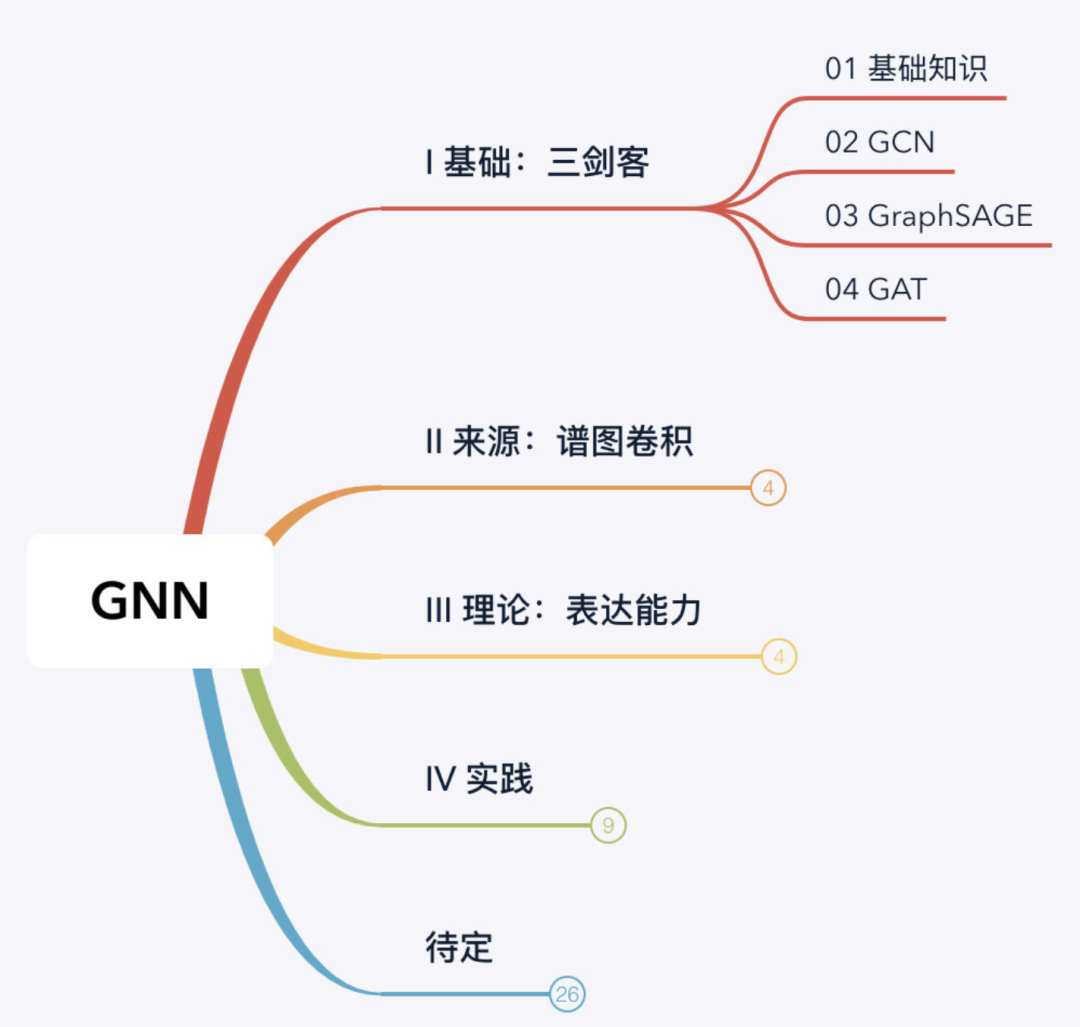
【GNN教程】图神经网络“开山之作”!
引言
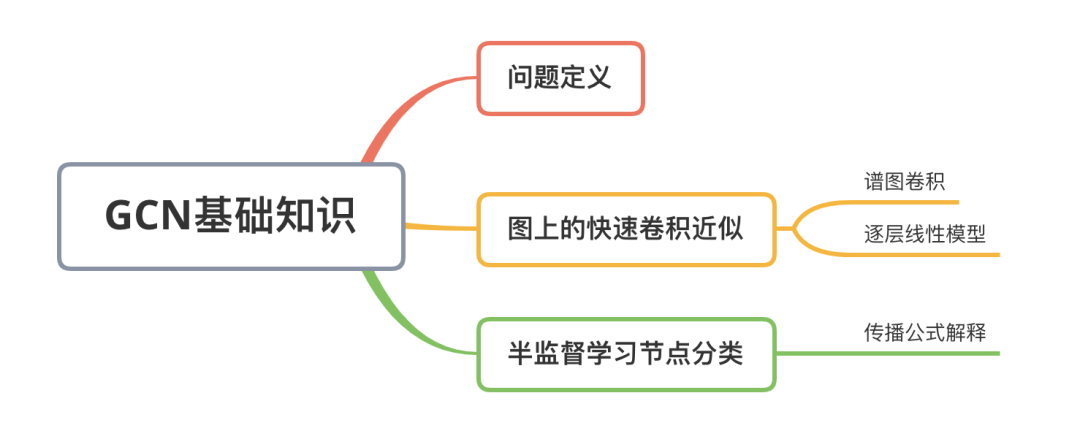
1. 问题定义
2. 图上的快速卷积近似
谱图卷积
逐层线性模型
3. 半监督学习节点分类
传播公式解释
后话
参考文献
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码:
评论

往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: