
一步步教你理解LSTM
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

LSTM全名是Long Short-Term Memory,长短时记忆网络,可以用来处理时序数据,在自然语言处理和语音识别等领域应用广泛。和原始的循环神经网络RNN相比,LSTM解决了RNN的梯度消失问题,可以处理长序列数据,成为当前最流行的RNN变体。
假设我们的模型的输入是依次输入一句话的每个单词,我们需要对单词做分类,比如有两句话:(1)arrive Beijing on November 2nd,这里的Beijing是目的地;(2)leave Beijing on November 2nd,这里的Beijing是出发地。如果用普通的神经网络,输入是'Beijing',那么输出一定就是确定的,但事实上我们希望在'Beijing'前面是'arrive'时,'Beijing'被识别为目的地,在'Beijing'前面时'leave'时,'Beijing'被识别为出发地。这里LSTM就会派上用场,因为LSTM可以记住历史信息,在读到'Beijing'时,LSTM还知道在前面是'arrive'还是'leave',根据历史信息来做出不同的判断,即使输入是相同的,输出也会不同。
普通的神经元是一个输入,一个输出,如图所示:
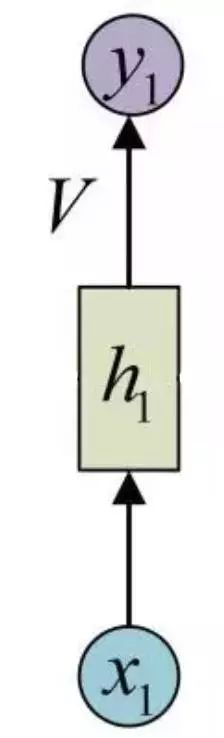
对于神经元h1来讲,输入就是x1,输出就是y1,LSTM做的就是把普通的神经元,替换成LSTM的单元。
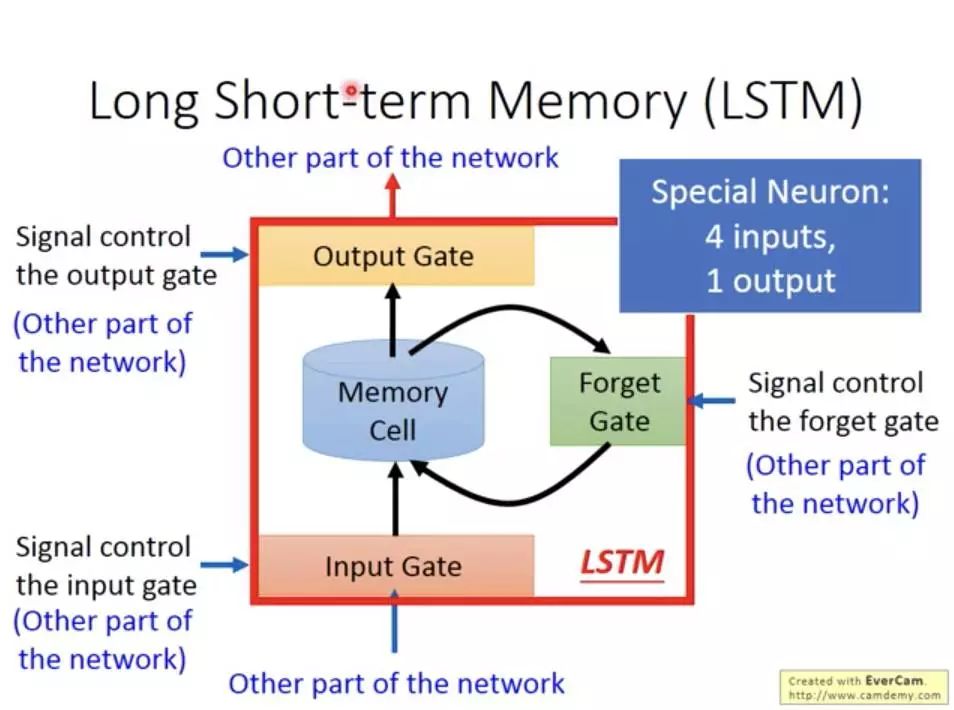
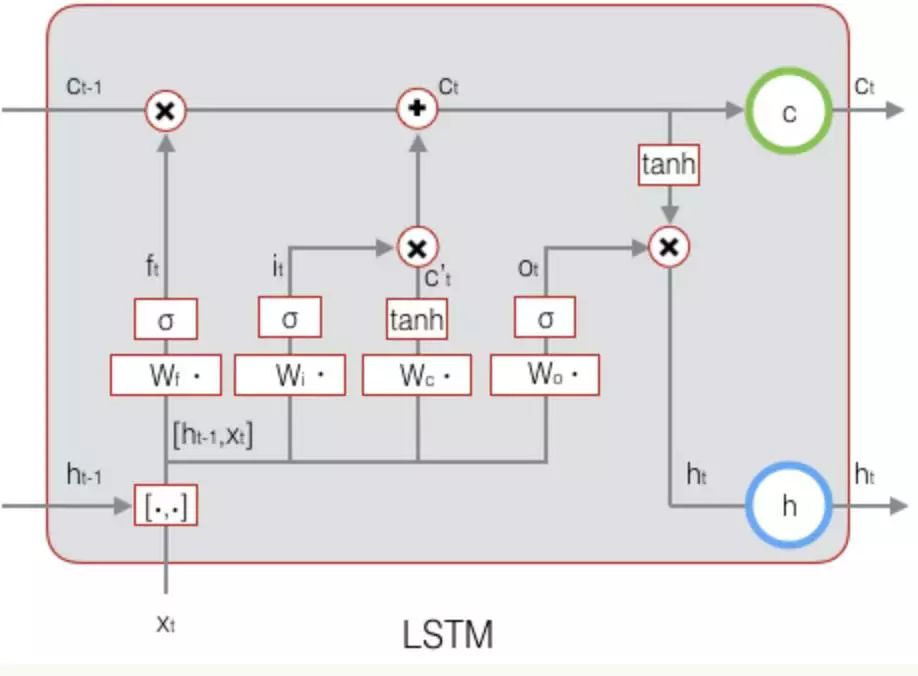
从图中可以看到LSTM有四个输入,分别是input(模型输入),forget gate(遗忘门),input gate(输入门),以及output gate(输出门)。因此相比普通的神经网络,LSTM的参数量是它们的4倍。这3个门信号都是处于0~1之间的实数,1代表完全打开,0代表关闭。遗忘门:决定了前一时刻中memory中的是否会被记住,当遗忘门打开时,前一刻的记忆会被保留,当遗忘门关闭时,前一刻的记忆就会被清空。输入门:决定当前的输入有多少被保留下来,因为在序列输入中,并不是每个时刻的输入的信息都是同等重要的,当输入完全没有用时,输入门关闭,也就是此时刻的输入信息被丢弃了。输出门:决定当前memroy的信息有多少会被立即输出,输出门打开时,会被全部输出,当输出门关闭时,当前memory中的信息不会被输出。
有了上面的知识,再来推导LSTM的公式就很简单了,图中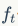 代表遗忘门,
代表遗忘门,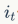 代表输入门,
代表输入门,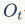 代表输出门。C是memroy cell,存储记忆信息。
代表输出门。C是memroy cell,存储记忆信息。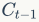 代表上一时刻的记忆信息,
代表上一时刻的记忆信息,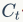 代表当前时刻的记忆信息,h是LSTM单元的输出,
代表当前时刻的记忆信息,h是LSTM单元的输出,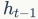 是前一刻的输出。
是前一刻的输出。
遗忘门计算:
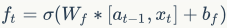
这里的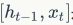 是把两个向量拼接起来的意思,用sigmoid函数主要原因是得到有个0~1之间的数,作为遗忘门的控制信号。
是把两个向量拼接起来的意思,用sigmoid函数主要原因是得到有个0~1之间的数,作为遗忘门的控制信号。
输入门计算:
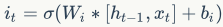
当前输入:
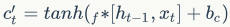
当前时刻的记忆信息的更新:
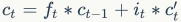
从这个公式可以看出,前一刻的记忆信息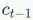 通过遗忘门
通过遗忘门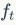 ,当前时刻的输入
,当前时刻的输入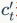 通过输入门
通过输入门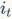 ,加起来更新当前的记忆信息
,加起来更新当前的记忆信息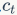 。
。
输入门计算:
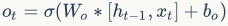
LSTM的输出,是由输出门和当前记忆信息共同决定的:

这样我们就明白了LSTM的前向计算过程。有了LSTM前向传播算法,推导反向传播算法就很容易了, 通过梯度下降法迭代更新我们所有的参数,关键点在于计算所有参数基于损失函数的偏导数,这里就不细讲了。
LSTM虽然结构复杂,但是只要理顺了里面的各个部分和之间的关系,是不难掌握的。在实际使用中,可以借助算法库如Keras,PyTorch等来搞定,但是仍然需要理解LSTM的模型结构。
https://www.youtube.com/watch?v=rTqmWlnwz_0&index=35&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49
https://zybuluo.com/hanbingtao/note/581764
http://www.cnblogs.com/pinard/p/6519110.html
http://blog.echen.me/2017/05/30/exploring-lstms/
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~