
自带的 print 函数居然会报错?

前言
最近用 Python 写了几个简单的脚本来处理一些数据,因为只是简单功能所以我就直接使用 print 来打印日志。
任务运行时偶尔会出现一些异常:

因为我在不同地方都有打印日志,导致每次报错的地方都不太一样,从而导致程序运行结果非常诡异;有时候是这段代码没有运行,下一次就可能是另外一段代码没有触发。
虽说当时有注意到 Broken pipe 这个关键异常,但没有特别在意,因为代码中也有一些发送 http 请求的地方,一直以为是网络 IO 出现了问题,压根没往 print 这个最基本的打印函数上思考🤔。
直到这个问题反复出现我才认真看了这个异常,定睛一看 print 不也是 IO 操作嘛,难道真的是自带的 print 函数都出问题了?
但在本地、测试环境我运行无数次也没能发现异常;于是我找运维拿到了线上的运行方式。
原来为了方便维护大家提交上来的脚本任务,运维自己有维护一个统一的脚本,在这个脚本中使用:
cmd = 'python /xxx/test.py'
os.popen(cmd)
来触发任务,这也是与我在本地、开发环境的唯一区别。
popen 原理
为此我在开发环境模拟出了异常:
test.py:
import time
if __name__ == '__main__':
time.sleep(20)
print '1000'*1024
task.py:
import os
import time
if __name__ == '__main__':
start = int(time.time())
cmd = 'python test.py'
os.popen(cmd)
end = int(time.time())
print 'end****{}s'.format(end-start)
运行:
python task.py
等待 20s 必然会复现这个异常:
Traceback (most recent call last):
File "test.py", line 4, in <module>
print '1000'*1024
IOError: [Errno 32] Broken pipe
为什么会出现这个异常呢?
首先得了解 os.popen(command[, mode[, bufsize]]) 这个函数的运行原理。
根据官方文档的解释,该函数会执行 fork 一个子进程执行 command 这个命令,同时将子进程的标准输出通过管道连接到父进程;
也就该方法返回的文件描述符。
这里画个图能更好地理解其中的原理: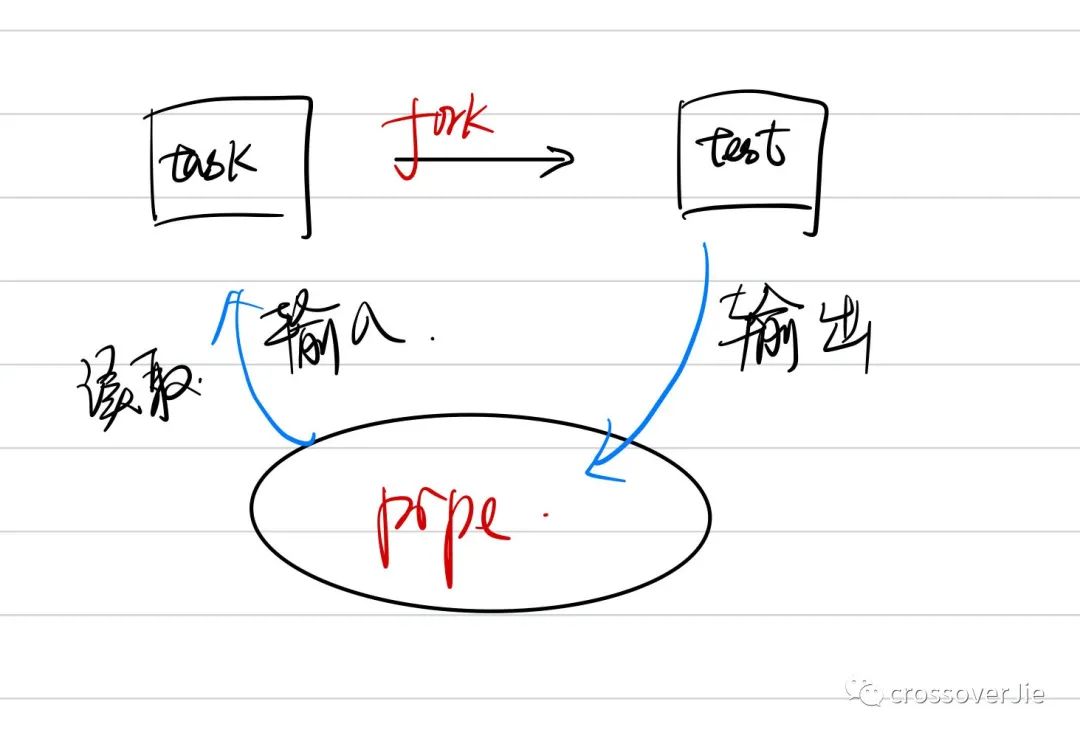
在这里的使用场景中并没有获取 popen() 的返回值,所以 command 的执行本质上是异步的;
也就是说当 task.py 执行完毕后会自动关闭读取端的管道。 如图所示,关闭之后子进程会向
如图所示,关闭之后子进程会向 pipe 中输出 print '1000'*1024,由于这里输出的内容较多会一下子填满管道的缓冲区;
于是写入端会收到 SIGPIPE 信号,从而导致 Broken pipe 的异常。
从维基百科中我们也可以看出这个异常产生的一些条件:
其中也提到了 SIGPIPE 信号。
解决办法
既然知道了问题原因,那解决起来就比较简单了,主要有以下几个方案:
使用 read()函数读取管道中的数据,全部读取之后再关闭。如果不需要子进程中的输出时,也可以将 command的标准输出重定向到/dev/null。也可以使用 Python3的subprocess.Popen模块来运行。
这里使用第一种方案进行演示:
import os
import time
if __name__ == '__main__':
start = int(time.time())
cmd = 'python test.py'
with os.popen(cmd) as p:
print p.read()
end = int(time.time())
print 'end****{}s'.format(end-start)
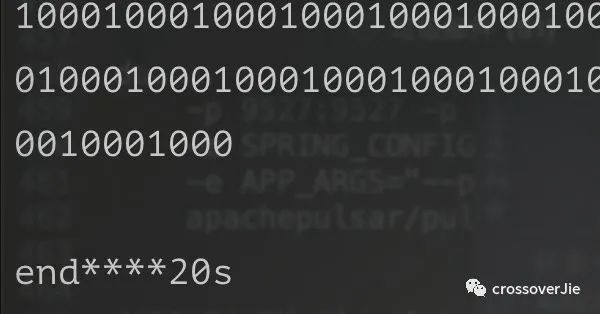
运行 task.py 之后不会再抛异常,同时也将 command 的输出打印出来。
线上修复时我没有采用这个方案,为了方便查看日志,还是使用标准的日志框架将日志输出到了 es 中,方便统一在 kibana 中进行查看。
由于日志框架并没有使用到管道,所以自然也不会有这个问题。
更多内容
问题虽然是解决了,其中还是涉及到了一些咱们平时不太注意的知识点,这次我们就来一起回顾一下。
首先是父子进程的内容,这个在 c/c++/python 中比较常见,在 Java/golang 中直接使用多线程、协程会更多一些。
比如这次提到的 Python 中的 os.popen() 就是创建了一个子进程,既然是子进程那肯定是需要和父进程进行通信才能达到协同工作的目的。
很容易想到,父子进程之间可以通过上文提到的管道(匿名管道)来进行通信。
还是以刚才的 Python 程序为例,当运行 task.py 后会生成两个进程:
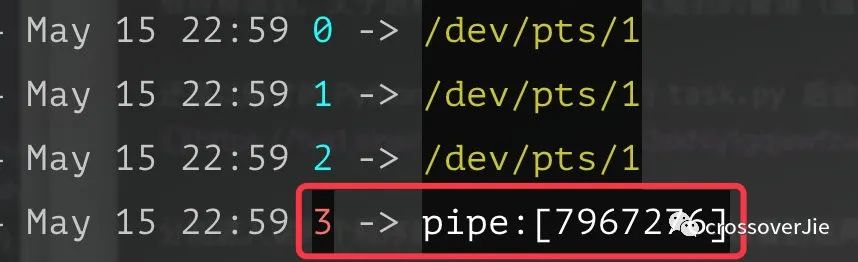
分别进入这两个程序的/proc/pid/fd 目录可以看到这两个进程所打开的文件描述符。
父进程:
子进程:
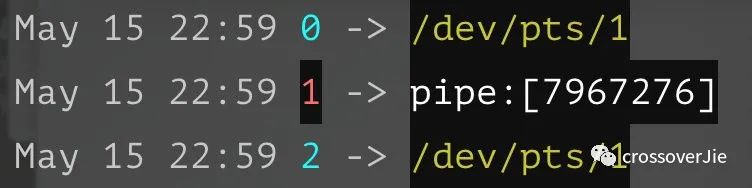
可以看到子进程的标准输出与父进程关联,也就是 popen() 所返回的那个文件描述符。
这里的
0 1 2分别对应一个进程的stdin(标准输入)/stdout(标准输出)/stderr(标准错误)。
还有一点需要注意的是,当我们在父进程中打开的文件描述符,子进程也会继承过去;
比如在 task.py 中新增一段代码:
x = open("1.txt", "w")
之后查看文件描述符时会发现父子进程都会有这个文件: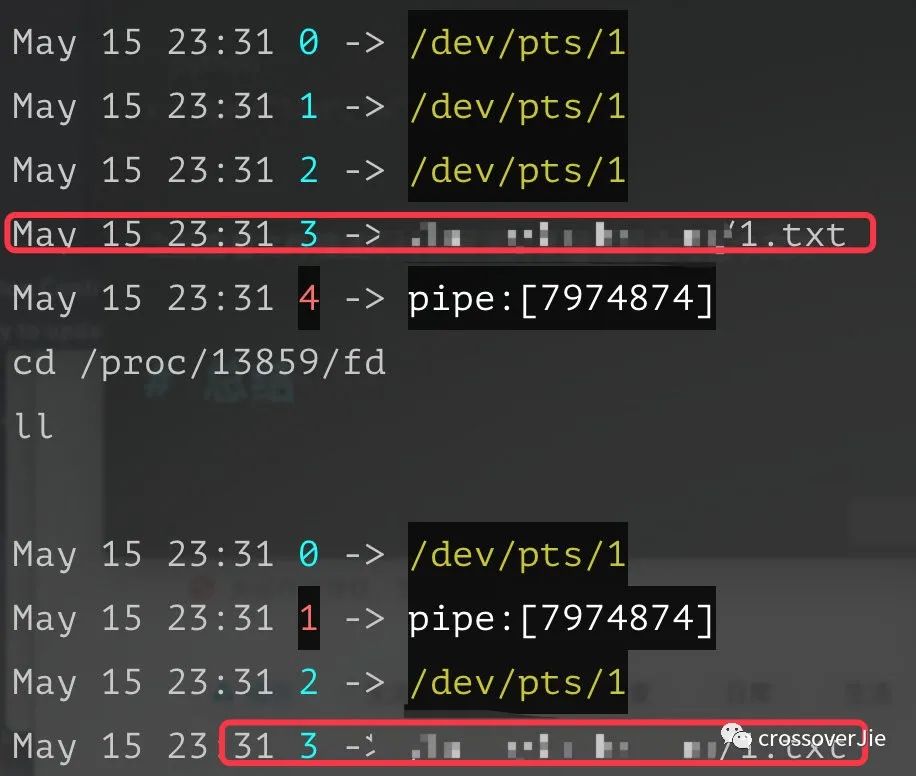
但相反的,子进程中打开的文件父进程是不会有的,这个应该很容易理解。
总结
一些基础知识在排查一些诡异问题时显得尤为重要,比如本次涉及到的父子进程的管道通信,最后来总结一下:
os.popen()函数是异步执行的,如果需要拿到子进程的输出,需要自行调用read()函数。父子进程是通过匿名管道进行通信的,当读取端关闭时,写入端输出到达管道最大缓存时会收到 SIGPIPE信号,从而抛出Broken pipe异常。子进程会继承父进程的文件描述符。
你的点赞与分享是对我最大的支持
更多推荐内容
↓
《为自己搭建一个分布式 IM(即时通讯) 系统》