
文字识别领域经典论文回顾第一期:CRNN
共 6166字,需浏览 13分钟
·
2022-02-09 17:36
1. 开篇
在文字识别经典论文回顾这个系列里,我会介绍从深度学习兴起后,文字识别领域一系列经典的论文。这些论文的挑选标准主要有两方面,一是是否具有足够的启发性,对解决文字识别领域的问题是否具有足够的推进作用。二是论文的算法是否简洁且统一,便于我们自己去复现。基于以上两点,我的介绍也自然分为两个方面,一方面是论文本身的解读,二是代码的解读。对于所有将要介绍论文,我都会用一个统一的代码框架进行复现,代码地址为:https://github.com/chibohe/text_recognition_toolbox
2. 论文解读
2.1 总览
CRNN是2015年提出的论文,论文的全称是《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》.顾名思义,针对文字识别,CRNN一方面提出了一个端到端的网络,另一方面则将文字识别问题转换成了序列识别问题。总体而言,CRNN的主要贡献有以下4点:
- 提出了一个可端到端训练的网络,由特征提取层(feature extraction)、序列模型(sequence modeling)、转译层(transcription)三部分组成;
- 将文字识别问题转化成序列识别问题,可处理任意长度的文本;
- 在无需词典进行后处理修正的情况下,识别效果依然表现良好;
- 框架简单,模型可以足够小。
根据第一点,论文的主体框架为CNN+BiLSTM+CTC, 整体架构详情见下图:

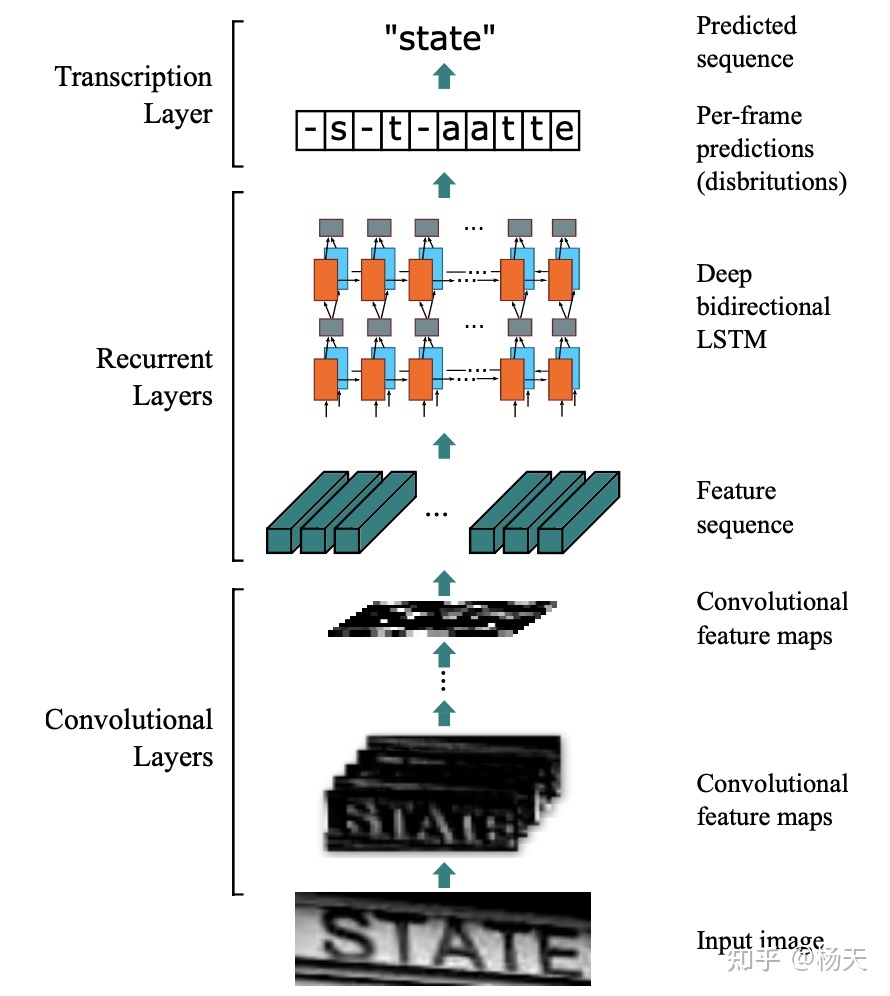
接下来,我们对CRNN的各个组成部分进行逐一的拆解。
2.2 特征提取层
在特征提取层中,论文采用了CNN将原图转换成一系列的特征图,这些特征图保留了原始图片的视觉特征信息。具体而言,论文中采用的CNN是类似VGG的架构,所有的卷积操作均采用3x3的卷积核,并且卷积核的数量会逐渐从最开始的64个,逐渐双倍递增至512.其中需要重点注意的是池化操作,在一般的maxpooling操作中,当kernel_size=(2, 2), stride=(2, 2)时,特征图的高度和宽度会缩减至原先的二分之一。而在论文的第三个maxpooling和第四个maxpooling中,采用的尺寸是kernel_size=(2, 1), 即高度缩减为原先的二分之一,而宽度只会减一。这样的操作是为了保留水平方向的信息,便于去处理长文本的识别。最后我们具体来看一下经过CNN后,图片尺寸的变化。在这里我们将一个张量表示为(B, C, H, W),其中B是批量处理的图片数量,C是通道个数,H是高度,W是宽度。假设原图是1通道的灰度图,高为32,宽为128,即(1, 1, 32, 128)。在经过特征提取层之后,尺寸变为(1, 512, 1, 31). 具体示意图如下,相当于feature sequence长度为31,而每个的通道数为512维。

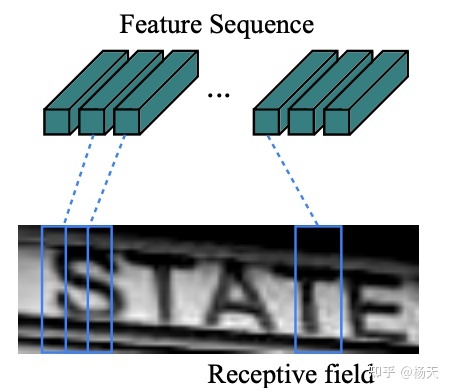
2.3 序列模型
在序列模型中,我们的一个基本假设是处理的文本都是水平单向的。之所以提这一点,是因为后来文字识别领域有一大问题是处理弯曲文本的识别,也就是非水平的文本,而这恰恰是CRNN不熟悉的范围。为什么要加一个序列模型呢,是因为在特征提取层之后,我们得到了一系列的特征向量,这些特征向量代表的都是图片的视觉信息,而其中的语义尚未被挖掘。所以增加序列模型的目的,在于提取其中的语义关联。论文采用的具体序列模型是双向的LSTM,采用双向是因为针对一段文本的某个字符,它不仅跟处于它左边的字符有关联,跟它右边的字符一般也会有一定的联系。论文一共堆叠了两个双向的LSTM,经过序列模型之后,张量的尺寸由(1, 512, 1, 31)变成了(1, 31, 512).其中LSTM隐藏层的维度是256,双向的话就得乘2了,也就是512.具体示意图如下:

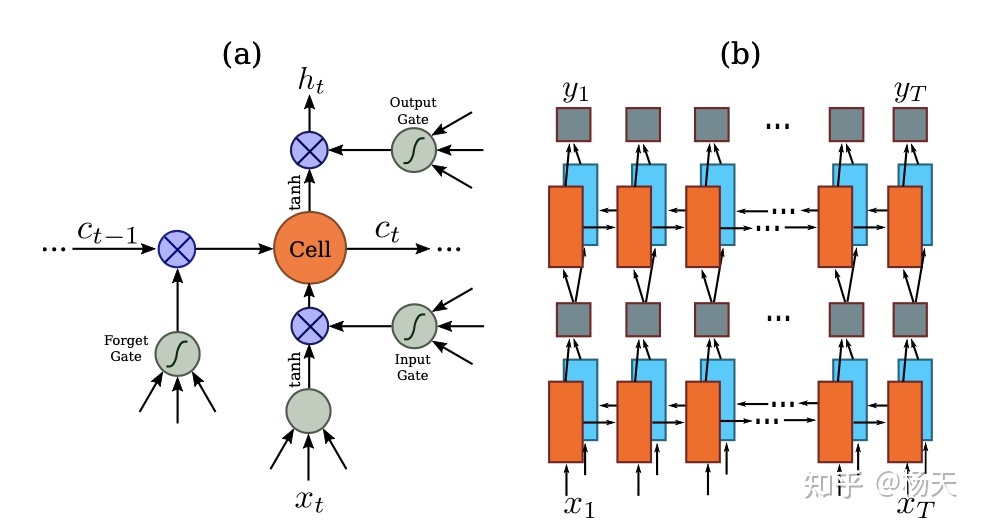
2.4 转译层
转译层是将文字识别转化成序列识别的关键所在。在一般深度学习的网络结构中,输入和输出都是固定的。那么就文字识别来说,按照传统的思路,为了将图片里某个字符的位置和标注的label对齐,我们得标注每个字符在图片中的具体位置。而CTC的提出就是为了解决这个问题的,当采用CTC loss之后,举例来说,我们只用将上述图片里的文本标记成"STATE",而不用标记出"S"具体在图片中的哪个位置。CTC是计算最大概率的搜索路径,具体数学推导可以参考:https://distill.pub/2017/ctc/
3. 代码解读
代码解读同样分成三块,每一块都可以和上面的论文解读进行对照。同时在一些需要注意的地方,我也给出了注释。整体代码参考:https://github.com/chibohe/text_recognition_toolbox/blob/main/networks/CRNN.py
3.1 特征提取层代码
class BackBone(nn.Module):
def __init__(self, inplanes):
super(BackBone, self).__init__()
self.inplanes = inplanes
self.feature_extractor = nn.Sequential(
nn.Conv2d(self.inplanes, 64, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# 第三个maxpooling,注意此处maxpooling的尺寸,可以和论文解读进行对照
nn.MaxPool2d(kernel_size=(2, 1), stride=(2, 1)),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# # 第四个maxpooling,同第三个一样
nn.MaxPool2d(kernel_size=(2, 1), stride=(2, 1)),
nn.Conv2d(512, 512, kernel_size=(2, 2), stride=1, padding=0),
nn.ReLU(inplace=True)
)
def forward(self, inputs):
return self.feature_extractor(inputs)
# 这里一般会有一个Reshape layer,对照于论文中的Map-to-Sequence layer,
# 作用是将张量的高度变成1
class ReshapeLayer(nn.Module):
def __init__(self):
super(ReshapeLayer, self).__init__()
def forward(self, inputs):
B, C, H, W = inputs.size()
inputs = inputs.reshape(B, C, H * W)
inputs = inputs.permute(0, 2, 1)
return inputs3.2 序列模型代码
class SequenceLayer(nn.Module):
def __init__(self, num_inputs, num_hiddens):
super(SequenceLayer, self).__init__()
self.num_inputs = num_inputs
self.num_hiddens = num_hiddens
self.rnn_1 = nn.LSTM(self.num_inputs, self.num_hiddens, bidirectional=True, batch_first=True)
self.rnn_2 = nn.LSTM(self.num_hiddens, self.num_hiddens, bidirectional=True, batch_first=True)
self.linear = nn.Linear(self.num_hiddens * 2, self.num_hiddens)
def forward(self, inputs):
self.rnn_1.flatten_parameters()
recurrent, _ = self.rnn_1(inputs)
inputs = self.linear(recurrent)
self.rnn_2.flatten_parameters()
recurrent, _ = self.rnn_2(inputs)
outputs = self.linear(recurrent)
return outputs3.2 转译层代码
class CTCLoss(nn.Module):
def __init__(self, params, reduction='mean'):
super().__init__()
blank_idx = params.blank_idx
self.loss_func = torch.nn.CTCLoss(blank=blank_idx, reduction=reduction, zero_infinity=True)
def forward(self, pred, args):
batch_size = pred.size(0)
label, label_length = args['targets'], args['targets_lengths']
pred = pred.log_softmax(2)
pred = pred.permute(1, 0, 2)
preds_lengths = torch.tensor([pred.size(0)] * batch_size, dtype=torch.long)
loss = self.loss_func(pred, label.cuda(), preds_lengths.cuda(), label_length.cuda())
return loss
# 最后将上述结构汇总起来
class CRNN(nn.Module):
def __init__(self, flags):
super(CRNN, self).__init__()
self.inplanes = 1 if flags.Global.image_shape[0] == 1 else 3
self.num_inputs = flags.SeqRNN.input_size
self.num_hiddens = flags.SeqRNN.hidden_size
self.converter = CTCLabelConverter(flags)
self.num_classes = self.converter.char_num
self.feature_extractor = BackBone(self.inplanes)
self.reshape_layer = ReshapeLayer()
self.sequence_layer = SequenceLayer(self.num_inputs, self.num_hiddens)
self.linear_layer = nn.Linear(self.num_hiddens, self.num_classes)
def forward(self, inputs):
x = self.feature_extractor(inputs)
x = self.reshape_layer(x)
x = self.sequence_layer(x)
outputs = self.linear_layer(x)
return outputs4. 收尾
经过上述的论文和代码解读,可以看出来,CRNN是一个结构十分清晰的算法。从理论上来讲,算法的每一个组成部分都交代的很清楚。从实现层面来讲,复现起来只用了不到100行代码。另外从实际工作经验上来讲,虽然CRNN提出已经5年有余,但是针对一般文档类的数据,它仍然是最有效的算法之一。所以以它作为整个系列的开篇,是再合适不过的了。下一篇我会沿着CNN+LSTM+CTC的路线,介绍算法GRCNN,敬请期待。