
GAN方法去模糊-DeblurGAN
作者: 晟 沚
生成式对抗网络(GAN)在图像超分辨率重建、in-painting等问题上取得了很好的效果。GAN能够保留图像中丰富的细节、创造出和真实图像十分相近的图像。而在CVPR2017上,一篇由Isola等人提出的《Image-to-Image Translation with Conditional Adversarial Networks》的论文更是使用条件生成式对抗网络(cGAN)开启了“image-to-image translation”任务的大门。
论文主要贡献
提出使用DeblurGAN对模糊图像去模糊,网络结构基于cGAN和“content loss”。获得了目前最佳的去模糊效果
将去模糊算法运用到了目标检测上,当待检测图像是模糊的的时候,先对图像去模糊能提高目标检测的准确率
提出了一个新的合成模糊图像的方法
网络结构
给出一张模糊的图像 ,我们希望重建出清晰的图像 。为此,作者构建了一个生成式对抗网络,训练了一个CNN作为生成器 和一个判别网络 。
整体结构如下图:

生成器CNN的结构如下图,类似于自编码器(auto-encoder):

网络结构类似Johnson在风格迁移任务中提出的网络。作者添加了“ResOut”,即“global skip connection”。CNN学习的是残差,即
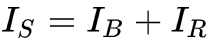
,这种方式使得训练更快、模型泛化能力更强。
判别器的网络结构与PatchGAN相同(即 image-to-image translation 论文中采用的判别网络)。
损失函数
损失函数使用的是“contentloss”和“adversarial loss”之和:

Adversarialloss
训练原始的GAN(vanilla GAN)很容易遇到梯度消失、mode collapse等问题,训练起来十分棘手。后来提出的“Wassertein GAN”(WGAN)使用“Wassertein-1”距离,使训练不那么困难。之后Gulrajani等提出的添加“gradient penalty”项,又进一步提高了训练的稳定性。WGAN-GP实现了在多种GAN结构上稳定训练,且几乎不需要调整超参数。本文使用的就是WGAN-GP,adversarial loss的计算式为:
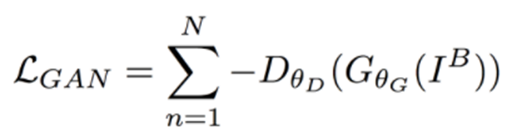
Content loss
内容损失,也就是评估生成的清晰图像和ground truth之间的差距。两个常用的选择是L1(也称为MAE,mean absolute error)损失,和L2(也称为MSE)损失。最近提出了“perceptualloss”,它本质上就是一个L2 loss,但它计算的是CNN生成的feature map和ground truth的feature map之间的距离。定义如下:

其中,  表示将图像输入VGG19(在ImageNet上预训练的)后在第i个max pooling层前,第j个卷积层(after activation)输出的feature map。
表示将图像输入VGG19(在ImageNet上预训练的)后在第i个max pooling层前,第j个卷积层(after activation)输出的feature map。 表示featuremap的维度。
表示featuremap的维度。
训练过程
Motion blurgeneration
相比其他的image-to-image translation任务,例如超分辨率和风格化,去模糊问题很难获得清晰-模糊的图像对用于训练。一种常见的办法是使用高速摄像头拍摄视频,从视频帧中获得清晰图像、合成模糊图像。另一种方法就是用清晰图像卷积上各式各样的“blur kernel”,获得合成的模糊图像。作者在现有第二种方法的基础上进一步拓展,提出的方法能够模拟更复杂的“blur kernel”。
首先,作者采用了Boracchi和Foi[1]提出的运动轨迹随机生成方法(用马尔科夫随机过程生成);然后对轨迹进行“sub-pixel interpolation”生成blur kernel。当然,这种方法也只能在二维平面空间中生成轨迹,并不能模拟真实空间中6D相机的运动。
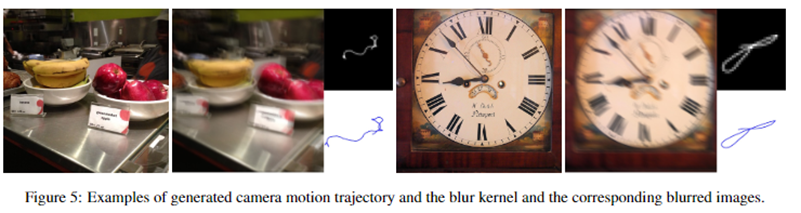
作者也给出了生成模糊影像算法的伪代码

Training Details
DeblurGAN的代码在很大程度上借鉴了pix2pix的代码,使用的框架是pyTorch。作者一共在不同数据集上训练了三个model,分别是:
1. DeblurGAN WILD :训练数据是GOPRO数据集,将其中的图像随机裁剪成256×256的patches输入网络训练
2. DeblurGAN Synth:训练数据集是MSCOCO生成的模糊图像(根据上面提到的方法),同样随机裁剪成256×256的patches
3. DeblurGAN Comb:在以上两个数据集的混合数据集上训练,合成图像:GOPRO=2:1
所有模型训练时的batch size都为1。作者在单张Titan-X GPU上训练,每个模型需要6天的训练时间。
由于它们均为全卷积模型,又是在图像patch上训练的,因此可以应用在任意大小的图像中。
为了进行优化,研究人员在D上执行了5次梯度下降,在G上执行了1次。最初生成器和判别器设置的学习速率为10-4,经过150次迭代后,在接下来的有一轮150次迭代中将这个比率线性衰减。
实验结果

上图是DeblurGAN和Nah等人提出的 Deep Multi-scale ConvolutionalNeural Network for Dynamic Scene Deblurring 方法的结果对比。左侧一列是输入的模糊图像,中间是Nah等人的结果,右侧是DeblurGAN的结果。PSNR、SSIM两项指标的评估结果可以参见下表。

Kohler标准数据集
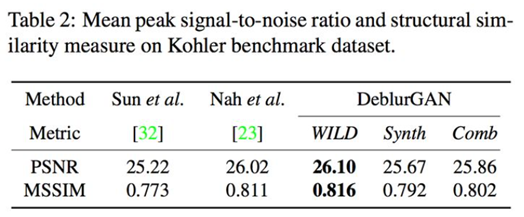
测试结果表明,DeblurGAN在定性和定量两方面都表现出优异的结果。它可以处理由相机抖动和物体运动引起的模糊,不会受到通常的核评估方法的影响,同时参数仅为Multi-scale CNN的六分之一,大大加快了推理速度。
另外,作者将这项技术用在目标检测上,探索了动态模糊对目标检测的影响,基于在预训练的YOLO网络上目标检测的结果,提出一种评估质量的去模糊算法的新方式。
通过用高帧率摄像机模拟相机抖动,研究人员构建了一个清晰-模糊的街景数据集。之后,对240fps(每秒显示帧数-帧率)相机拍摄的5到25帧进行随机抽样,并计算中间帧的模糊版作为这些帧的平均值。
总体来说,数据集包括410对模糊-清晰图像,这些图像是从不同街道和停车场拍摄的,包含不同数量和类型的汽车。
然后将清晰的图像输入 YOLO 网络,并将视觉验证后的结果指定为真实情况。然后在图像的模糊和恢复版本上运行 YOLO,并计算获得的结果与gt之间的平均召回率和精度。与标准PSNR 度量相比,这种方法对应于现实生活问题上的去模糊模型的质量,并与生成图像的视觉质量和清晰度相关。一般来说,模糊图像的精度更高,因为没有清晰的对象边界,并且没有检测到较小的对象,如下图所示。

在模糊化前后的目标检测
在recall和F1 socre上,DeblurGAN的表现远远超过了竞争对手。

end
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助