
MySql中当in或or参数过多时导致索引失效
今天的文章很短只讲一件事情,但发现很多同学还不知道,以至于引发一些数据库使用层面的慢查询、访问超时问题。
mysql有个阈值,决定了阈值之下使用索引查询,而超过阈值则退化,优化器选择索引下潜,进而引起iops过高或者慢查询问题,导致超时。
大家一定要记着:MySQL优化器决定使用某个索引执行查询的仅仅是因为:使用该索引时的成本足够低。也就是说即使我们有下边的语句:
SELECT * FROM t WHERE key1 IN ('b', 'c');MySQL优化器需要去分析一下如果使用二级索引idx_key1执行查询的话,键值在['b', 'b']和['c', 'c']这两个范围区间的记录共有多少条,然后通过一定方式计算出成本,与全表扫描的成本相对比,选取成本更低的那种方式执行查询。
MySQL优化器针对IN子句对应的范围区间的多少而指定了不同的策略:
如果IN子句对应的范围区间比较少,那么将率先去访问一下存储引擎,看一下每个范围区间中的记录有多少条(如果范围区间的记录比较少,那么统计结果就是精确的,反之会采用一定的手段计算一个模糊的值,当然算法也比较麻烦),这种在查询真正执行前优化器就率先访问索引来计算需要扫描的索引记录数量的方式称之为index dive。
如果IN子句对应的范围区间比较多,这样就不能采用index dive的方式去真正的访问二级索引idx_key1(因为那将耗费大量的时间),而是需要采用之前在背地里产生的一些统计数据去估算匹配的二级索引记录有多少条(很显然根据统计数据去估算记录条数比index dive的方式精确性差了很多)。
那什么时候采用index dive的统计方式,什么时候采用index statistic的统计方式呢?
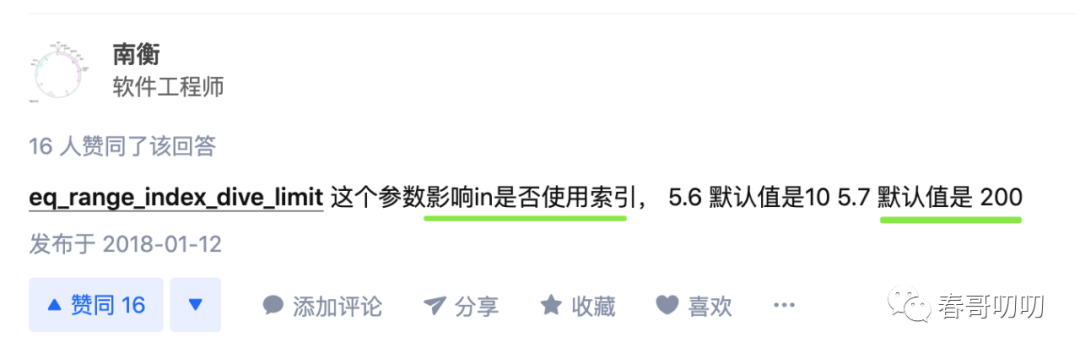
这就取决于我们要说的系统变量eq_range_index_dive_limit的值了。
这个值在5.6版本默认是10,5.7版本默认是200,如下图:
ep_range_index_dive_limit参数提供一个阈值,优化器在预估扫描行数时,会根据这个参数,来进行预估策略。通常优化器有两种预估策略:索引统计和索引下潜。
1、当低于eq_range_index_dive_limit参数阀值时,采用index dive方式预估影响行数,该方式优点是相对准确,但不适合对大量值进行快速预估。2、当大于或等于eq_range_index_dive_limit参数阀值时,采用index statistics方式预估影响行数,该方式优点是计算预估值的方式简单,可以快速获得预估数据,但相对偏差较大。
在eq_range_index_dive_limit设置过小且索引分布极不均匀的情况下,MySQL可能会由于成本计算误差太大,导致选择错误的执行计划这一灾难性后果!
简单理解:
参数超过阈值,会导致索引退化,索引失效。此规则适用于in、or:
col_name IN(val1, …, valN)col_name = val1 OR … OR col_name = valN
怎么解决呢?
简单来说,就是我们需要控制in、or语句中的参数个数,阈值是200,但是我们代码更倾向于控制在50内,也就是说我们需要有机制识别与控制(cr方式、组件拦截方式、编码规范等)避免类似的风险被触发,而不是完全无视,极致一些,只要是in场景,就需要加limit限制。
希望对你有用。