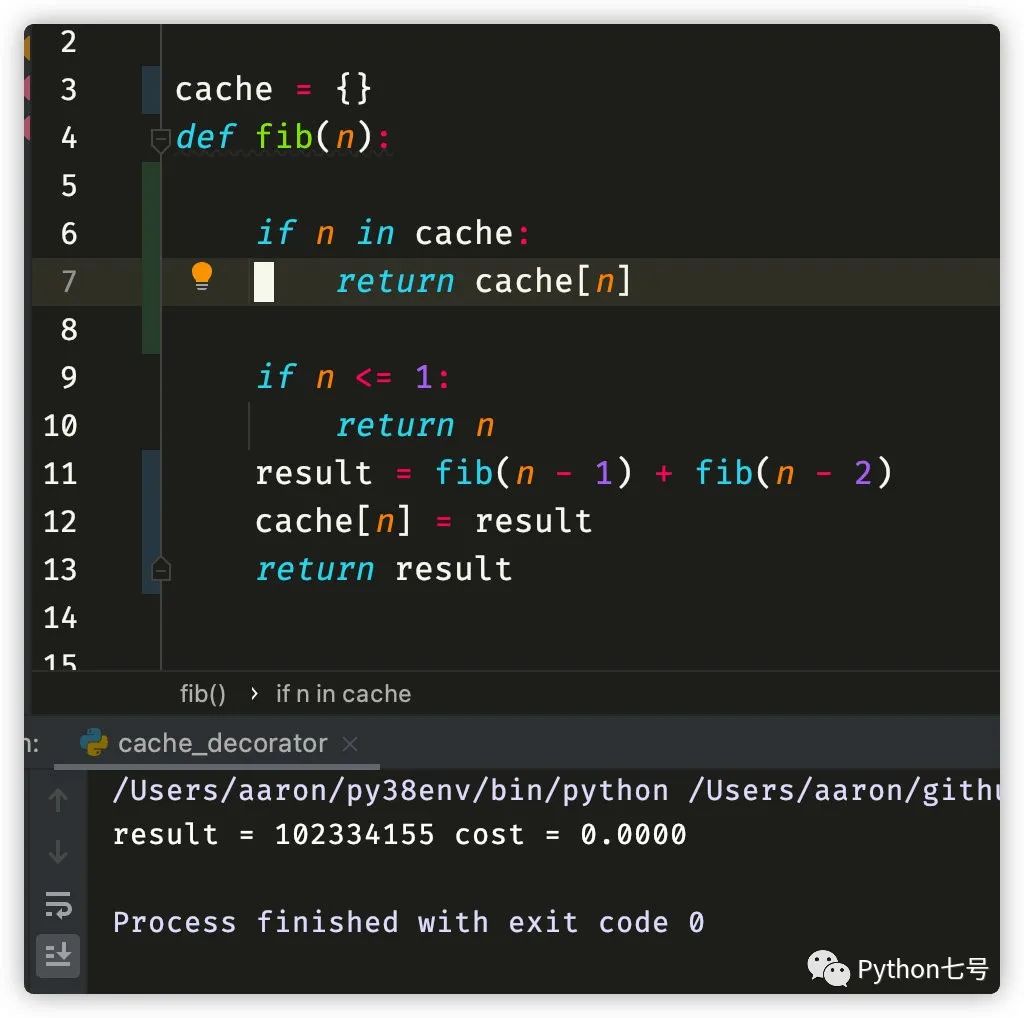
理解了这一点,在装饰器中,这段逻辑就不难看懂:
def wrapper(*args, **kwds):
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
第四、真正的缓存淘汰算法。
为了实现缓存(键值对)的淘汰,我们需要对缓存按时间进行排序,这就需要用到链表,链表的头部是最新插入的,尾部是最老插入的,当缓存数量已经达到最大值时,我们删除最久未使用的链尾节点,为了不删除链尾,我们可以使用循环链表,当缓存满了,直接更新链尾节点赋值为新节点,并把它做为新的链头就可以了。
当缓存命中时,我们需要把这个节点移动到链表的头部,保证链表的头部是最近经常使用的,为了移动方便,我们需要双向链表。
双向循环链表在 Python 中实现,可以简单的这么写:
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
root = [] # root of the circular doubly linked list
root[:] = [root, root, None, None] # initialize by pointing to self
可能有些朋友看不懂最后那行代码:root[:] = [root, root, None, None],画个图你就理解了:
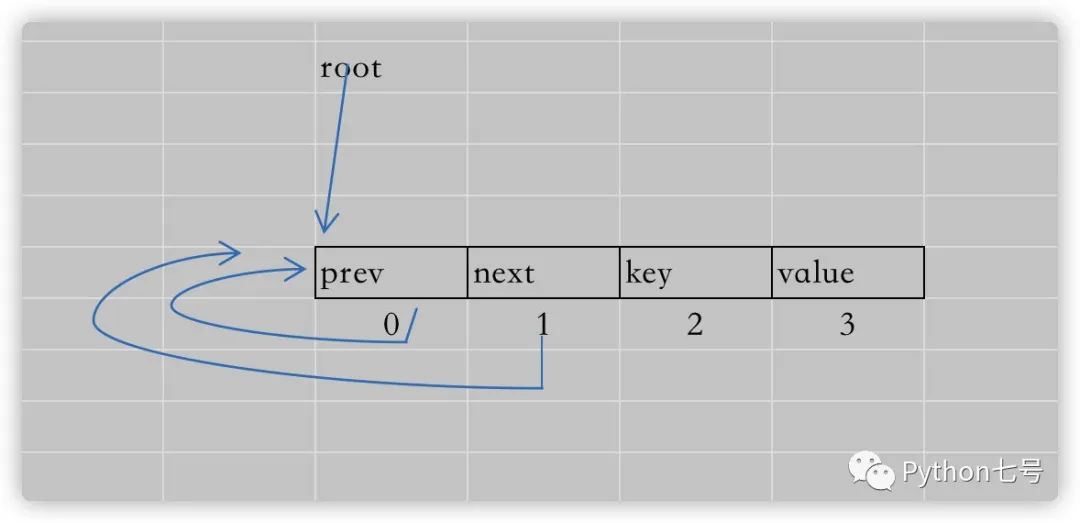
这些箭头指向的都是节点的内存地址,随着节点的增多,就是这个样子的:
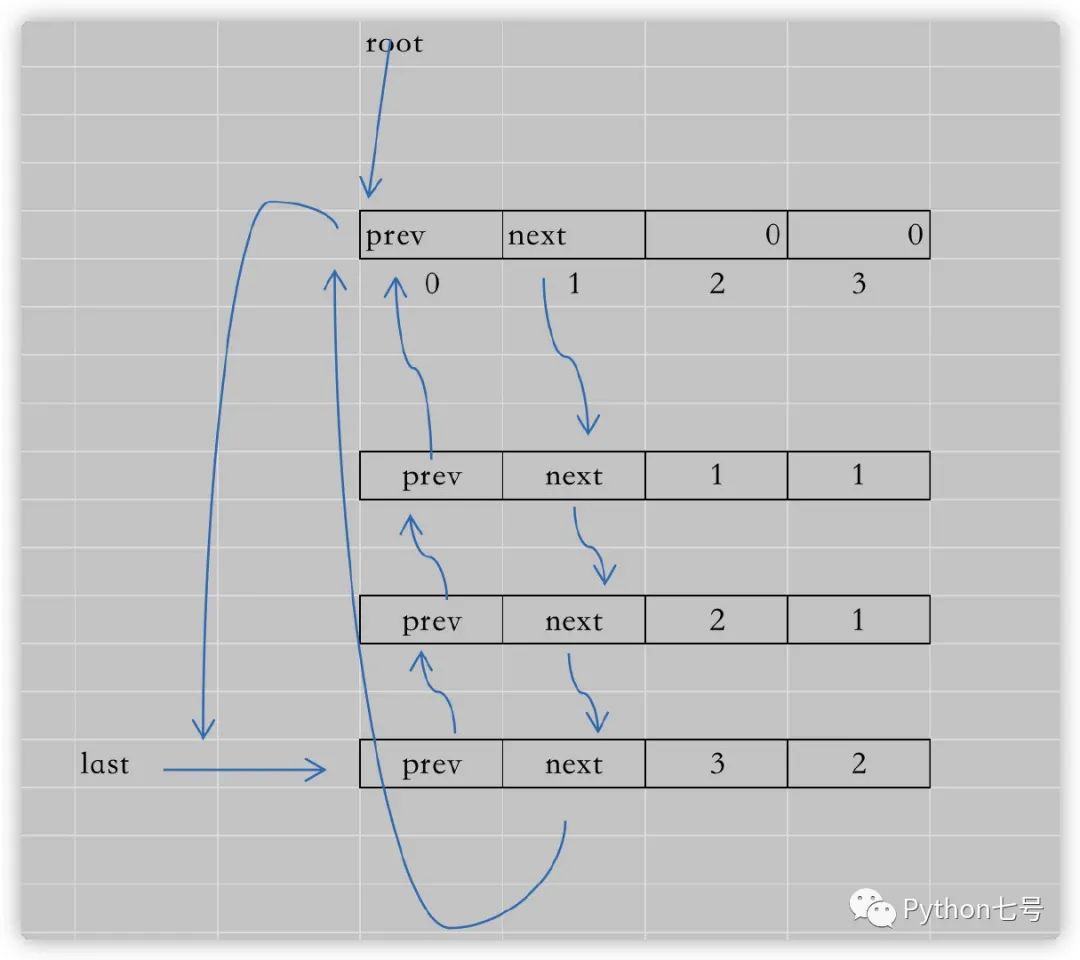
对比这个图,再看源代码,就很容易看懂了。尤其是这块的代码逻辑,是面试常考的重点,如果你能手写出这样线程安全的 LRU 缓存淘汰算法,那无疑是非常优秀的。
其他 LRU 算法的实现
其他关于 LRU 算法的实现,我自己写了两个,可以看这里:
LRU 缓存淘汰算法-双链表+hash 表[1]
LRU 缓存淘汰算法-Python 有序字典[2]
最后的话
装饰器 lru_cache 的作用就是把函数的计算机结果保存下来,下次用的时候可以直接从 hash 表中取出,避免重复计算从而提升效率,简单点的,直接在函数中使用个字典就搞定了,复杂点的,请看 lru_cache 的代码实现。另一方面,递归函数慢的一个主要原因就是重复计算。
Python 标准库的源码,是学习编程最有营养的原料,当你有好奇心时,不妨去窥探一下源码,相信你有定会有新的收获。今天的分享就到这里,如果有收获的话,请点赞、在看、转发、关注,感谢你的支持。
参考资料
LRU 缓存淘汰算法-双链表+hash 表: https://github.com/somenzz/geekbang/blob/master/algorthms/lru_use_link_table.py
[2]LRU 缓存淘汰算法-Python 有序字典: https://github.com/somenzz/geekbang/blob/master/algorthms/lru_use_ordered_dict.py