
HashMap 为什么不能一边遍历一遍删除
点击关注公众号,Java干货及时送达
foreach 循环?
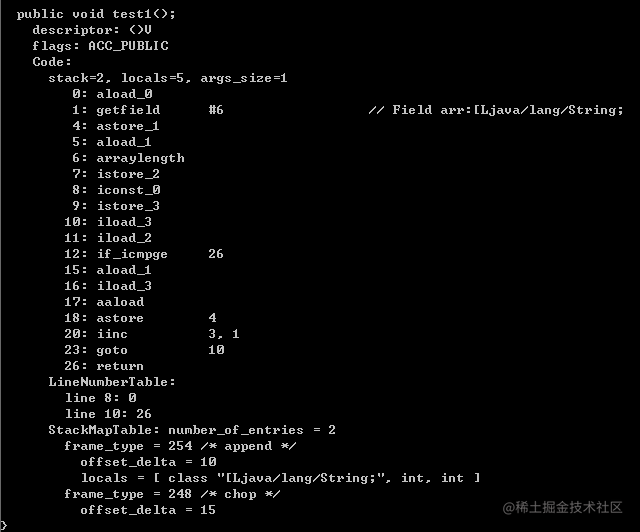
public class HashMapIteratorDemo {String[] arr = {"aa","bb","cc"};public void test1() {for (String str: arr) {}}}
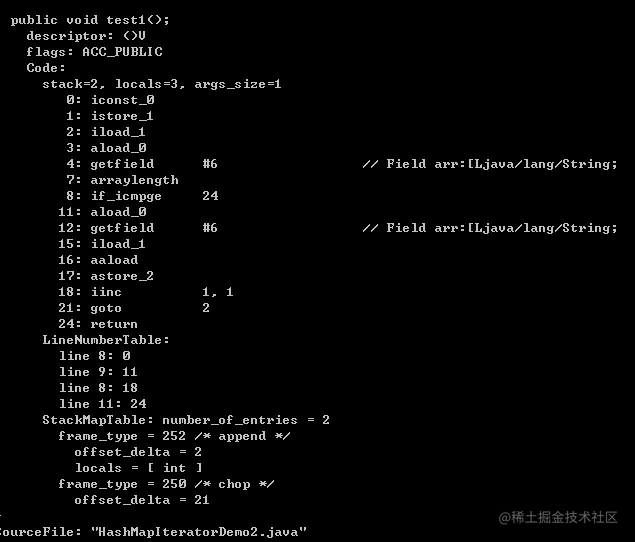
public class HashMapIteratorDemo2 {String[] arr = {"aa","bb","cc"};public void test1() {for (int i = 0; i < arr.length; i++) {String str = arr[i];}}}
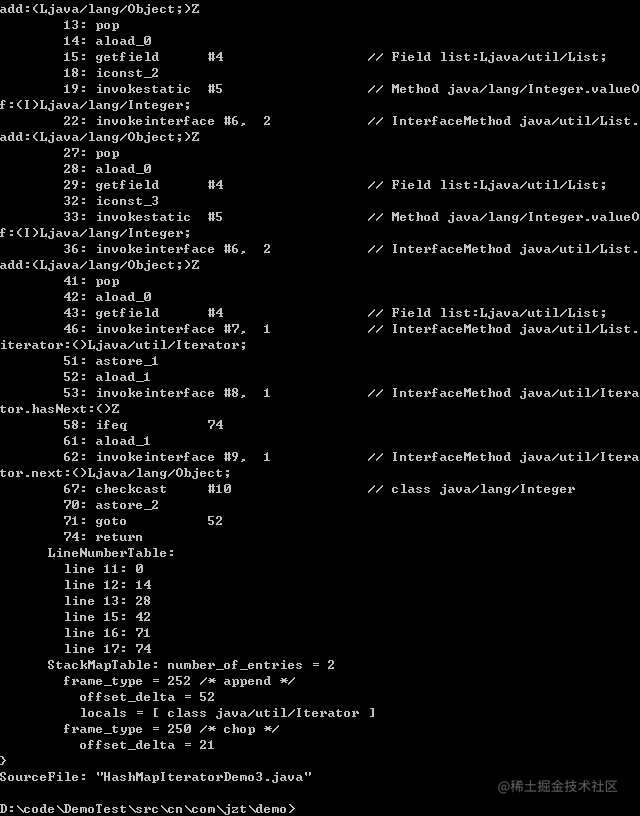
public class HashMapIteratorDemo3 {List < Integer > list = new ArrayList < > ();public void test1() {list.add(1);list.add(2);list.add(3);for (Integervar: list) {}}}
public class HashMapIteratorDemo4 {List < Integer > list = new ArrayList < > ();public void test1() {list.add(1);list.add(2);list.add(3);Iterator < Integer > it = list.iterator();while (it.hasNext()) {Integervar = it.next();}}}
HashMap 遍历集合并对集合元素进行 remove、put、add
1、现象
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();String v = entry.getValue();System.out.println(k + " = " + v);}}}

public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();if (k == 1) {map.put(1, "AA");}String v = entry.getValue();System.out.println(k + " = " + v);}}}


public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();if (k == 1) {map.put(4, "AA");}String v = entry.getValue();System.out.println(k + " = " + v);}}}

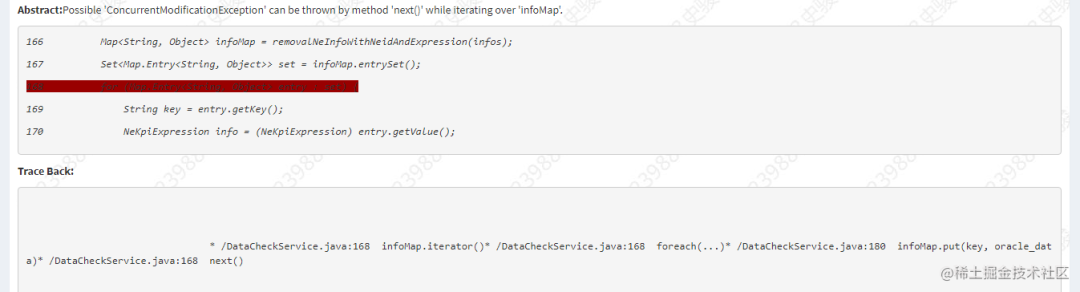
这就是验证了上面说的 put 操作可能会抛出 java.util.ConcurrentModificationException 异常。
但是有疑问了,我们上面说过 foreach 循环就是通过迭代器进行的遍历啊?为什么到这里是不可以了呢?
这里其实很简单,原因是我们的遍历操作底层确实是通过迭代器进行的,但是我们的 remove 等操作是通过直接操作 map 进行的,如上例子:map.put(4, "AA"); //这里实际还是直接对集合进行的操作,而不是通过迭代器进行操作。所以依然会存在 ConcurrentModificationException 异常问题。
2、细究底层原理
final Node < K, V > nextNode() {Node < K, V > [] t;Node < K, V > e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();if ((next = (current = e).next) == null && (t = table) != null) {do {} while (index < t.length && (next = t[index++]) == null);}return e;}
public V remove(Object key) {Node < K, V > e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}
public final boolean remove(Object key) {return removeNode(hash(key), key, null, false, true) != null;}
public final boolean remove(Object o) {if (o instanceof Map.Entry) {Map.Entry << ? , ? > e = (Map.Entry << ? , ? > ) o;Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}
public final void remove() {Node < K, V > p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount; //--这里将expectedModCount 与modCount进行同步}
final Node < K, V > removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node < K, V > [] tab;Node < K, V > p;int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&...if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode < K, V > ) node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount; //----这里对modCount进行了自增,可能会导致后面与expectedModCount不一致--size;afterNodeRemoval(node);return node;}}return null;}
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");Iterator < Map.Entry < Integer, String >> it = map.entrySet().iterator();while (it.hasNext()) {Map.Entry < Integer, String > entry = it.next();int key = entry.getKey();if (key == 1) {it.remove();}}}}
转自:你呀不牛, 链接:juejin.cn/post/7114669787870920734
往 期 推 荐
4、为什么国外JetBrains做 IDE 就可以养活自己,国内不行?区别在哪?
点分享
点收藏
点点赞
点在看





评论