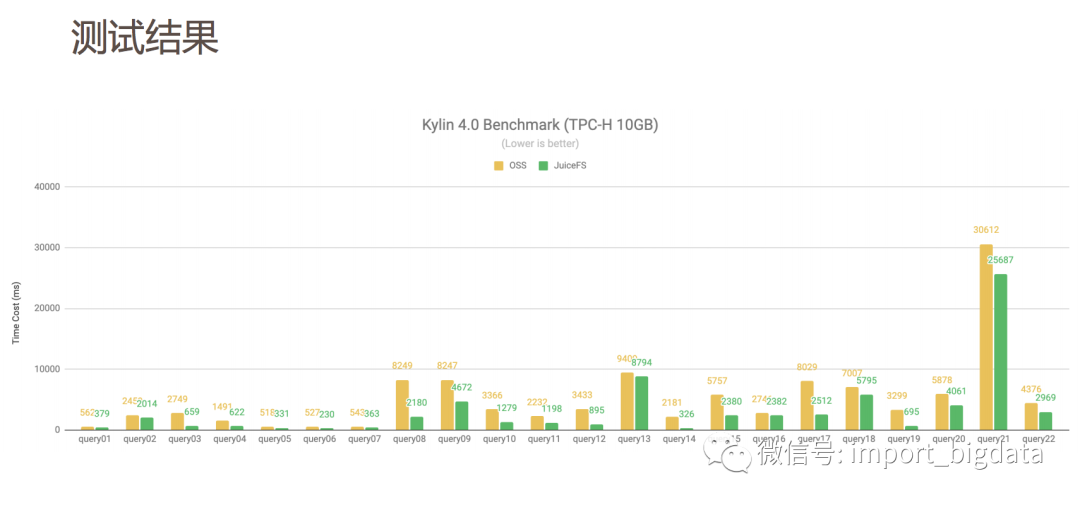
使用JuiceFS优化 Kylin4.0的存储性能

云端:采用云服务中的对象存储作为后端,综合性价比极高。
共享:上千台机器同时挂载,高性能并发读写,共享数据。
易用:POSIX、HDFS、NFS 兼容,无门槛对接现有应用。
JuiceFS 核心特性
POSIX 兼容:像本地文件系统一样使用,无缝对接已有应用,无业务侵入性;
HDFS 兼容:完整兼容 HDFS API,并提供更强的元数据性能,云上 Hadoop 数据存储的理想选择;
强一致性:所有确认的修改会立即在所有客户端可见,保证强一致性;
卓越的性能:低至几毫秒的时延和无限的吞吐量(通过增加客户端数量);
高可用性:元数据集群通过 Raft 协议实现高可用;
可扩展:为几十 PB 级数据和几亿级文件数设计,平滑扩容,无运维干预;
跨云跨区的复制:数据可以像 RAID-1 一样自动复制到不同区甚至不同云平台;
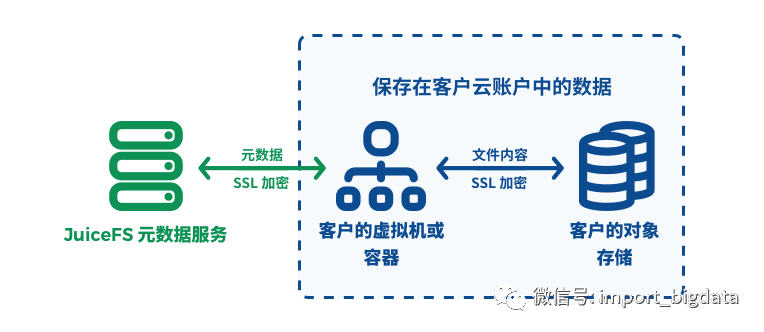
数据安全:所有文件数据保存在您自己的对象存储中,我们接触不到您的数据,传输过程中也是加密的。
高性价比:所有数据存储于对象存储,并经过特殊设计和压缩,大幅降低 TCO。
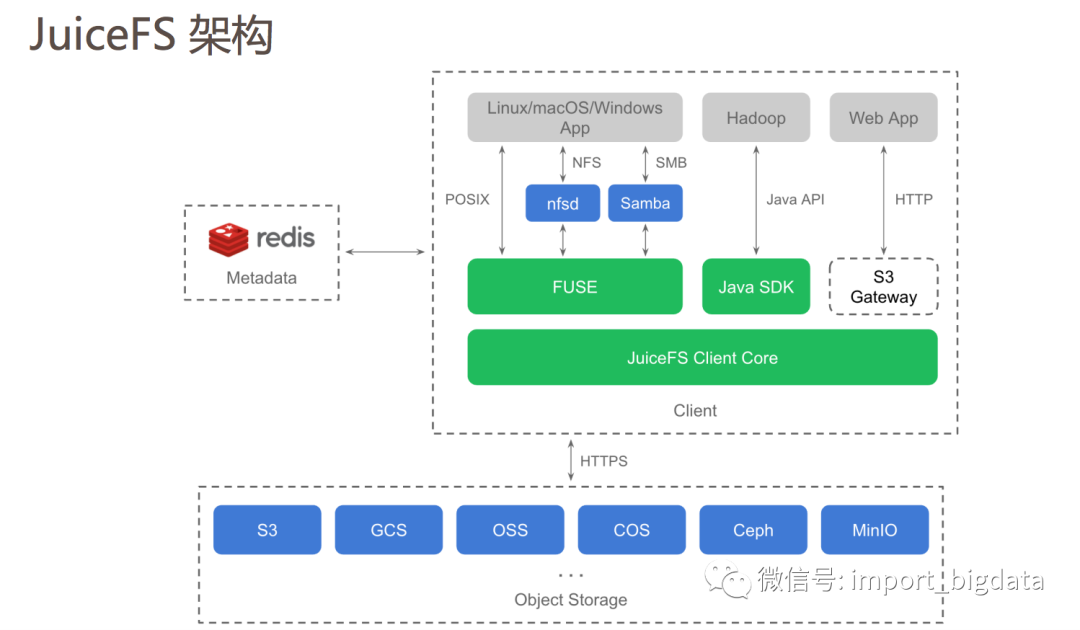
JuiceFS 主体架构
JuiceFS 元数据(Metadata)服务:元数据服务是由我们负责运维的一个集群,它们通过 Raft 算法实现高可用并同时保证数据的强一致性。元数据服务是专为文件系统优化的服务,非常高效和稳定。
JuiceFS 挂载客户端:即下图的
jfsmount, 它负责跟元数据服务和对象存储通信,并通过 FUSE 实现 POSIX API。另外,我们还提供一个脚本juicefs, 用于 JuiceFS 的授权、挂载等所有操作。
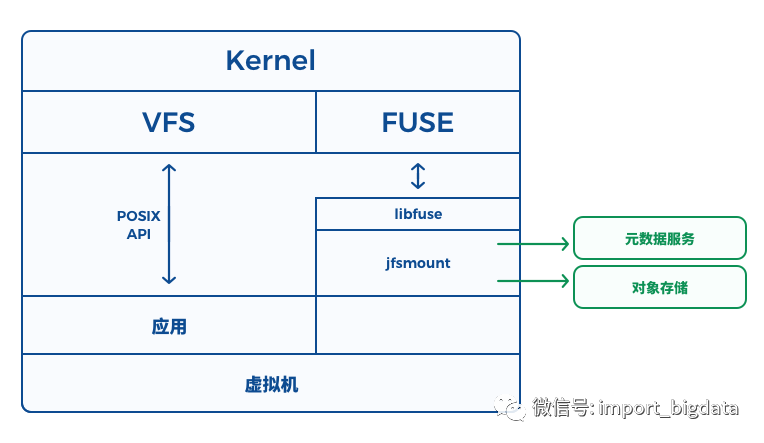
jfsmount, 再请求元数据服务或者对象存储完成操作。JuiceFS 使用场景
大数据分析:HDFS 兼容,没有任何特殊 API 侵入业务;与主流计算框架(Spark, Hadoop, Hive等)无缝衔接;无限扩展的存储空间;运维成本几乎为 0;完善的缓存机制,高于对象存储性能数倍。
机器学习:POSIX 兼容,可以支持所有机器学习、深度学习框架;共享能力提升团队管理、使用数据效率。
容器集群中的持久卷:Kubernetes CSI 支持;持久存储并与容器生存期独立;强一致性保证数据正确;接管数据存储需求,保证服务的无状态化。
共享工作区:没有 VPC 限制,可以在任意主机挂载;没有客户端并发读写限制;POSIX 兼容已有的数据流和脚本操作。
数据备份:POSIX 是运维工程师最友好的接口;无限平滑扩展的存储空间;跨云跨区自动复制;挂载不受 VPC 限制,方便所有主机访问;快照(snapshot)可用于快速恢复和数据验证。