
Linux中内存管理详解

Linux中内存管理
内存管理的主要工作就是对物理内存进行组织,然后对物理内存的分配和回收。但是Linux引入了虚拟地址的概念。
1、物理内存
物理内存的组织
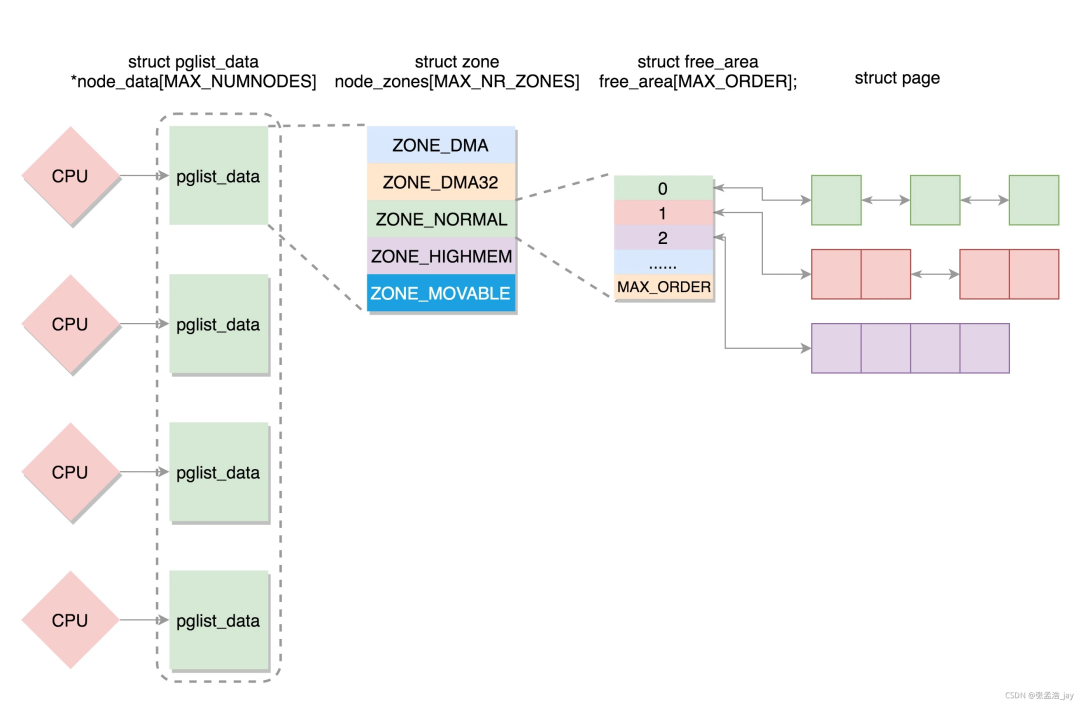
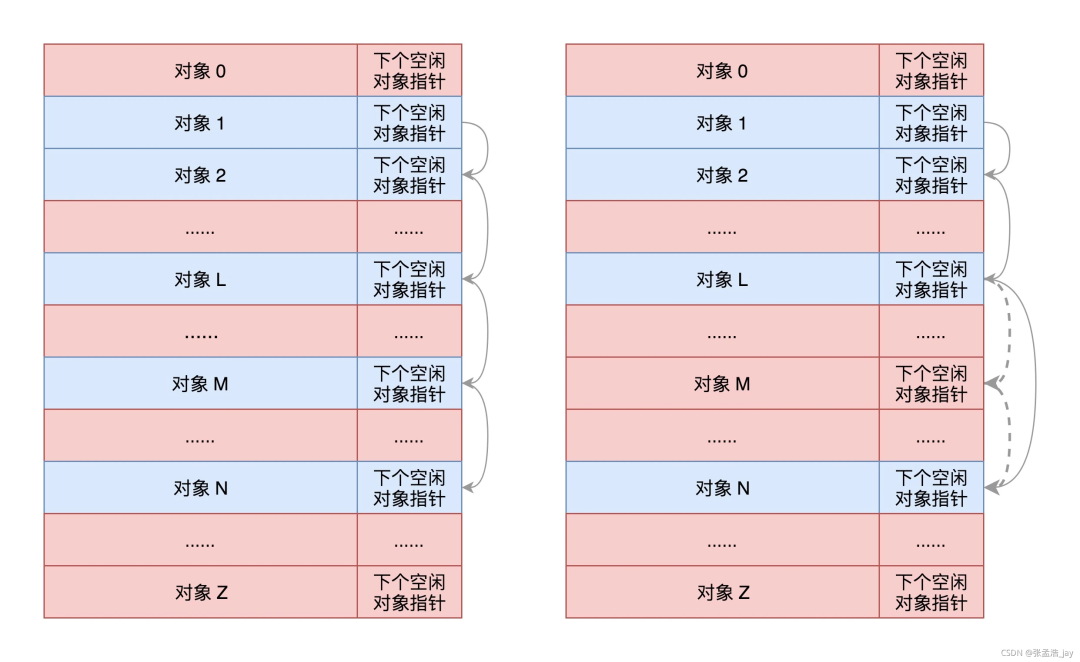
物理内存的分配

2、如何组织虚拟地址
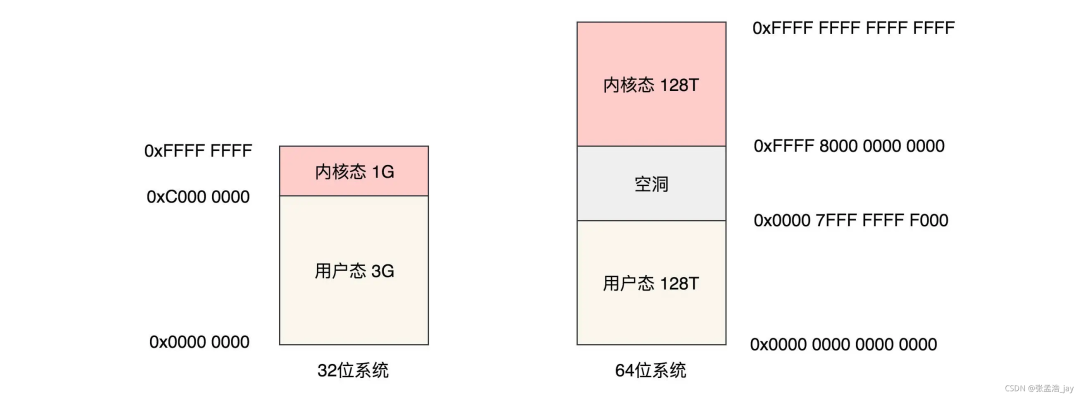

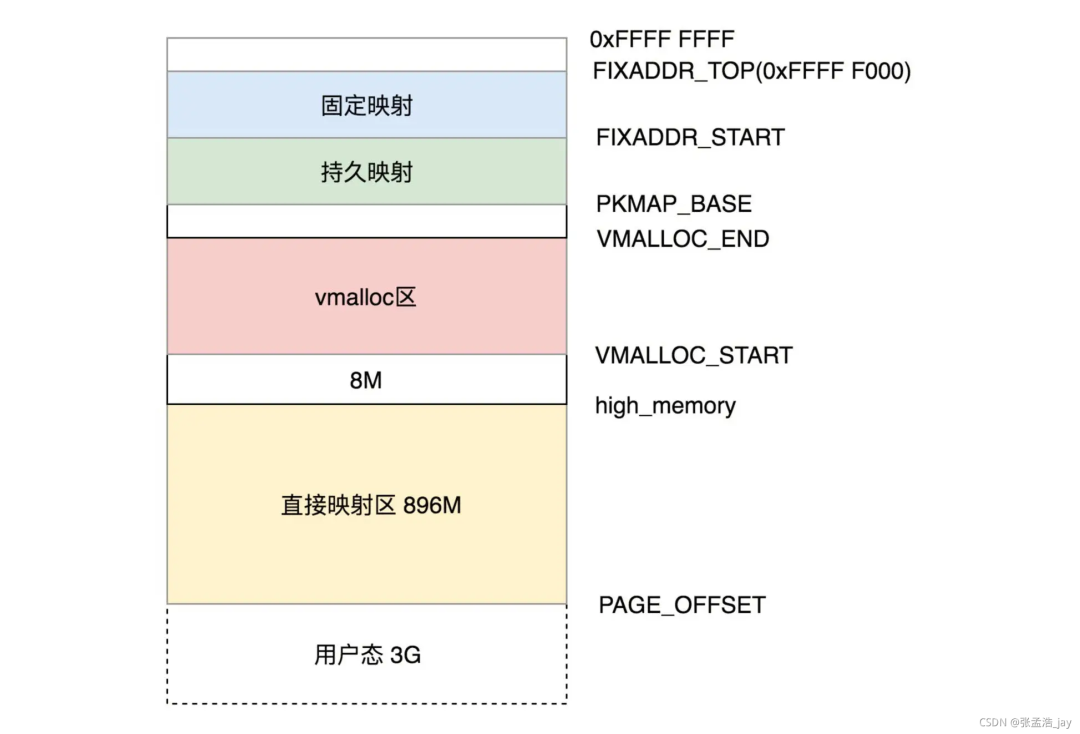
3、如何将虚拟地址映射到物理内存
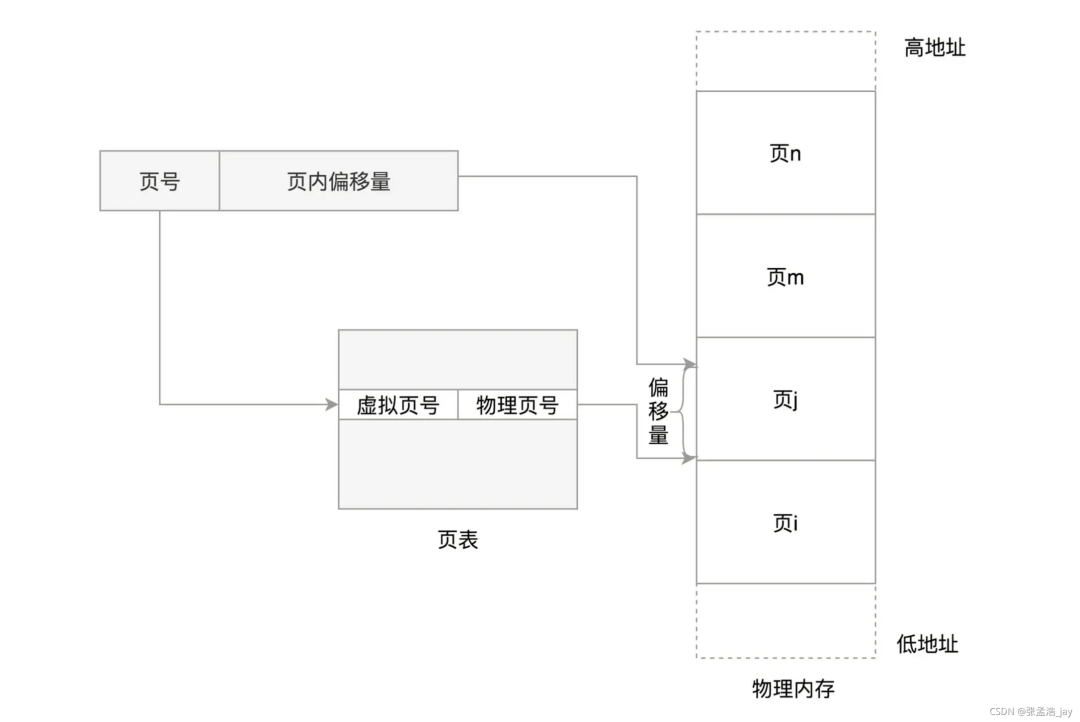
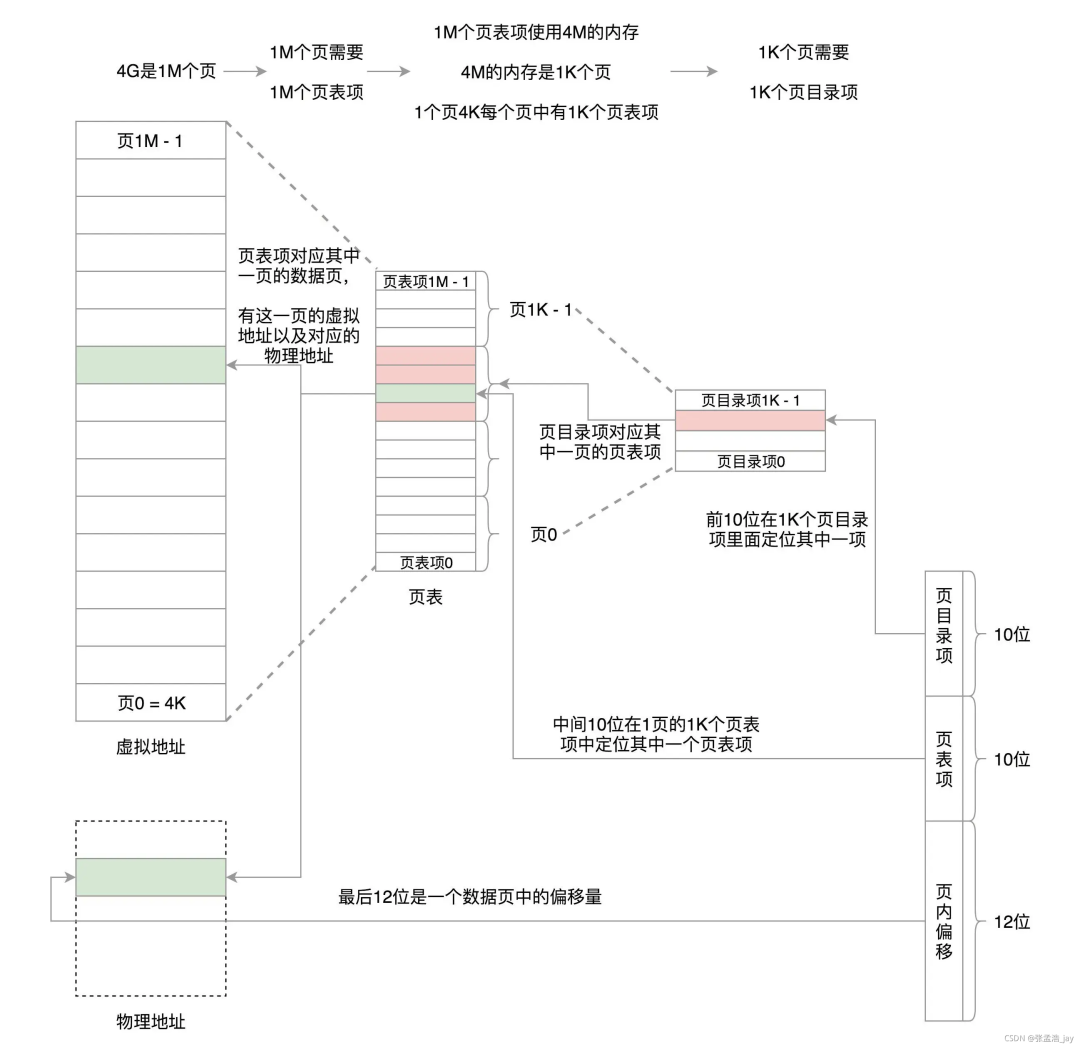
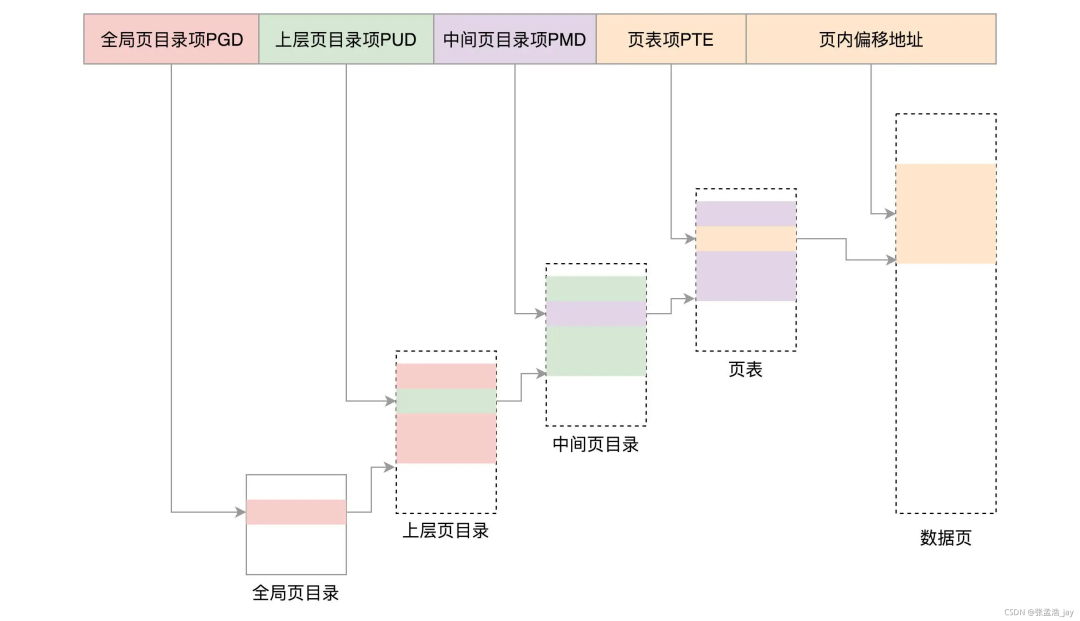
页表映射
TLB
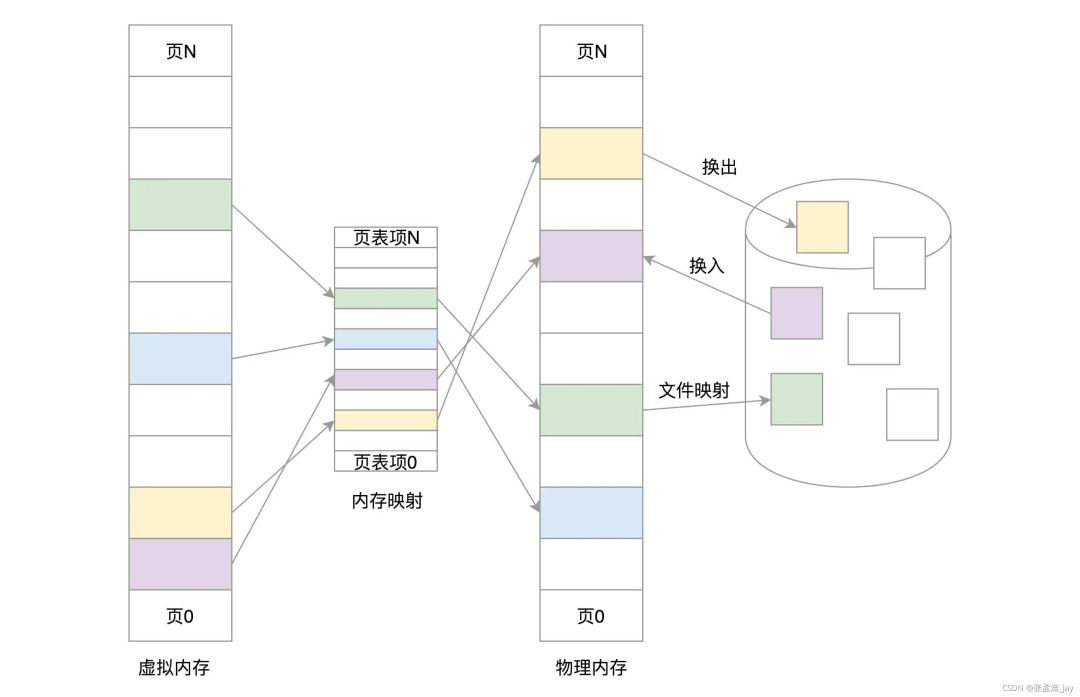
虚拟内存
总结
来源:https://blog.csdn.net/qq_40276626/article/details/120477263
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
评论