
你不得不关注的 Elasticsearch Top X 关键指标
0、题记
在写繁重的业务场景下,你是否遇到过 Elasticsearch 集群的性能问题? 你是否遇到过 Elasticsearch 数据索引化速度限制问题? 你是否遇到过搜索花费时间太长而无法执行的延迟问题? 你是否遭遇过 Elasticsearch 集群故障排查的挑战? 你是否努力尝试在零停机情况下提高 Elasticsearch 集群的稳定性? 你是否想过从监控的角度去看Elasticsearch 关键指标?
如果你对以上任何一个问题的回答为“是”,那么本文适合你。
我将介绍一些有关故障排除和解决 Elasticsearch 性能问题的经验。
到本文结尾,你应该对关键指标有一个很好的了解,以便在你遇到Elasticsearch集群的性能或操作问题时进行监视。
那么,要监视 Elasticsearch Top X 指标是什么呢?本文揭晓答案。
1、集群配置
Elasticsearch 是一个分布式搜索引擎,可实现快速的数据索引化并具备良好的搜索性能。
开箱即用的 Elasticsearch 配置可以满足N多业务场景。但是,如果你想获得最佳性能,那么了解索引以及搜索要求并确保集群配置符合Elasticsearch最佳实践至关重要。
Elasticsearch是按业务规模构建的,具有最佳配置可确保更好的集群性能。Elasticsearch 集群可拆解为各种可度量的元素,可以将节点视为运行 Elasticsearch 进程的机器。索引本身可以被视为一个完整的搜索引擎,由一个或多个分片组成。可以将一个分片可视化为 Apache Lucene 的单个实例,该实例保存用于索引和搜索的文档,并且这些文档在各个分片之间均匀分布。

图为:一个三节点集群,其索引分为六个分片
分片可以提高摄取(ingest)和搜索性能,但是分片过多也会降低速度。适当的分片策略对于集群至关重要。建议单个分片大小设置在 30-50 GB 之间。
分片数高于节点数可便于扩展集群。但是分片的过度分配可能会减慢搜索操作,是因为搜索首先在 query 阶段请求需要命中索引中的每个分片,然后执行 fetch 阶段获取并汇聚结果。
如果你的分片仅容纳了 5 GB数据,则可以认为未充分利用。
咱们之前 N 多文章都提过,一个简单的查看集群整体健康状态的 API 如下:
GET _cluster/health
返回结果如下:
{
"cluster_name" : "my-application",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 11,
"active_shards" : 11,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 68.75
}
开发人员经常问到的一个问题是:“集群应该配置的最佳分片数是多少?以使得整个集群性能最优。”我要说的是,这个问题没有一个千篇一律的答案。这取决于你的业务要求和你要满足的SLA(网站服务可用性的保证)。
如下多项统计信息将帮助你做出正确的容量规划决策,包含但不限于:
需要每秒索引的文档数 单文档大小 每秒查询数 数据集的增长模式
使用少量数据进行基准性能测试可以帮助你做出正确的决定(划重点)。
强烈建议你了解您的数据和索引、搜索要求,以创建一个平衡且高效的集群。
2、总可用存储空间大小
如果你的 Elasticsearch 集群节点的磁盘空间不足,则会影响集群性能。
一旦可用存储空间低于特定阈值限制,它将开始阻止写入操作,进而影响数据进入集群。
不少同学可能会遇到过如下的错误:
ElasticsearchStatusException[Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only / allow
这就是磁盘快满了做的保护机制提示。
再次强调一下,磁盘的三个默认警戒水位线。
低警戒水位线
cluster.routing.allocation.disk.watermark.low
默认为磁盘容量的85%。Elasticsearch不会将新的分片分配给磁盘使用率超过85%的节点。它也可以设置为绝对字节值(如500mb),以防止 Elasticsearch 在小于指定的可用空间量时分配分片。此设置不会影响新创建的索引的主分片,特别是之前从未分配过的分片。
高警戒水位线
cluster.routing.allocation.disk.watermark.high
默认为磁盘容量的90%。Elasticsearch 将尝试对磁盘使用率超过90%的节点重新分配分片(将当前节点的数据转移到其他节点)。它也可以设置为绝对字节值,以便在节点小于指定的可用空间量时将其从节点重新分配。此设置会影响所有分片的分配,无论先前是否分配。
洪水警戒水位线
cluster.routing.allocation.disk.watermark.flood_stage
默认为磁盘容量的95%。Elasticsearch对每个索引强制执行只读索引块(index.blocks.read_only_allow_delete)。这是防止节点耗尽磁盘空间的最后手段。只读模式待磁盘空间充裕后,需要人工解除。
因此,监视集群中的可用存储空间至关重要。
3、已删除的文档
Elasticsearch中的文档无法修改,并且是不可变的(immutable)。Elasticsearch 执行的删除或更新文档操作会先将文档标记为已删除(逻辑删除),不会立即将其从Elasticsearch中物理删除。当你继续索引更多数据时,这些文档将在后台被清理。已逻辑删除的文档在搜索操作期间不可见,但是它们继续占用磁盘空间。
如果磁盘空间成为瓶颈,则可以强制执行段合并操作。段合并会实现小段合并为大段并清理已删除的文档。
POST my_index/_forcemerge
如果通过 reindex 将文档重新索引为新索引,则可以执行删除旧索引操作(delete index),删除索引的方式会直接物理删除掉文档。
如果你的索引会定期更新,则待删除的文档数量会很多。
因此,最好在磁盘空间出现瓶颈问题前制定适当的策略来清理已逻辑删除的文档。
4、主节点指标
在生产环境中,建议你在Elasticsearch集群中配置专用的主节点。
主节点通过监视集群管理活动(例如:跟踪集群中的所有节点、索引和分片)来提高集群的稳定性。
主节点还监视集群的运行状况,以确保数据节点不会过载,并使集群具有容错能力。
另一个建议是:针对集群规模大的场景,建议至少有三个主节点。这样可确保在发生故障事件期间,必要的仲裁已到位,可以在集群中选择新的主节点。
你可以通过查看主节点的CPU / 内存利用率和 JVM 内存使用百分比来确定主节点实例的配置。
以下是:cerebro 监控 截图。
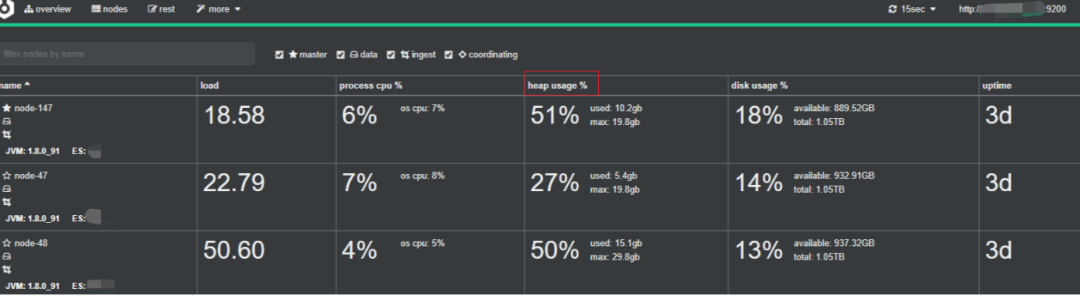
一般来说,由于主节点专注于集群状态,因此通常需要具有较低CPU /内存资源的计算机。
5、数据节点指标
数据节点托管 Elasticsearch 集群中包含索引文档的分片。数据节点还执行搜索和聚合有关的所有数据操作,并处理客户端请求。
与主节点相比,数据节点需要具有较高CPU / 内存资源的服务器。
如果你的集群没有专用的主节点,则其中一个数据节点将开始充当主节点。这会在集群中造成CPU和JVM使用的不平衡。
文档增、删、改、查操作和搜索操作占用大量CPU和IO,因此监视数据节点利用率指标很重要。
从CPU /内存的角度来看,您应确保数据节点平衡且不会过载。
6、数据写入性能指标
如果您试图将大量文档写入 Elasticsearch 中,则可以监视数据写入延迟和数据索引化速率指标,以验证索引吞吐量是否满足企业的需求。
有几种方法可以提高数据写入速度。可概括为如下四项措施:
6.1 bulk 批量操作或者多线程写入
利用 Elasticsearch 提供的批量API(bulk)来同时索引一批文档。还可以使用多线程写入 Elasticsearch 以最大化利用所有集群资源。
请注意,文档大小和集群配置可能会影响数据写入速度。为了找到集群的最佳吞吐量,你需要运行性能测试并尝试使用不同的批处理大小和并发线程值大小。
6.2 合理调整刷新频率
Elasticsearch refresh 刷新操作是使文档可搜索的过程。
默认情况下,每秒刷新一次。如果主要目标是调整摄取速度的索引,则可以将 Elasticsearch 的默认刷新间隔从1秒更改为30秒。30秒后,这将使文档可见以供搜索,从而优化索引速度。
更新指定索引的刷新频率,实现如下:
PUT my_index/_settings
{
"index": {
"refresh_interval": "30s"
}
}
在写入繁重的业务场景或索引速度比搜索性能更关键的业务场景下,这可能是一个很好的实践。
6.3 写入前后动态调整副本大小
副本能提升集群的高可用并且作为主分片数据的备份能一定程度防止数据丢失,但带来了相应的成本。
在初始数据加载期间,你可以禁用副本以实现较高的索引写入速度。
PUT my_index/_settings
{
"index": {
"number_of_replicas": 0
}
}
为保证集群高可用,一旦完成初始加载,就可以重新启用副本。
6.4 合理的数据建模
不要索引业务层面不需搜索的字段。可通过不索引冗余字段来节省存储空间(举例:设置 index:false)。
如下示例,可以将 cont 字段的 index 属性值设置为 false,这样,cont 字段将不会被搜索。
PUT blog_index
{
"mappings": {
"properties": {
"cont": {
"type": "text",
"index": false
}
}
}
}
如果执意要检索 cont 字段上的数据,会报错并返回如下内容:
"reason": "Cannot search on field [cont] since it is not indexed."
一图胜千言,建模的时候仔细过一遍如下这张图。
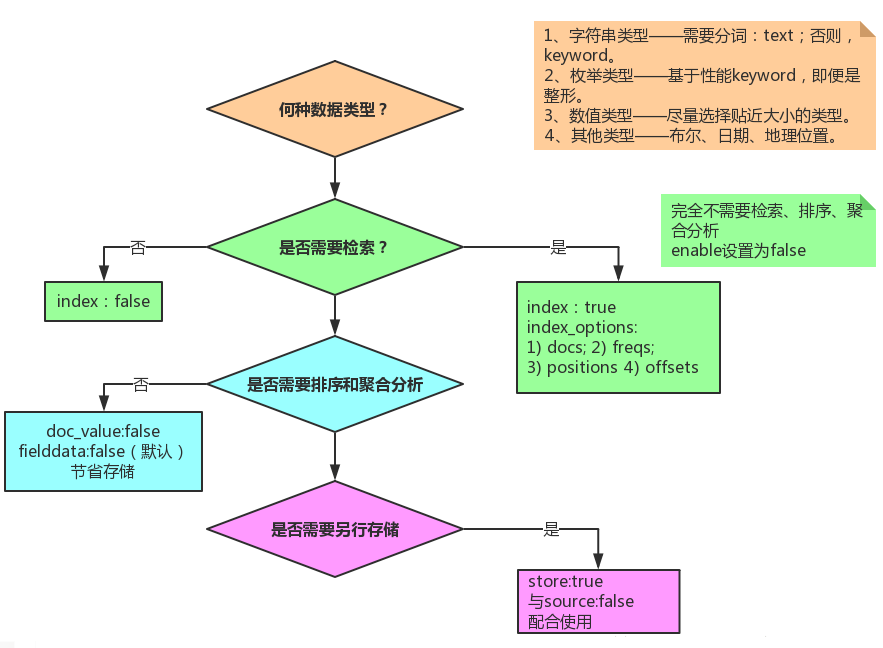
因此,强烈建议你根据实际业务场景,以最小化存储、最大化集群写入和搜索性能为前提对数据进行合理的建模、合理的设置 Mapping 中的各个字段的类型。
推荐:
7、数据搜索性能指标
Elasticsearch 中的搜索请求将发送到索引中的所有分片(主分片或副本分片)。然后,接收到该请求的节点将汇集所有分片的结果,并将结果返回给调用的应用程序。
分片会消耗 CPU / 内存资源。因此,如果分片过多,则可能降低查询性能。
如果集群的更新操作频繁,则可能会影响搜索 SLA。通过适当地配置和水平扩展集群,可以提升数据写入和集群检索性能。
7.1 使用过滤限定返回文档数量
根据我搜索性能调优的经验,强烈建议你通过添加适当的过滤器(filters)来限制从搜索查询中返回的文档数量。应用过滤器后,仅针对有限的一组文档计算分数,这将提高查询性能。
你还应该监视搜索延迟和搜索速率指标,以调查与搜索功能相关的性能问题。
这里说的核心是:不要动不动就返回全量数据,而是发挥倒排索引和搜索的优势,根据业务场景最小化返回满足给定条件的数据。
7.2 启用慢查询日志
建议你在 Elasticsearch 集群中启用慢速查询日志,以解决性能问题并捕获运行时间较长或超过设置阈值的查询。
例如,如果您的搜索SLA为 2 秒,则可以按以下方式配置搜索查询,超过该阈值的任何查询都将被记录。
PUT my_index/_settings
{
"index.search.slowlog.threshold.query.warn" : "2s"
}
8、小结
在本文中,介绍了一些从搜索和索引角度优化 Elasticsearch 性能的最关键的指标。总结一下,关键要点如下:
集群中具有专用的主节点和数据节点,以确保最佳的集群性能。 通过在集群中添加数据节点并增加副本分片数量来提升集群的高可用性。 搜索查询必须命中每个分片(主分片或者副本分片),因此分片过多会使搜索变慢。 慢查询和索引日志可用来解决搜索和索引性能问题。 确保你的Elasticsearch集群在分片、数据节点和主节点的数量上合理性和正确性。 通过利用批量请求、使用多线程写入并水平扩展集群来优化 Elasticsearch 索引性能。
注:这是一篇翻译文章,原文地址:
https://iamondemand.com/blog/top-5-elasticsearch-metrics-to-monitor/
我结合业务实践进行了扩充和完善。
推荐阅读
更短时间更快习得更多干货!
中国 40%+ Elastic 认证工程师出自于此!
和全球 800+ Elastic 爱好者一起死磕 Elasticsearch!