
前缀树在前端路由系统中的应用
大厂技术 坚持周更 精选好文
背景
本人自己曾经造轮子搞过一个 Node.js 端的应用层 Web 框架,里面涉及到一个路由系统的实现,当时是通过一个叫前缀树的数据结构来实现便捷的路由查找与匹配机制,这里跟大家分享一下。
前缀树介绍
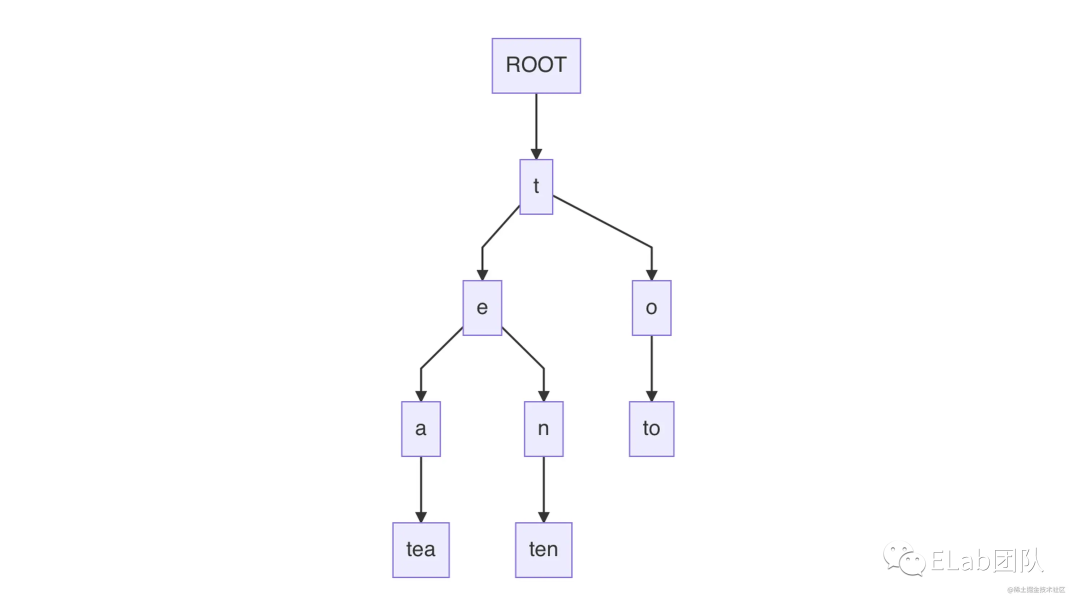
前缀树,即字典树,又称 Trie 树。这种数据结构通常用来储存字符串,并且是以路径字符节点的形式来储存。拥有公共前缀的字符串,会共享同样的父节点路径。前缀树是通过利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
前缀树的 3 个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。 每个节点的所有子节点包含的字符都不相同。
路由匹配的场景
这个问题是在做 Web 框架的路由时碰见的,所以这里的请求路径的形式可以当做就是一个个 URL 刨去协议名、域名、端口号(有的话)之后的部分,一般是通过斜杠 ("/") 来链接一个个元素,形如:
/api/user/nameList /api/user/addressList
而且在大部分时候,路由的路径是根据模块的层级来划分功能,以达到顾名思义的目的,因此路由的路径其实是会有很多公共的前缀。比如,上述例子中同属于一个二级模块 User 的接口:
/api/user/list 和 /api/user/create ,它们便有共同的前缀 /api/user ,联系到上述前缀树的性质,我们便可以通过前缀树来储存和搜索这些路由信息。
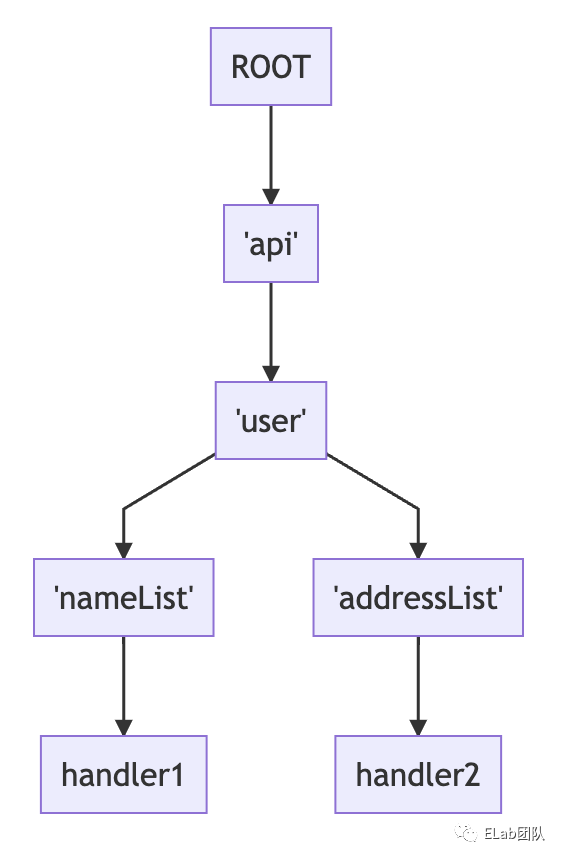
应用到路由匹配中
根据上面的一个结论,可以得到一个基本思路:
把路由路径当做是用斜杠连接起来的 Component 的组合,因此前缀树当中的节点,储存的就不再是单个字符,而是一个个 Component,但这不会影响我们去使用这种数据结构来进行搜索。
按照上面的描述,将这两串路径用 / 分割,形成一组 Component,同时它们拥有两层的公共路径,那么将会形成这样的树结构:(叶子节点储存的是对应的 handler)
将路由声明添加到 Trie 树中
下面是将路由声明的 Component 添加到 Trie 树中的代码:
router.get( '/api/user/nameList', xxx);
addToTree(urlPattern: string, handler: any) {
let p = this.root;
// Padding an element to the rear of the array to make the leaf node.
const urlPatternComponents = [...urlPattern.split('/').filter(Boolean), LEAF_SIGN];
urlPatternComponents.forEach(component => {
const { quickMap } = p;
// If quickMap has this component, it means the route has the same namespace
// with existed route, so get to the next level directly. If the node is a leaf
// node, just return cause it means redundant route is adding to the tree, we dont need it.
if (p.quickMap.has(component as string)) {
const node = p.quickMap.get(component as string)!;
if (isLeafNode(node)) {
return;
}
p = node;
return;
}
if (component === LEAF_SIGN) {
const newNode = new RouterTreeLeafNode(handler);
quickMap.set(LEAF_SIGN, newNode);
return;
}
const newNode = new NTreeNode(component as string);
p.quickMap.set(component as string, newNode);
// When the expression like ':id' shows in the route, it should
// treat it as a parameter node.One tree node can only have one parameter node.
if ((component as string).indexOf(':') > -1) {
p.paramNode = newNode;
}
p = newNode;
});
}
router.get(' /api/hi/:name'
这里用一个 quickMap 来储存子节点,key 为 Component,value 为节点,用于在匹配过程中快速查找到与 Component 值相匹配的节点。注意在 urlComponents 数组末尾填充了一个叫 LEAF_SIGN 的 Symbol,看上面的树结构图就知道,实际路由声明的 Component 遍历完之后,叶子节点的值储存的是最后一个 Component,因此我们需要给它添加一个子节点,用来储存实际匹配的结果,也就是路由的 Handler。paramNode 放到动态路由匹配一节再解析,这里可以先不管。
静态路由匹配
在匹配时,也实际的请求路径同样按照上面的分割方式切分成一组 Component,从 Trie 的根节点开始,它的子节点必定只有一个,将指针指向它的唯一子节点,并将遍历 Component 的指针往后挪,根据遍历到的新的 Component 去匹配下一层的子节点。直到 Component 被遍历完,若最后可以找到相匹配的子节点,则该节点为叶子节点,将其值取出作为结果返回。若未能匹配,在静态路由匹配的情况中就是 Route not found 的情况了,但是实际场景肯定没有这么简单粗暴,这里先留个坑,后面会讲到。
代码如下:
getHandlerFromTree(url: string): any{
const [urlWithParams, _] = url.split('?');
const urlComponents = urlWithParams.split('/').filter(Boolean);
let p = this.root;
let i = 0;
let res;
let path = '';
while (p) {
const component = urlComponents[i ++];
// If the quickMap has the component, return it if it's also a leaf node.
// Or just move to the next level and store the path.
if (p.quickMap.has(component)) {
const node = p.quickMap.get(component)!;
if (isLeafNode(node)) {
res = node.value;
break;
}
path += '/' + node.value;
p = node;
continue;
}
const leafNode = p.quickMap.get(LEAF_SIGN);
if (leafNode == null) {
// If quickMap has other node, it means static route cannot be matched.
if (p.quickMap.size > 0) {
const err = { message: 'Route not defined', statusCode: 404, statusMessage: 'Not found' };
throw err;
}
// Else it means no handler was defined.
const err = { message: 'Handler not defined', statusCode: 500, statusMessage: 'Not found' };
throw err;
}
res = leafNode.value;
break;
}
return {
handler: res,
path
};
}
动态路由匹配
我们在使用 Express 或是 Koa.js 时,会用到形如 /api/user/:id 这样的动态路由声明,这是一个实用的功能,来看下如何在基于 Trie 树的路由系统中实现动态路由。
还是刚才的两条路由声明,现在我们加上一条新的:
/api/user/nameList
/api/user/addressList
/api/user/:id
得到这样的结构:
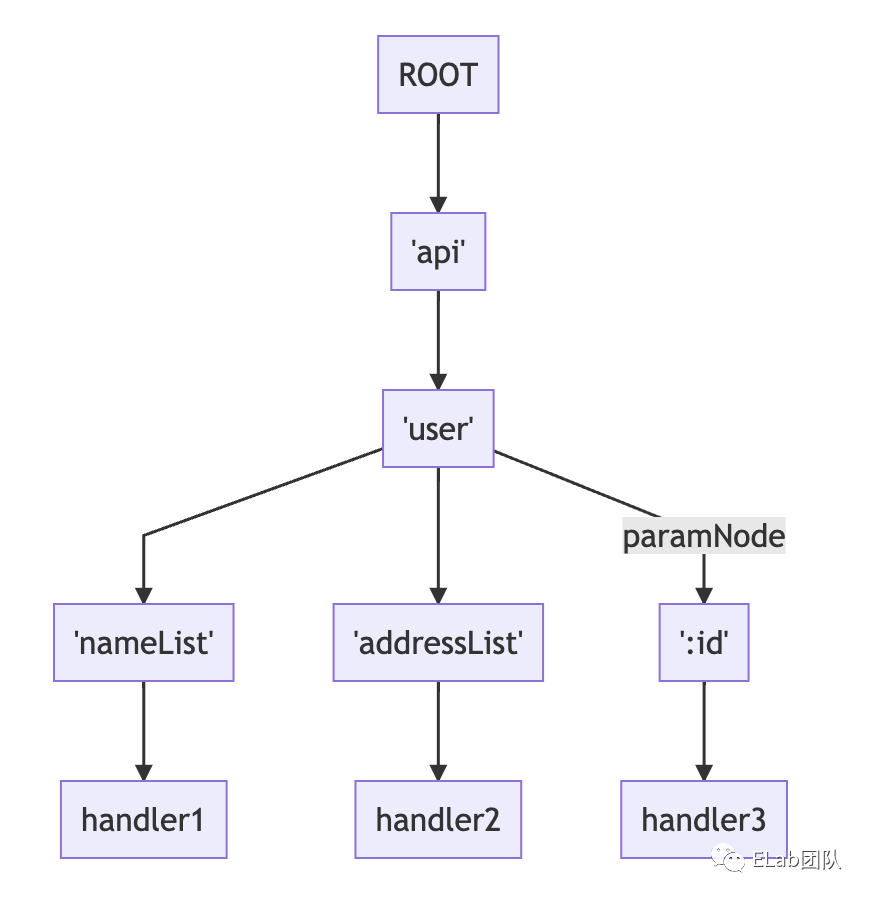
对这样的动态参数路由声明,将其作为一个特殊节点,用一个单独的指针 paramNode 保存,我们限制一种路由声明只能有一个动态参数,就是不能既有 /api/user/:id 又有 /api/user/:name,这样的话在实际匹配时无法得知,路径中对应位置的 Component 代表的是什么含义。
接上面的坑,实际匹配时,当碰见无法匹配的 Component 时,那么代表这个 Component 是一个动态参数的实际值,所以无法跟任何静态声明匹配,这时就直接去找该节点的 paramNode 指针指向的节点,也就是说当碰到这种情况时,我们直接把它归类为动态参数匹配的场景。
看一下加入动态参数匹配的代码,省略共同部分:
getHandlerFromTree(url: string): any {
// ...
if (p.quickMap.has(component)) {
const node = p.quickMap.get(component)!;
if (isLeafNode(node)) {
res = node.value;
break;
}
path += '/' + node.value;
p = node;
continue;
}
if (component) {
path += '/' + p.paramNode.value;
p = p.paramNode;
continue;
}
const leafNode = p.quickMap.get(LEAF_SIGN);
// ...
}
那么这时又有一个坑,如果 paramNode 不存在,该怎么办?下面来说下一种场景:正则表达式匹配。
正则表达式匹配
router.get( /hi/all/ , xxx)
因为正则表达式是可以直接进行字符串匹配的,所以这种路由声明将会脱离 Trie 树的数据结构特点而存在,我们选择将这种节点全部储存在根结点下方,避免不必要的查找。上面说到,如果一个节点的 paramNode 指针不存在,那么我们只好做最后一种选择,将整个路径进行正则表达式匹配,如果仍然无法匹配,就只好抛出路由未找到的异常,由依赖路由的代码去处理这个异常。
getHandlerFromTree(url: string) {
// ...
if (component) {
// If no parameter node found, try regular expression matching.
if (!p. paramNode ) {
const { handler, matched } = this . getHandlerFromRegExpNode (url);
res = handler
path = matched;
break ;
}
path += '/' + p.paramNode.value;
p = p.paramNode;
continue;
}
const leafNode = p.quickMap.get(LEAF_SIGN);
// ...
}
添加正则表达式节点到树中:
addRegExpToTree(urlPattern: RegExp, handler: Function) {
const root = this.root;
root.children.push(new RouterRegExpLeafNode(urlPattern, handler));
}
得到的结构是这样的:
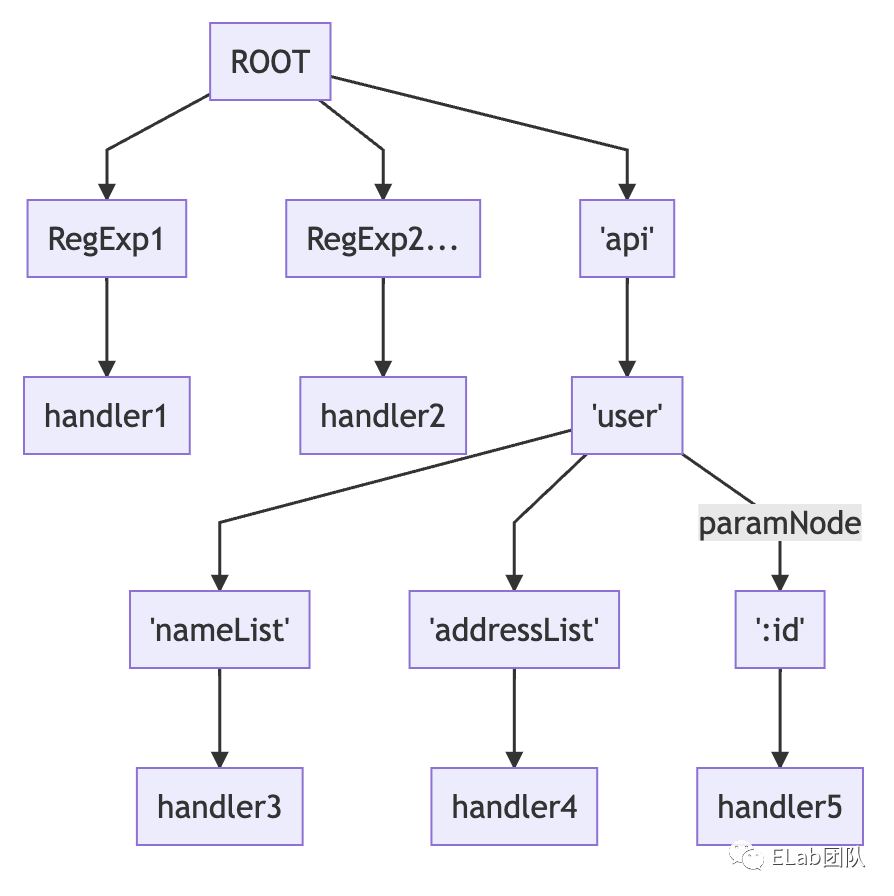
这样就实现了一个支持静态、动态、正则表达式三种匹配方式的路由机制。
简单分析
使用 Trie 树来做路由匹配就是比较折中的方案,通常来说路由声明都会按照模块来做分类,在同一个一级模块下面的多个二级模块路由,然后每个二级模块下面会有多个三级模块路由,就会产生公共前缀,就给了 Trie 树节省空间的机会,并且重复率越高节省的空间越多(听起来怎么像 gzip 压缩),Trie 树的最坏查找效率取决于所储存的序列的最长长度,也就是树的最大深度,是一个线性级别的时间复杂度。这里会有另一个问题,如果所有路由声明都是分散的,没有公共前缀,假设有 m 条长度为 n 的记录,在彼此没有公共前缀时,Trie 树的空间复杂度会达到 O(mn),故在使用时应尽量收敛路由声明的 namespace 数量。
总结
一开始内心有个问题,为什么不直接用哈希表储存静态路由,然后动态路由就使用遍历查找的方式?后面对这个问题有了一些自己的理解:
使用哈希表储存静态路由,查找速度是常数级别的,非常快,但是需要线性空间来储存,而且每一条静态路由都需要完整储存,那么就浪费了公共前缀这个特性。其次,对动态路由使用遍历匹配的方式太过暴力,动态路由没有办法去很好地做缓存,而路由匹配是个高频的动作,这种方式的性能开销相对来说比较大,也是不够合适的。
代码仓库
https://github.com/divasatanica/auf/blob/main/packages/core/src/router/prefix-tree/index.ts
有兴趣的小伙伴可以去瞅瞅。
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 趣谈前端 收货大厂一手好文章~

点个在看你最好看