
HttpClient 设置不当引发的一次雪崩!

作者 | zxcodestudy
一. 事件背景
我最近运维了一个网上的实时接口服务,最近经常出现Address already in use (Bind failed)的问题。
很明显是一个端口绑定冲突的问题,于是大概排查了一下当前系统的网络连接情况和端口使用情况,发现是有大量time_wait的连接一直占用着端口没释放,导致端口被占满(最高的时候6w+个),因此HttpClient建立连接的时候会出现申请端口冲突的情况。
具体情况如下:
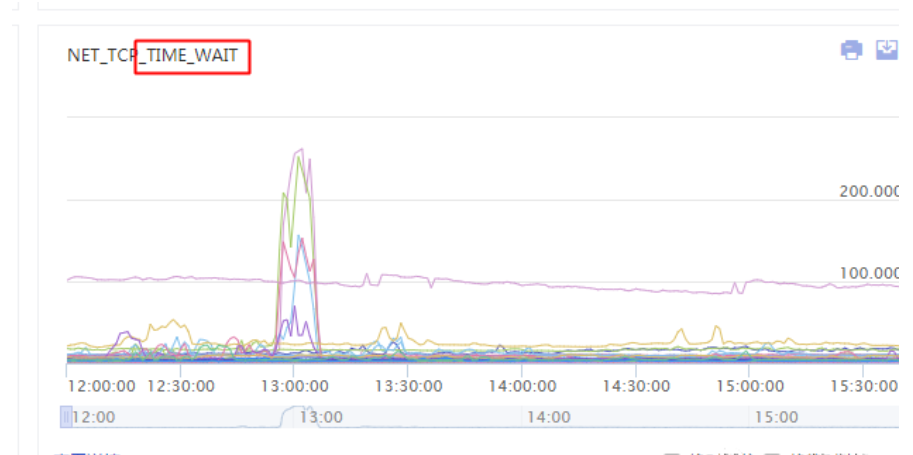 time_wait特征
time_wait特征
于是为了解决time_wait的问题,网上搜索了些许资料加上自己的思考,于是认为可以通过连接池来保存tcp连接,减少HttpClient在并发情况下随机打开的端口数量,复用原来有效的连接。但是新的问题也由连接池的设置引入了。
在估算连接池最大连接数的时候,参考了业务高峰期时的请求量为1分钟1.2w pv,接口平响为1.3s(复杂的广告推广效果模拟系统,在这种场景平响高是业务所需的原因)。
因此qps为12000* 1.3\60=260
然后通过观察了业务日志,每次连接建立耗时1.1s左右, 再留70%+的上浮空间(怕连接数设置小出系统故障),最大连接数估计为2601.1*1.7约等于500。
为了减少对之前业务代码最小的改动,保证优化的快速上线验证,仍然使用的是HttpClient3.1 的MultiThreadedHttpConnectionManager,然后在线下手写了多线程的测试用例,测试了下并发度确实能比没用线程池的时候更高,然后先在我们的南京机房小流量上线验证效果,效果也符合预期之后,就开始整个北京机房的转全。结果转全之后就出现了意料之外的系统异常。。。
三. 案情回顾
在当天晚上流量转全之后,一起情况符合预期,但是到了第二天早上就看到用户群和相关的运维群里有一些人在反馈实况页面打不开了。这个时候我在路上,让值班人帮忙先看了下大概的情况,定位到了耗时最高的部分正是通过连接池调用后端服务的部分,于是可以把这个突发问题的排查思路大致定在围绕线程池的故障来考虑了。
于是等我到了公司,首先观察了一下应用整体的情况:
监控平台的业务流量表现正常,但是部分机器的网卡流量略有突增 接口的平响出现了明显的上升 业务日志无明显的异常,不是底层服务超时的原因,因此平响的原因肯定不是业务本身 发现30个机器实例竟然有9个出现了挂死的现象,其中6个北京实例,3个南京实例
四. 深入排查
由于发现了有近 1/3的实例进程崩溃,而业务流量没变,由于RPC服务对provider的流量进行负载均衡,所以引发单台机器的流量升高,这样会导致后面的存活实例更容易出现崩溃问题,于是高优看了进程挂死的原因。
由于很可能是修改了HttpClient连接方式为连接池引发的问题,最容易引起变化的肯定是线程和CPU状态,于是立即排查了线程数和CPU的状态是否正常
1、CPU状态
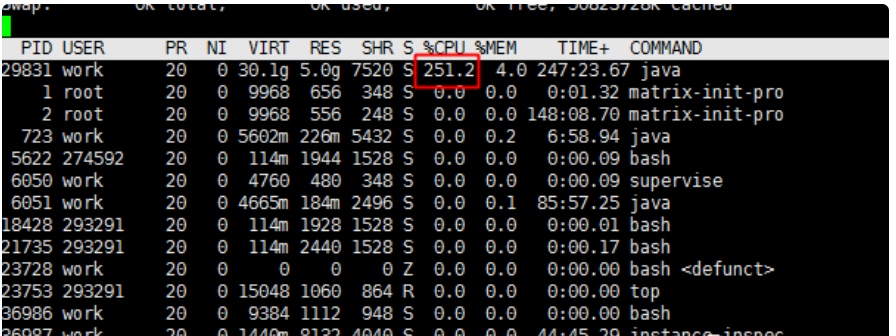 CPU特征
CPU特征
如图可见Java进程占用cpu非常高,是平时的近10倍
2、线程数监控状态:
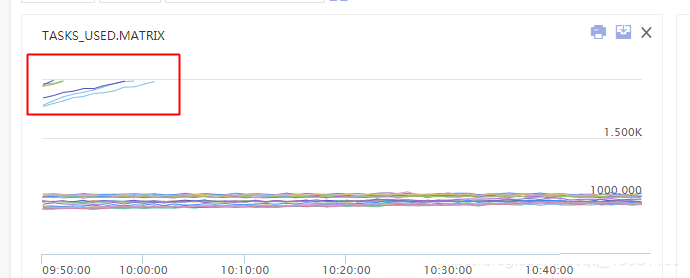
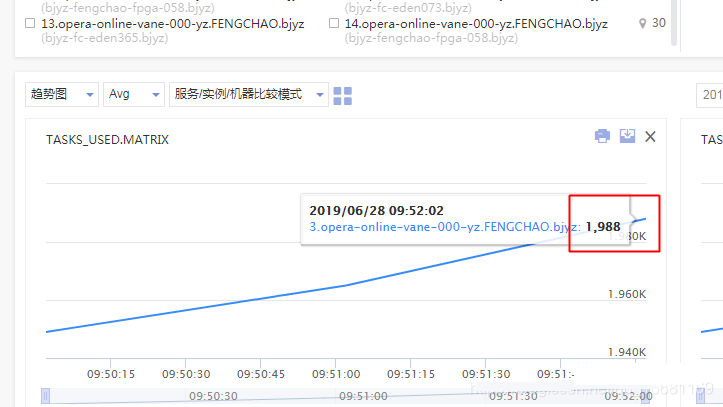
图中可以看到多个机器大概在10点初时,出现了线程数大量飙升,甚至超出了虚拟化平台对容器的2000线程数限制(平台为了避免机器上的部分容器线程数过高,导致机器整体夯死而设置的熔断保护),因此实例是被虚拟化平台kill了。之前为什么之前在南京机房小流量上线的时候没出现线程数超限的问题,应该和南京机房流量较少,只有北京机房流量的1/3有关。
接下来就是分析线程数为啥会快速积累直至超限了。这个时候我就在考虑是否是连接池设置的最大连接数有问题,限制了系统连接线程的并发度。为了更好的排查问题,我回滚了线上一部分的实例,于是观察了下线上实例的 tcp连接情况和回滚之后的连接情况
回滚之前tcp连接情况:

回滚之后tcp连接情况:

发现连接线程的并发度果然小很多了,这个时候要再确认一下是否是连接池设置导致的原因,于是将没回滚的机器进行jstack了,对Java进程中分配的子线程进行了分析,总于可以确认问题。
jstack状态:
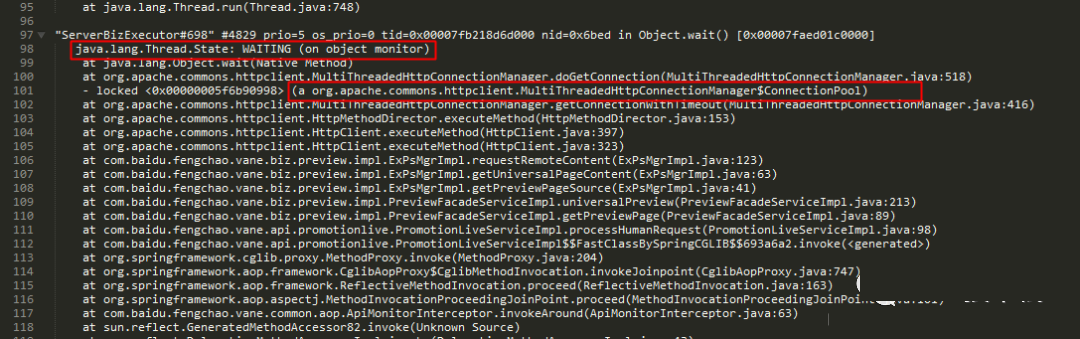
从jstack的日志中可以很容易分析出来,有大量的线程在等待获取连接池里的连接而进行排队,因此导致了线程堆积,因此平响上升。由于线程堆积越多,系统资源占用越厉害,接口平响也会因此升高,更加剧了线程的堆积,因此很容易出现恶性循环而导致线程数超限。
那么为什么会出现并发度设置过小呢?之前已经留了70%的上浮空间来估算并发度,这里面必定有蹊跷!
于是我对源码进行了解读分析,发现了端倪:
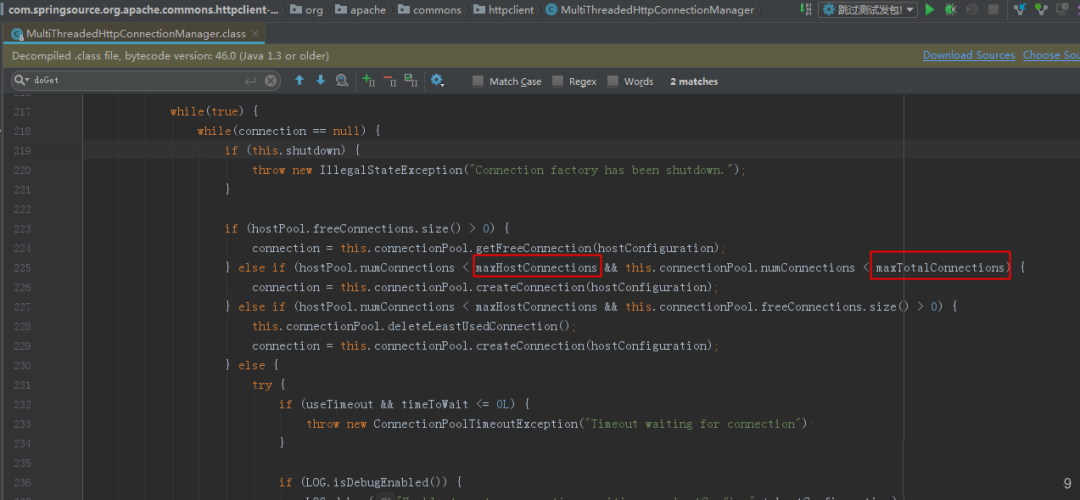
如MultiThreadedHttpConnectionManager源码可见,连接池在分配连接时调用的doGetConnection方法时,对能否获得连接,不仅会对我设置的参数maxTotalConnections进行是否超限校验,还会对maxHostConnections进行是否超限的校验。
于是我立刻网上搜索了下maxHostConnections的含义:每个host路由的默认最大连接,需要通过setDefaultMaxConnectionsPerHost来设置,否则默认值是2。
所以并不是我对业务的最大连接数计算失误,而是因为不知道要设置DefaultMaxConnectionsPerHost而导致每个请求的Host并发连接数只有2,限制了线程获取连接的并发度(所以难怪刚才观察tcp并发度的时候发现只有2个连接建立 😃 )
到此这次雪崩事件的根本问题已彻底定位,让我们再次精炼的总结一下这个案件的全过程:
连接池设置错参数,导致最大连接数为2 大量请求线程需要等待连接池释放连接,出现排队堆积 夯住的线程变多,接口平响升高,占用了更多的系统资源,会加剧接口的耗时增加和线程堆积 最后直至线程超限,实例被虚拟化平台kill 部分实例挂死,导致流量转移到其他存活实例。其他实例流量压力变大,容易引发雪崩
关于优化方案与如何避免此类问题再次发生,我想到的方案有3个:
在做技术升级前,要仔细熟读相关的官方技术文档,最好不要遗漏任何细节 可以在网上找其他可靠的开源项目,看看别人的优秀的项目是怎么使用的。比如github上就可以搜索技术关键字,找到同样使用了这个技术的开源项目。要注意挑选质量高的项目进行参考 先在线下压测,用控制变量法对比各类设置的不同情况,这样把所有问题在线下提前暴露了,再上线心里就有底了
以下是我设计的一个压测方案:
a. 测试不用连接池和使用连接池时,分析整体能承受的qps峰值和线程数变化
b. 对比setDefaultMaxConnectionsPerHost设置和不设置时,分析整体能承受的qps峰值和线程数变化
c. 对比调整setMaxTotalConnections,setDefaultMaxConnectionsPerHost 的阈值,分析整体能承受的qps峰值和线程数变化
d. 重点关注压测时实例的线程数,cpu利用率,tcp连接数,端口使用情况,内存使用率
综上所述,一次连接池参数导致的雪崩问题已经从分析到定位已全部解决。在技术改造时我们应该要谨慎对待升级的技术点。
在出现问题后,要重点分析问题的特征和规律,找到共性去揪出根本原因。
往期推荐
关注我回复「加群」,加入Spring技术交流群